
Last month, Adept AI announced the release of Adept Fuyu-Heavy, a new multimodal model designed specifically for digital agents. Multimodal AI systems combine multiple modes of data like text, images, and speech to perceive the world and make decisions similarly to humans. Adept claims Fuyu-Heavy is the world’s third most capable multimodal model. This is a notable achievement considering it's competing with models like GPT4-V and Gemini Ultra, which are 10-20 times bigger.
Fuyu-Heavy achieves state-of-the-art performance on benchmarks measuring multimodal reasoning, even outscoring Gemini Pro on the MMMU benchmark. Impressively, Fuyu-Heavy accomplishes this while matching or exceeding other models of comparable size on traditional natural language tasks.
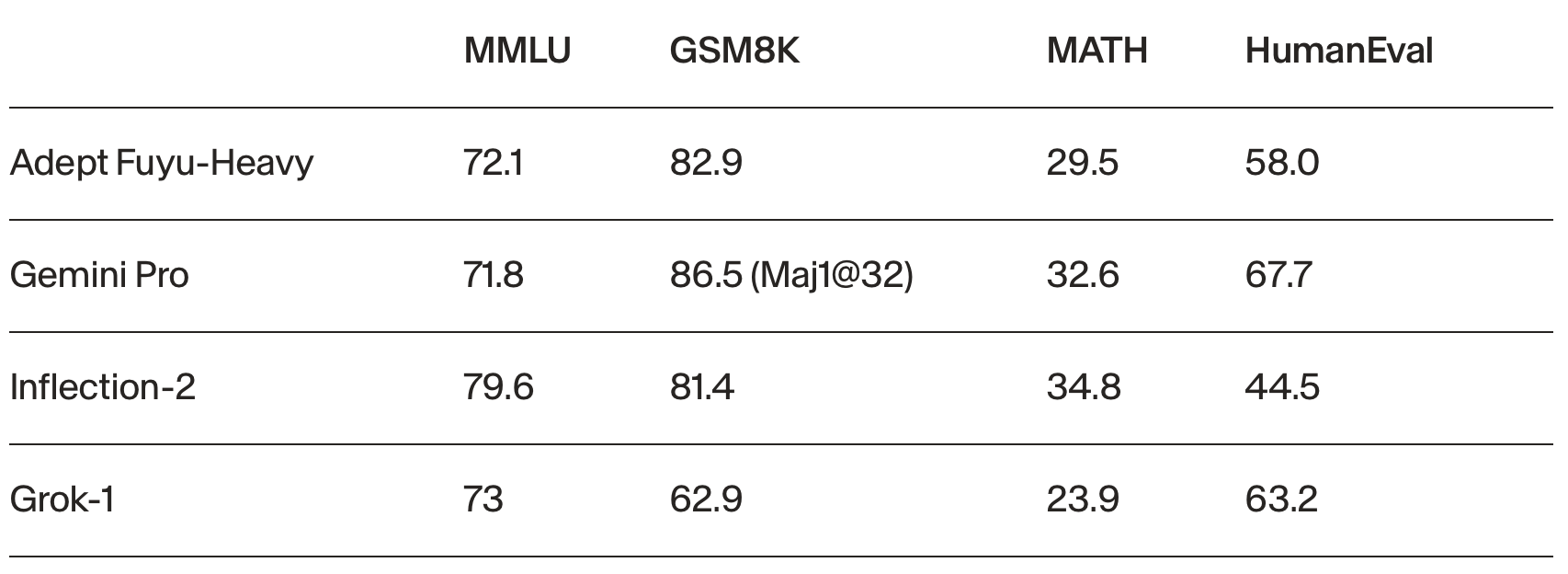
But raw benchmark results only tell part of the story. Adept highlights Fuyu-Heavy's talent for user interface understanding as a "killer feature" that distinguishes the model. For digital assistants, reliably perceiving and interacting with complex UI elements could enable more seamless human-computer collaboration. Fuyu-Heavy also exhibits coherent, human-like dialogue for long-form conversations. Sample interactions released by Adept indicate the model can integrate both textual and visual information to answer questions, perform calculations, and solve problems.
Fuyu-Heavy builds upon their Fuyu-8B model first introduced last year. Fuyu models are trained with both text and image data from the start rather than retrofitting a language model for multimodality. However, scaling up introduced stability challenges well-known to plague image models. By carefully tuning the training procedure, Adept was able to stabilize Fuyu-Heavy without sacrificing performance. Custom strategies for collecting and generating training data also played a key role.
Adept notes that converting base models into specialized agents remains critical work. This involves further tuning using reinforcement learning and self-play. Adept also emphasizes the need to connect these models to real-world environments. Building the feedback loops for agents to learn from experience is integral for producing reliable, assistive AI.
Adept Fuyu-Heavy provides tangible evidence that multimodal models are reaching new heights in practical functionality. As researchers continue honing these models' decision-making, perceptual abilities, and integration with external contexts, truly useful AI assistants could soon be within reach. Adept's unveiling sets the stage for other labs to push boundaries even further in this exciting domain.