
The Allen Institute for Artificial Intelligence (AI2) has unveiled a groundbreaking new contribution to the open-source AI ecosystem - OLMo, a large language model (LLM) that is completely open-source, providing unprecedented transparency into its inner workings.
Dubbed by AI2 as the "first truly open LLM," OLMo stands out by offering more than just the model code and weights. The institute has also published the full training data, training code, evaluation benchmarks, and toolkits used to develop OLMo. This level of openness allows AI researchers to deeply analyze how the model was built, advancing our collective understanding of LLMs.
The transparency around OLMo addresses concerns that many popular AI models today are like "black boxes", trained using undisclosed methods and datasets. As Hanna Hajishirzi, OLMo's project lead, stated: "Without access to training data, researchers cannot scientifically understand how a model is working." OLMo finally grants this visibility.
The model is built on AI2's Dolma dataset, which features a three trillion token open corpus for language model pre-training, including code that produces the training data. It includes full model weights for four model variants at the 7B scale, each trained to at least 2T tokens, along with inference code, training metrics, and logs. Additionally, OLMo's evaluation suite, released under the umbrella of the Catwalk and Paloma projects, comprises over 500 checkpoints per model from every 1000 steps during the training process.
And OLMo isn't just an academic exercise - it demonstrates cutting-edge performance on par with commercial offerings. Benchmarked against models like Meta's LLama and TII's Falcon, OLMo proved highly competitive, even surpassing them on certain natural language tasks.
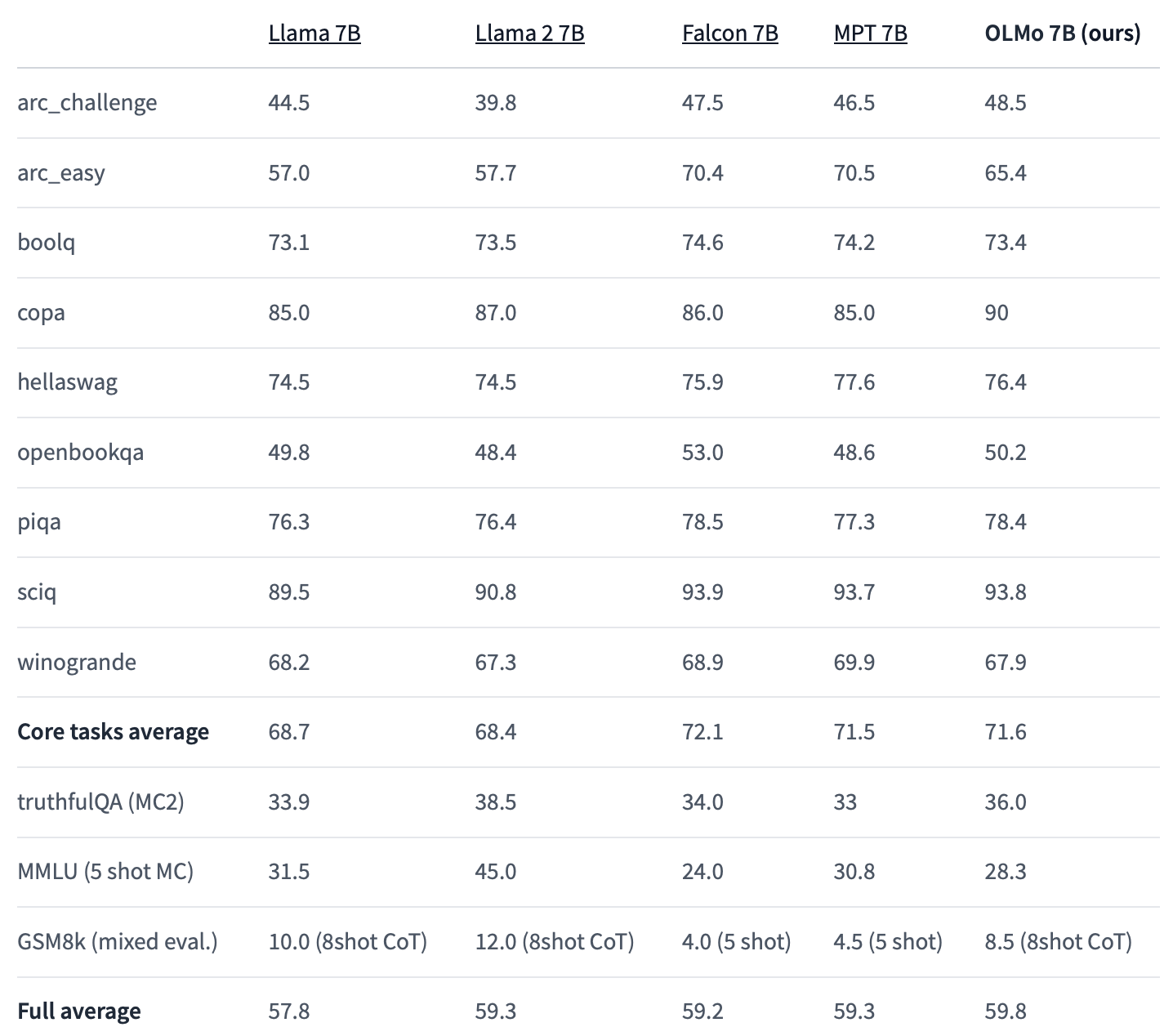
This strong debut for OLMo kicks off AI2's goal of iteratively building "the best open language model in the world." The institute plans to continue enhancing OLMo with additional model sizes, modalities, and capabilities over time.
By open-sourcing the full framework for developing OLMo, AI2 has set a new standard for transparency in AI research. Microsoft CSO Eric Horvitz commended this unprecedented degree of openness, saying it "will spur numerous advancements in AI across the global community.”
The release of OLMo is not just about providing tools; it's about building a foundation for a deeper understanding of AI models. As Yann LeCun, Chief AI Scientist at Meta, notes, open foundation models have been instrumental in driving innovation around generative AI. The vibrant community that emerges from open-source projects is crucial for accelerating the development of future AI technologies.
Collaborations with institutions like the Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University and partners including AMD, CSC (Lumi Supercomputer), the Paul G. Allen School of Computer Science & Engineering at the University of Washington, and Databricks have been pivotal in making OLMo a reality. These partnerships underscore the collaborative spirit that OLMo embodies, aiming to enhance AI experimentation and innovation across the globe.
The collaborative spirit behind OLMo harkens back to AI's early days as an open academic discipline. As AI adoption accelerates, initiatives like OLMo are critical for grounding the technology's progress in openness rather than secrecy. If AI is to benefit humanity, we must understand how it works - and OLMo pushes strongly in that direction.
We're excited to get our hands on OLMo. Once we've had a chance to put it through its paces and explore its architecture, we'll report back with more hands-on details.