
Chinese tech giant Alibaba has unveiled two new generative AI models named Qwen-VL (Qwen Large Vision Language Model) and Qwen-VL-Chat that demonstrate advanced abilities in interpreting images and engaging in natural conversations.
Given the surging demand for more advanced AI capabilities, Alibaba's new models couldn't have come at a better time. The new models are not just limited to understanding text, Qwen-VL is capable of ingesting and comprehending images, text, and bounding boxes. It can handle open-ended queries related to different images and generate captions accordingly. But the capabilities don't stop there.
Its sibling, Qwen-VL-Chat, is designed for more complex interactions. For instance, it can compare multiple image inputs, answer several rounds of questions, and even write stories or create images based on the photos a user provides. Imagine asking an AI about the layout of a hospital based on a picture of its signage, and getting an accurate answer—that's the level of sophistication Alibaba promises.
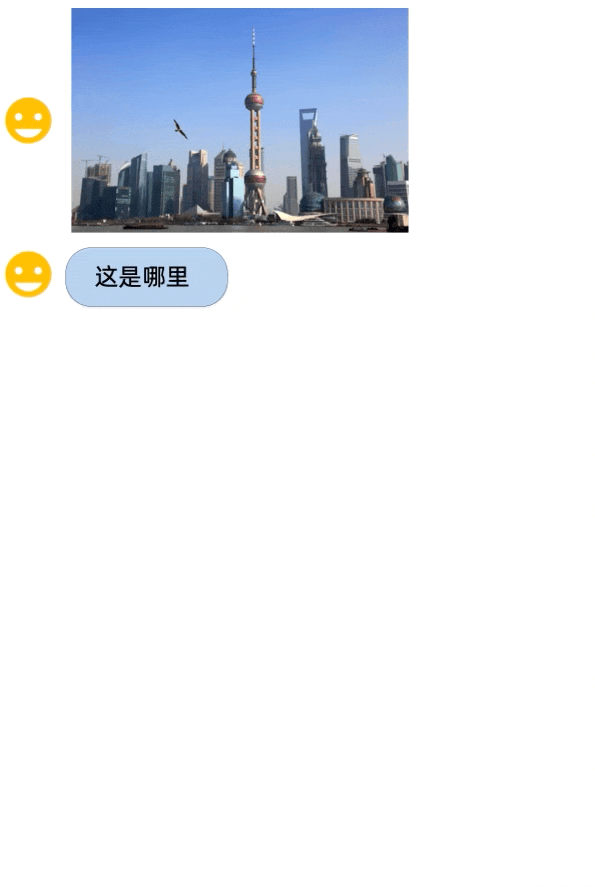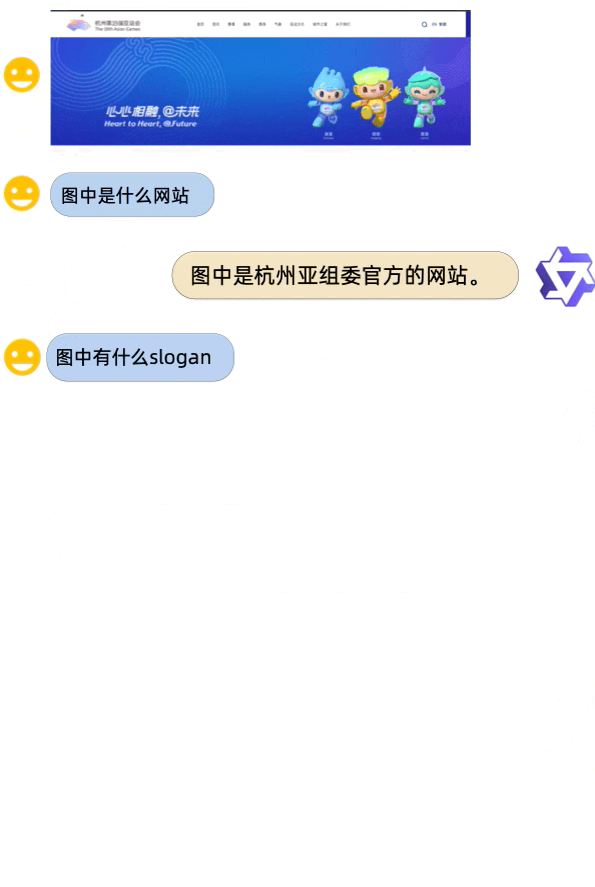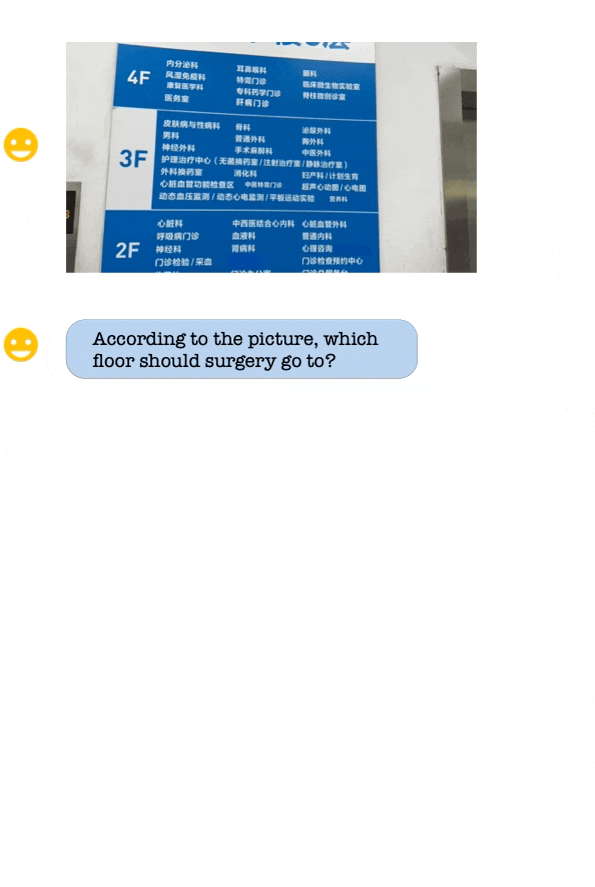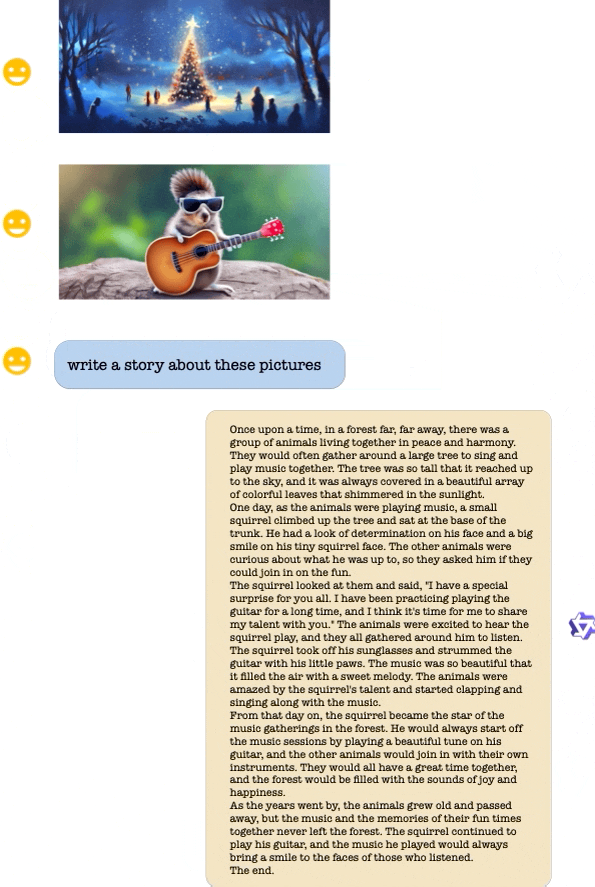
One of the major highlights of these models is their robust performance. According to Alibaba, Qwen-VL significantly outperforms existing open-source Large Vision Language Models on multiple English evaluation benchmarks.
It also introduces a novel feature called "multi-image interleaved conversations," which allows users to engage with the model using multiple images and specify questions related to those images. More importantly, it's one of the first generalist models to support "grounding" in Chinese, which involves detecting bounding boxes through open-domain language expression in both Chinese and English.
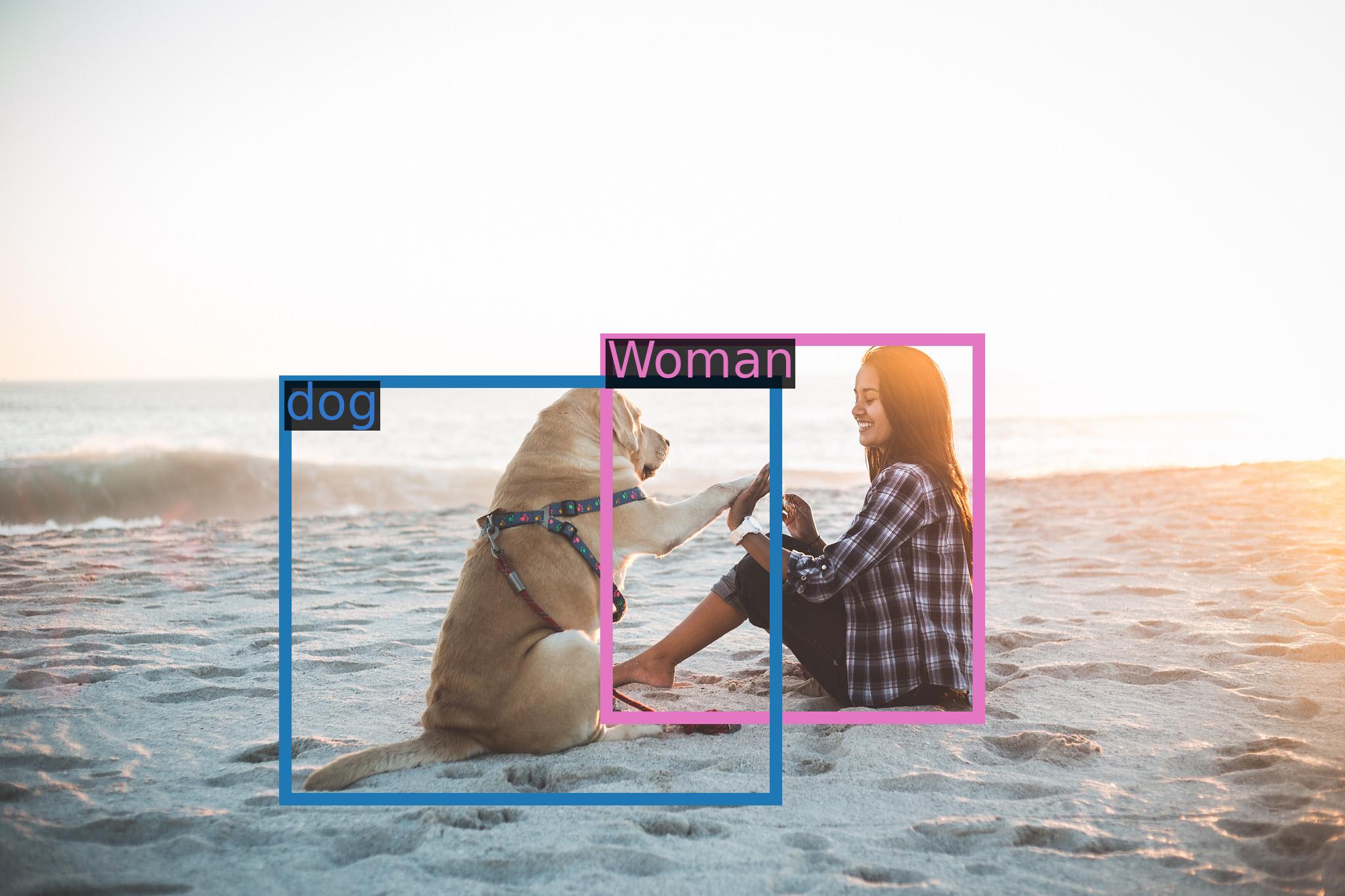
Using a set of standard benchmarks, Alibaba evaluated the models' abilities on a range of tasks, from zero-shot image captioning to text-based visual question answering. The models were also tested using TouchStone, a benchmark Alibaba developed, which is based on scoring with GPT-4 to evaluate the model's dialog capabilities and alignment with human understanding. The results? Qwen-VL and Qwen-VL-Chat achieved state-of-the-art performance across multiple evaluation categories, including attribute-based Q&A, celebrity recognition, and math problem solving.
As one of the first Chinese firms to unveil a competitive generative AI system, Alibaba's release of Qwen-VL and Qwen-VL-Chat signals China's rapid progress in AI research. By making the models open source, Alibaba is ensuring that researchers, academics, and companies worldwide can leverage them to develop their own applications without the time-consuming and expensive task of training models from scratch. It's a strategic move that echoes the broader trend in AI towards collaboration and shared resources.
The launch comes amidst fierce competition between tech giants to lead the AI race. From Google's Bard to Anthropic's Claude, companies are locked in an AI arms race to develop ever-more capable generative models with business, societal, and geopolitical implications. With Qwen-VL and Qwen-VL-Chat demonstrating strong general intelligence skills, Alibaba and China have staked a claim in this high-stakes global AI arena. It's a bold statement from the company, and a reminder that they are not just a retail giant but also a formidable player in the world of AI.