
Alibaba's Qwen team has introduced QVQ, a new multimodal AI model designed specifically for visual reasoning tasks. Positioned as an open-weight model, QVQ builds upon the foundation of Qwen2-VL-72B, offering improved capabilities in interpreting and reasoning from visual inputs combined with textual instructions.
Key Points:
- QVQ focuses on enhancing AI's visual reasoning capabilities, excelling in domains like mathematics and physics.
- Built on Qwen2-VL-72B, QVQ integrates architectural improvements for cross-modal reasoning and step-by-step analytical thought.
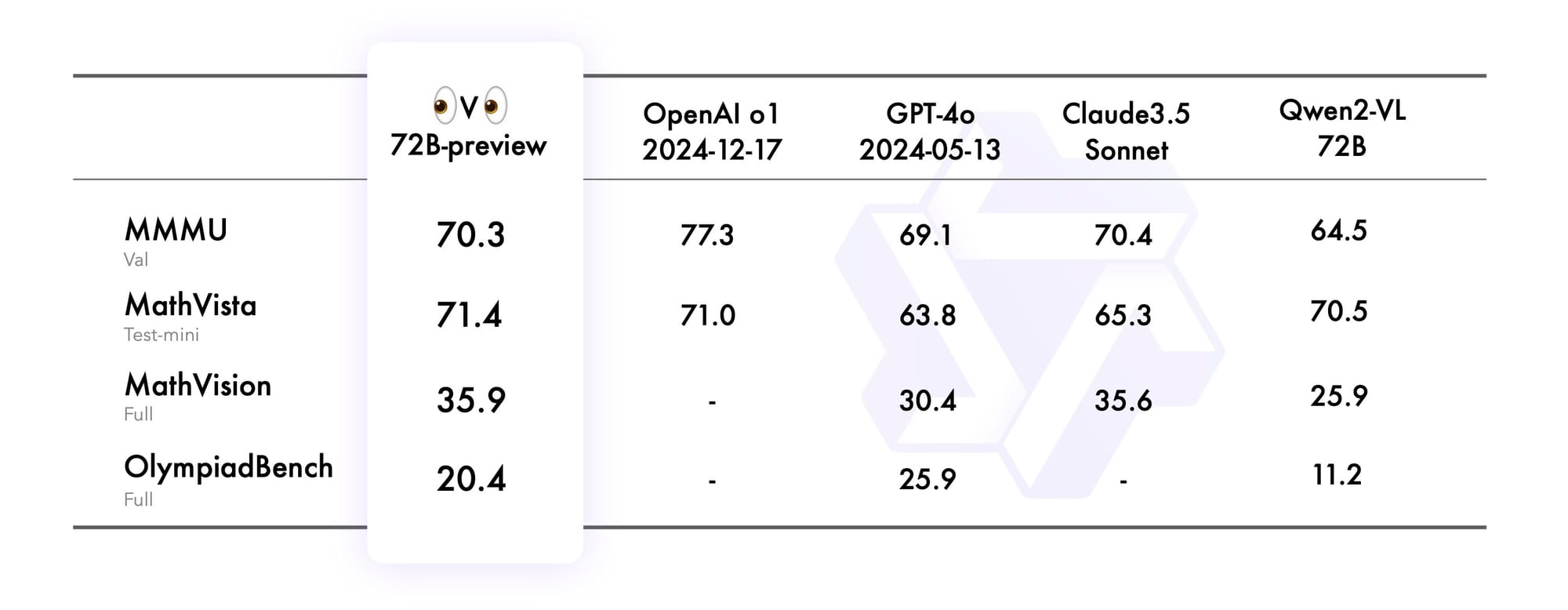
- The model scored 70.3 on the MMMU benchmark, showcasing strong visual reasoning performance.
- Limitations include occasional language switching, recursive reasoning loops, and focus loss during multi-step tasks.
Why it Matters: Visual reasoning has long been a challenge for AI systems, as it requires the integration of textual context with visual data. QVQ represents an important step in bridging this gap, demonstrating the ability to not only interpret images but also reason through complex visual problems. Its open-weight nature encourages collaboration among researchers and developers, fostering innovation in AI applications.
How it Works: QVQ is built upon Qwen2-VL-72B's architecture but incorporates refinements tailored to multimodal reasoning. With 72 billion parameters, the model processes and aligns visual and textual data in a hierarchical structure, enabling it to tackle sophisticated reasoning tasks. Benchmarks such as MMMU and MathVista highlight its ability to handle problems requiring advanced logical and analytical thinking.
An example for visual math problem solving. pic.twitter.com/APwMIob8kH
— Qwen (@Alibaba_Qwen) December 24, 2024
Despite its strengths, the Qwen team acknowledges several limitations in this preview version. The model can occasionally fall into repetitive reasoning patterns, switch languages unexpectedly, and lose focus on key image details in longer reasoning tasks.
Zoom Out: The Qwen team sees QVQ as a foundational step towards an 'omni' model capable of integrating multiple modalities beyond vision and text. Their broader goal is to push closer to artificial general intelligence (AGI) by enhancing the model's reasoning abilities across diverse domains.
As multimodal AI systems become more integral to solving real-world challenges, QVQ's introduction marks a significant milestone. While the model's current limitations make it more suitable for research than production environments, its open-source nature could accelerate the development of more robust visual reasoning systems.