
Anthropic released Claude Opus 4.1 today with a 74.5% score on SWE-bench Verified to claim the top spot for AI models solving real GitHub issues the way a human engineer would. That's a small but meaningful jump past OpenAI's o3, which has held the top spot at 69.1% since it went public in April.
Key Points:
- Claude Opus 4.1 scores 74.5% on SWE-bench Verified, beating o3's 69.1% to become the highest-scoring publicly available model
- Same $15/$75 pricing as Opus 4 with immediate availability through Claude.ai, API, Amazon Bedrock, and Google Cloud
- GitHub reports major gains in multi-file refactoring, with Rakuten praising its precision in large codebases
For context on what these numbers mean: SWE-bench tests how well AI can solve real-world software issues sourced from GitHub—the model gets a code repository and issue description, then has to generate a patch that resolves the problem. These aren't just theoretical problems. They're the actual bugs and feature requests developers deal with daily.
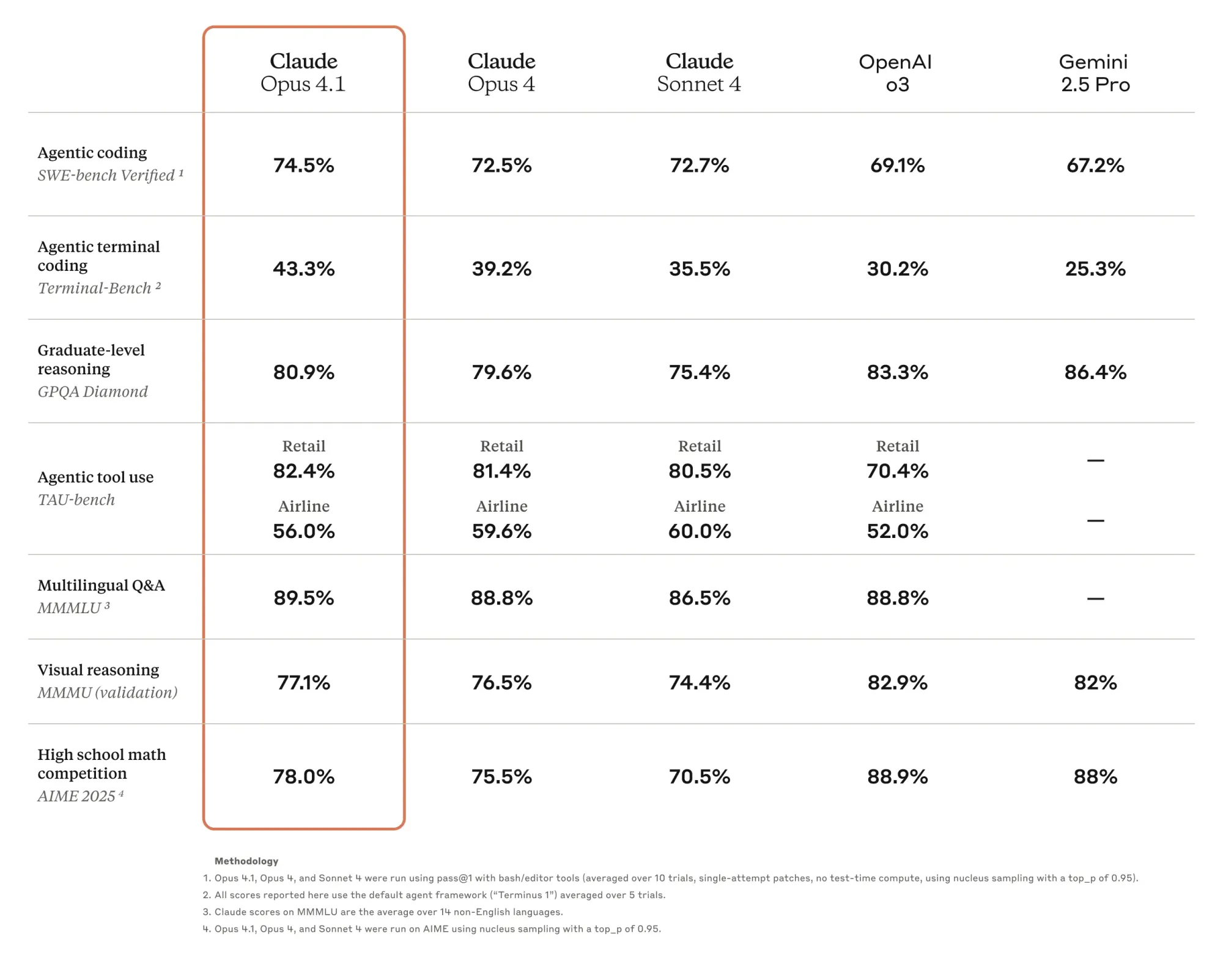
The progress here is staggering. When SWE-bench launched, the best models solved maybe 2% of issues. Even Devin, the much-hyped AI coding agent from Cognition, only hit 13.86% when it launched. Claude 3.6 Sonnet hit 50.8%, Gemini 2.0 Flash reached 51.8%, and then o3 jumped to 69.1%—a 20% leap that shocked everyone. Now Claude Opus 4.1 pushes that bar higher still.
GitHub notes that Claude Opus 4.1 improves across most capabilities relative to Opus 4, with particularly notable performance gains in multi-file code refactoring. That's crucial for real-world development. Rakuten Group finds that Opus 4.1 excels at pinpointing exact corrections within large codebases without making unnecessary adjustments or introducing bugs. In other words, it's not just solving problems—it's solving them cleanly.
GitHub Copilot added Claude Opus 4.1 to their model picker immediately, making it available to GitHub Copilot Enterprise and Pro+ plans. That's a vote of confidence from the platform that arguably matters most for AI coding adoption.
There's an important caveat: SWE-bench Verified only tests Python repositories, and most of the problems are relatively simple, needing less than 1 hour to fix for a human engineer. Your experience on that legacy enterprise codebase might vary. And o3 still beats Claude on other benchmarks—it's not a clean sweep by any means.
But for developers looking at which model to use today for actual coding tasks, Claude Opus 4.1 just made a compelling case. Same price as before, available everywhere Claude already works, and now with the highest score on the benchmark everyone watches.
Anthropic says they plan to release substantially larger improvements to their models in the coming weeks. Given how quickly these leaderboards change—we probably won't wait long for the next shift.