Anthropic is making life a bit easier for AI developers building with their models. The company recently rolled out new features for Claude console that it says will help to take the guesswork out of building effective prompts. A new "Evaluate" tab will allow developers to generate prompts, create test cases automatically, and compare outputs side-by-side.
"Prompt quality significantly impacts results," Anthropic explained in a blog post. "But crafting high-quality prompts is challenging, requiring deep knowledge of your application's needs and expertise with large language models."
Earlier this year, Anthropic released a prompt generator helper tool that allows developers to describe their task in plain language and receive a tailored, high-quality prompt in return. This feature alone dramatically reduces the time and expertise required to create effective AI interactions.
The new updated prompt generator, powered by Claude 3.5 Sonnet, will create prompts with dynamic variables using the appropriate double brace syntax {{variable}}, which is required for creating eval test sets.
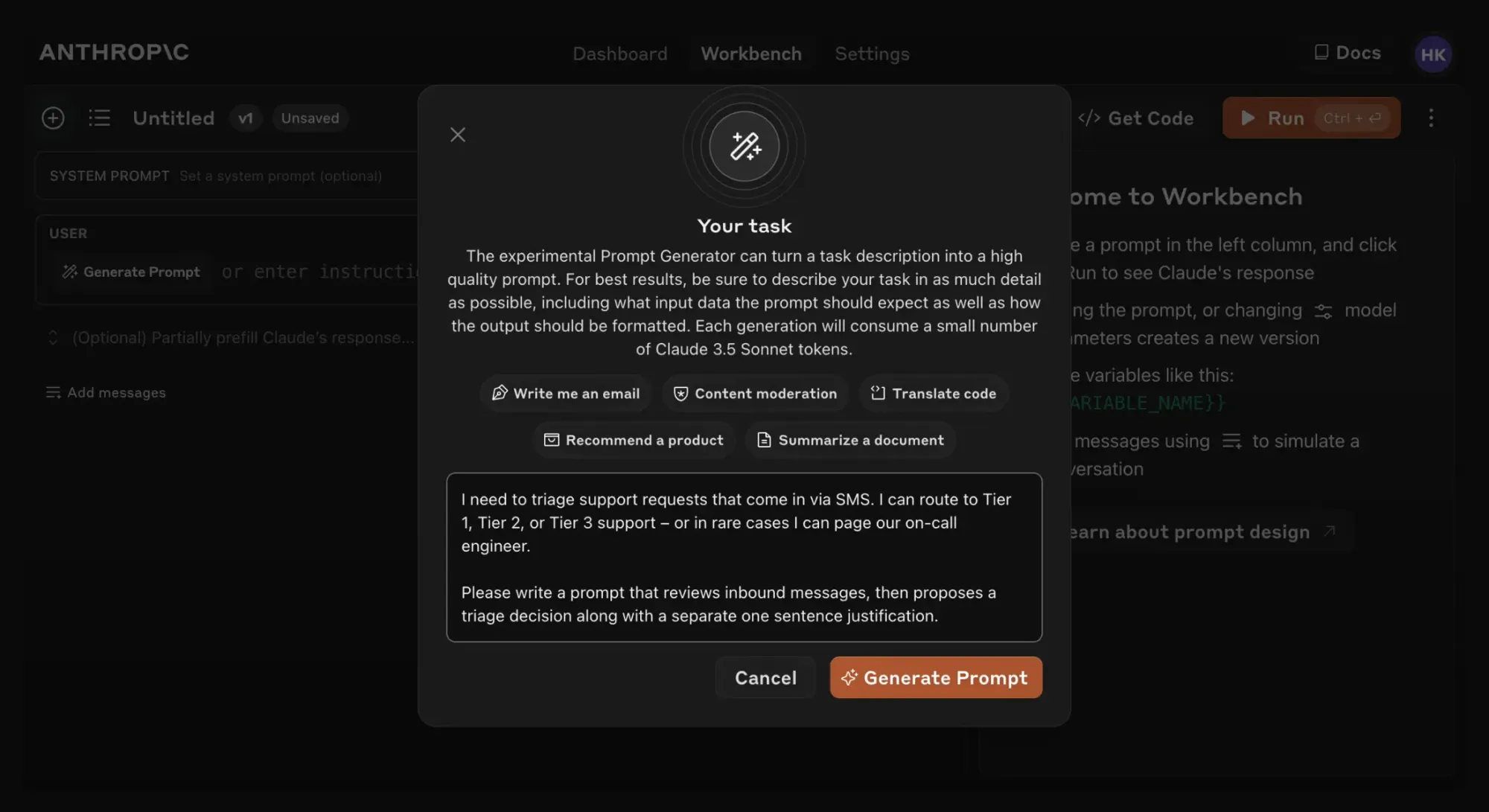
Once the prompt is ready, developers can now use Claude to automatically generate realistic input data based off of their prompt. They can then conduct more robust testing using the new ‘Evaluate’ feature.
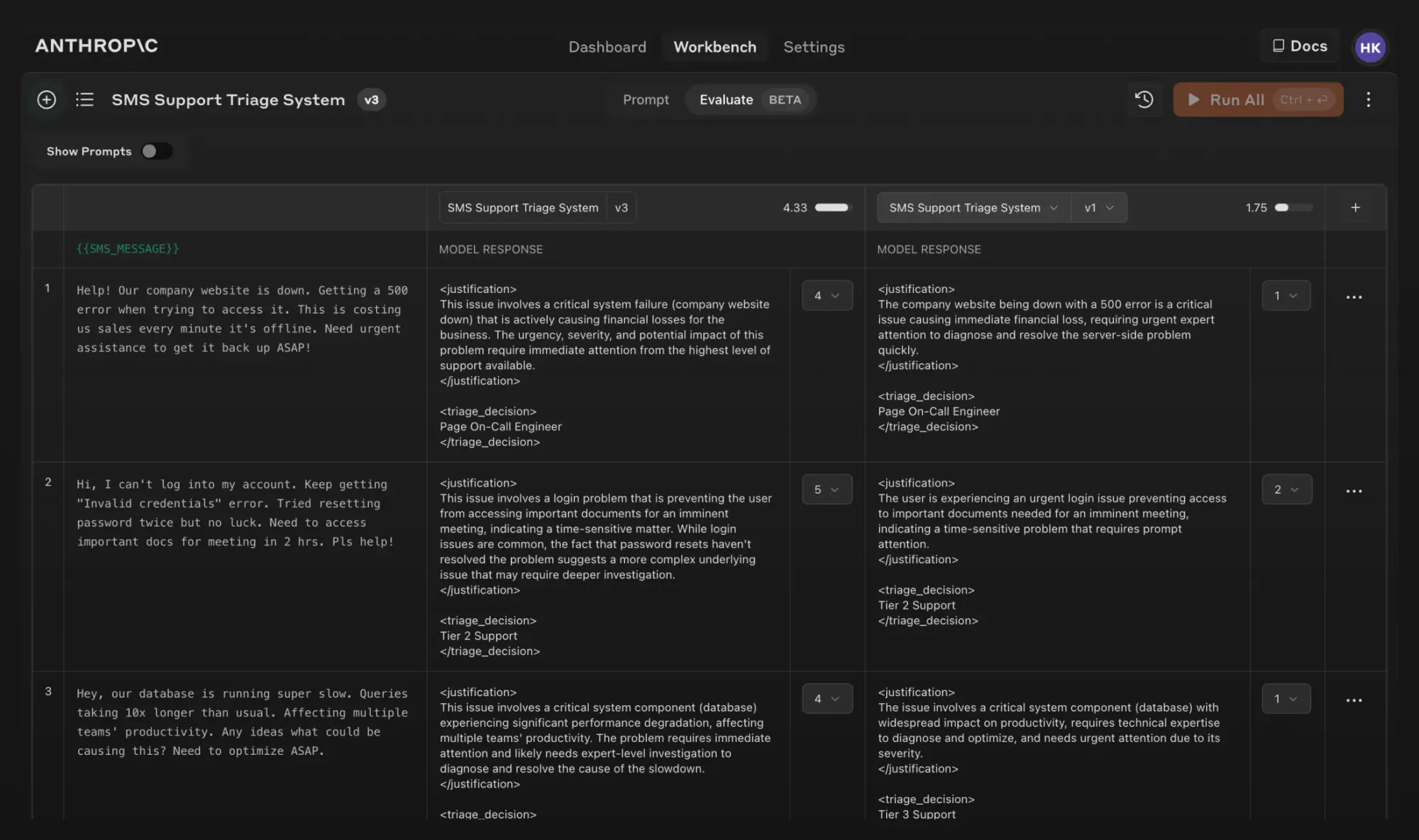
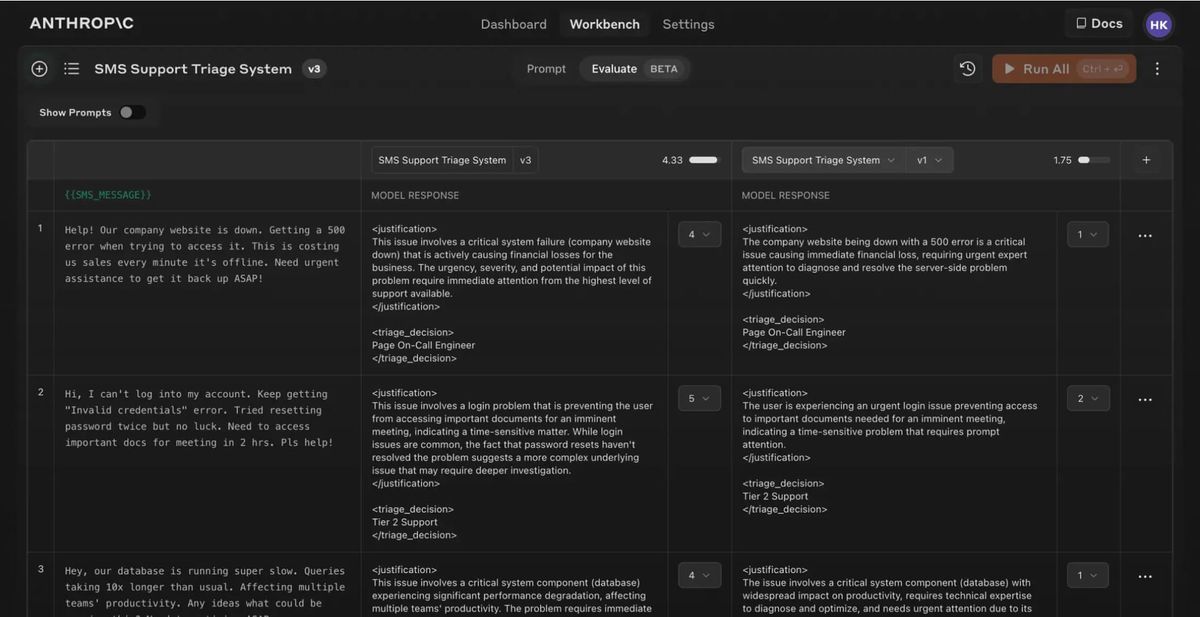
On the Evaluate page, you can set up as many test cases as you want—generating them with Claude, manually adding them, or importing multiple test cases from a CSV file. Once the test suite is set up, developers can run all test cases with a single click and see how their prompts perform across various scenarios.
A really handy feature is the ability to compare the outputs of different prompts side by side. This allows for a more nuanced understanding of how changes to a prompt affect the results, enabling quicker and more effective iterations. Additionally, subject matter experts can grade response quality on a 5-point scale, providing valuable feedback on whether the changes have led to improvements.
The Evaluation tool is currently in beta, and is available to all users on the Anthropic Console.