
Researchers from Ai2 and Contextual AI have released OLMoE, a fully open, state-of-the-art Mixture of Expert (MoE) model. Unlike most "open models" that only release weights, the researchers have made public all aspects of the project, including the model weights, complete training dataset (5.1 trillion tokens), full source code, etailed training logs and 244 intermediate checkpoints.
The OLMOE-1B-7B model utilizes a sparsely-activated Mixture-of-Experts (MoE) design, which selectively activates only a subset of its 6.9 billion parameters per input—just 1.3 billion at a time—resulting in far lower computational demands compared to dense models of similar size. This efficiency translates into lower costs for both training and inference, allowing OLMoE to operate at a fraction of the expense of models like Llama2 or DeepSeek, while still competing with them in performance.
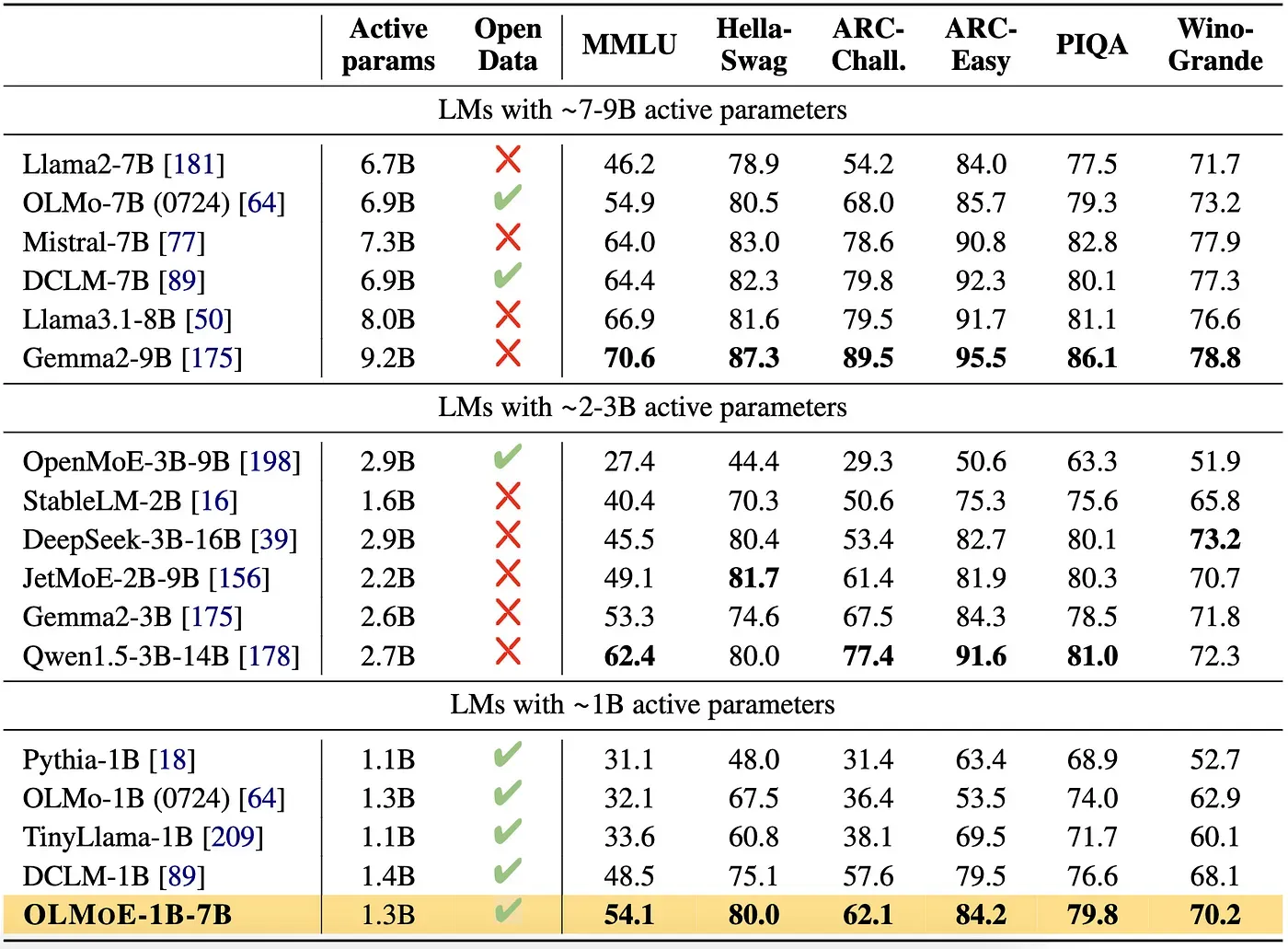
Early benchmarks show that OLMOE-1B-7B excels in areas like natural language understanding, code generation, and other key AI tasks, often surpassing models with double or triple the active parameters. OLMOE-1B-7B significantly outperforms all open 1B models and displays competitive performance to dense models with significantly higher inference costs and memory storage (e.g., similar MMLU scores to Llama2-13B, which is∼10×more costly).
OLMOE-MIX, the pre-training data for OLMoE, is a carefully curated blend of high-quality datasets. It primarily consists of the DCLM-Baseline dataset, a quality-filtered subset of Common Crawl, combined with selected components from Dolma 1.7. The researchers applied additional filtering to remove repetitive content and ensure data quality.
In their paper, the researchers shared a comprehensive set of controlled experiments that provide valuable insights into MoE training, even challenging some prevailing assumptions. For example, they found that fine-grained routing with many small experts outperformed configurations with fewer, larger experts. Additionally, their results suggest that some popular techniques, such as using shared experts or "upcycling" dense models into MoEs, may be less effective than previously thought.
The paper also notes that routing patterns stabilize early in the training process, experts tend to specialize in specific domains and vocabulary, and co-activation of experts is relatively rare.