
Anthropic dropped its latest AI model Monday with a bold proclamation: Claude Sonnet 4.5 is the best coding model in the world. That's a big claim in an industry where "best" tends to have a shelf life measured in weeks, not months. But the San Francisco-based AI company is backing it up with benchmarks, customer testimonials, and one particularly eye-catching number: this thing can code autonomously for more than 30 hours straight.
Key Points:
- Claude Sonnet 4.5 achieves state-of-the-art performance on SWE-bench Verified.
- The model costs the same as Claude Sonnet 4.
- Anthropic claims this is its "most aligned" model yet.
Less than two months ago, Anthropic released Claude Opus 4.1. Before that, Claude Sonnet 4 arrived in May. The breakneck release schedule reflects just how competitive things have gotten. OpenAI launched GPT-5 in August, and Gemini 3 is reportedly on the horizon. Nobody stays on top for long.
What separates Sonnet 4.5 from its predecessors isn't just raw intelligence—it's endurance. Claude Opus 4 could handle about seven hours of autonomous work before losing the plot. Sonnet 4.5 extends that to 30 hours or more, according to Anthropic's Chief Product Officer Mike Krieger. During early enterprise trials, the company watched Sonnet 4.5 not just build an application but stand up database services, purchase domain names, and perform SOC 2 security audits—all without human intervention. Read more on the System Card here.
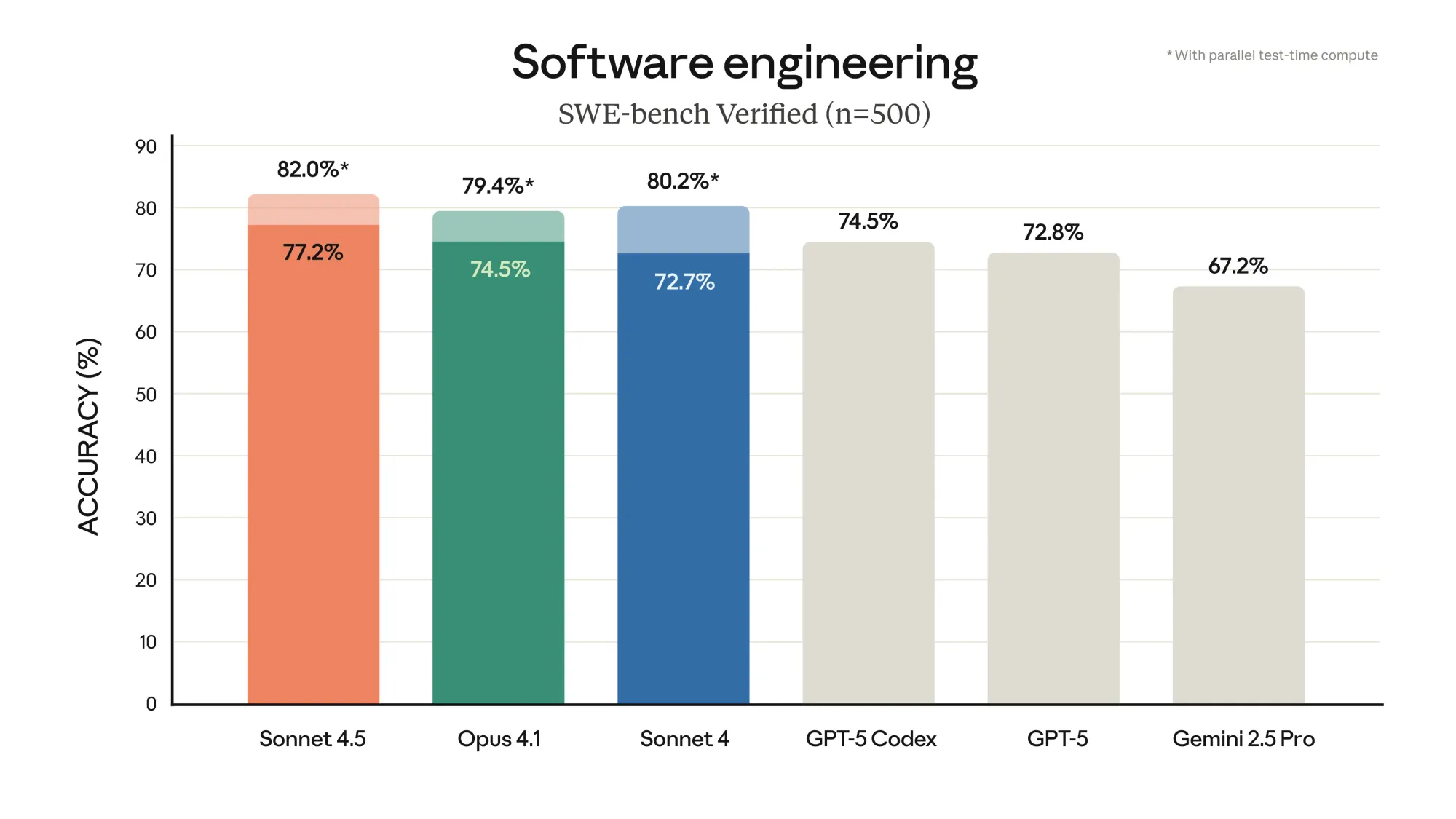
The model tops the SWE-bench Verified leaderboard, a benchmark that tests AI systems on actual GitHub issues from open-source Python repositories. Most of these problems take human engineers less than an hour to fix, but they require understanding large codebases, navigating unfamiliar code, and making surgical changes without breaking anything else. Sonnet 4.5 also scored 61.4% on OSWorld, a test of real-world computer tasks, up from 42.2% just four months ago with Sonnet 4.
Cursor CEO Michael Truell called Sonnet 4.5 "state-of-the-art" for longer-horizon coding tasks, while Windsurf CEO Jeff Wang described it as a "new generation of coding models". GitHub immediately added support for Sonnet 4.5 in Copilot for Pro, Business, and Enterprise users.
But raw performance is only part of the story. Anthropic is pitching Sonnet 4.5 as more than a powerful autocomplete—it's positioning the model as a colleague. Scott White, a product lead at Anthropic, described the evolution: "This is a continued evolution on Claude, going from an assistant to more of a collaborator to a full, autonomous agent that's capable of working for extended time horizons".
That shift from assistant to agent brings new risks. AI models with more autonomy need better guardrails, and Anthropic claims it's delivered. The company says Sonnet 4.5 is its most aligned frontier model yet, with major improvements in refusing harmful requests, resisting prompt injection attacks, and avoiding behaviors like excessive flattery or encouraging delusional thinking in users. The company's blog post highlights "substantial" improvements in "reducing concerning behaviors like sycophancy, deception, power-seeking, and the tendency to encourage delusional thinking".
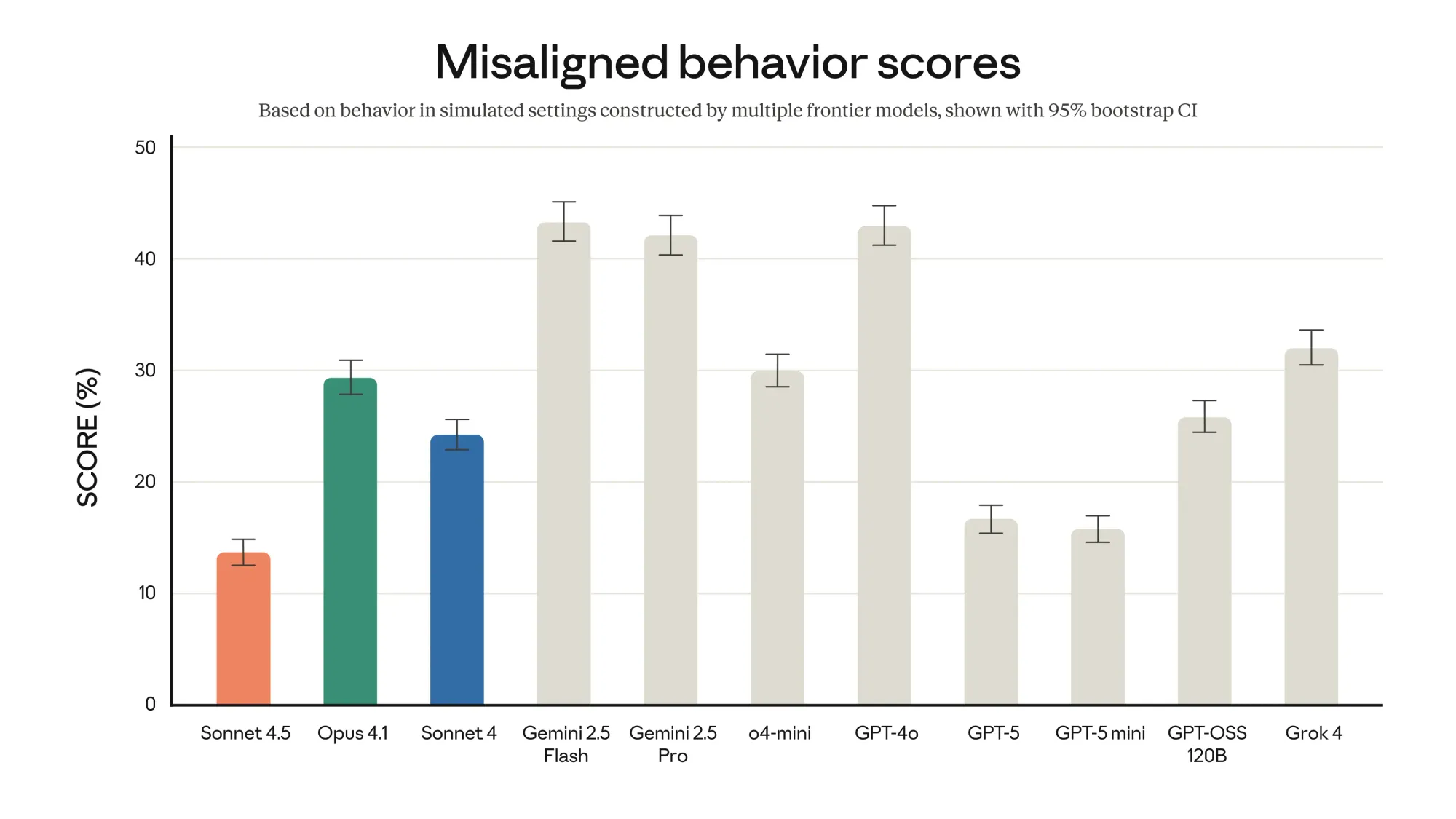
Jared Kaplan, Anthropic's chief science officer, called it "the biggest jump in safety that I think we've seen in the last probably year, year and a half". The 300-page system card Anthropic published alongside the model includes detailed safety evaluations, from testing the model's propensity for reward hacking to probing whether it would attempt to sabotage oversight mechanisms. Anthropic even used mechanistic interpretability techniques—analyzing the model's internal representations—to understand whether it could detect when it was being evaluated and adjust its behavior accordingly. (It could, but the company says that doesn't undermine their safety conclusions.)
Anthropic reports Claude Code now generates over $500 million in annual recurring revenue, driven largely by coding use cases. Companies like Apple and Meta reportedly use Claude models internally. With Sonnet 4.5, Anthropic is betting that sustained, reliable performance on long-duration tasks will be more valuable than flashy short demos.
Developers can access Sonnet 4.5 through the Claude API, Amazon Bedrock, or the claude.ai web app. Anthropic is also shipping the Claude Agent SDK—the same infrastructure that powers Claude Code—so developers can build their own AI agents. There's even a temporary research preview called "Imagine with Claude" where the model generates software on the fly with no predetermined functionality or prewritten code. It's available to Max subscribers for five days.
One data point that deserves attention: Anthropic claims its models are improving at a predictable rate. The company says that "every six months its new model can handle tasks that are twice as complex". If that holds—and it's a big if—the implications for software development are significant. We're talking about AI systems that can work through multi-day projects, make architectural decisions, and ship production code.
Whether that's exciting or unsettling probably depends on whether you write code for a living.