
Anthropic has introduced a new method called "Contextual Retrieval" that significantly improves how AI systems access and utilize information from large knowledge bases. This technique addresses a critical weakness in traditional Retrieval-Augmented Generation (RAG) systems.
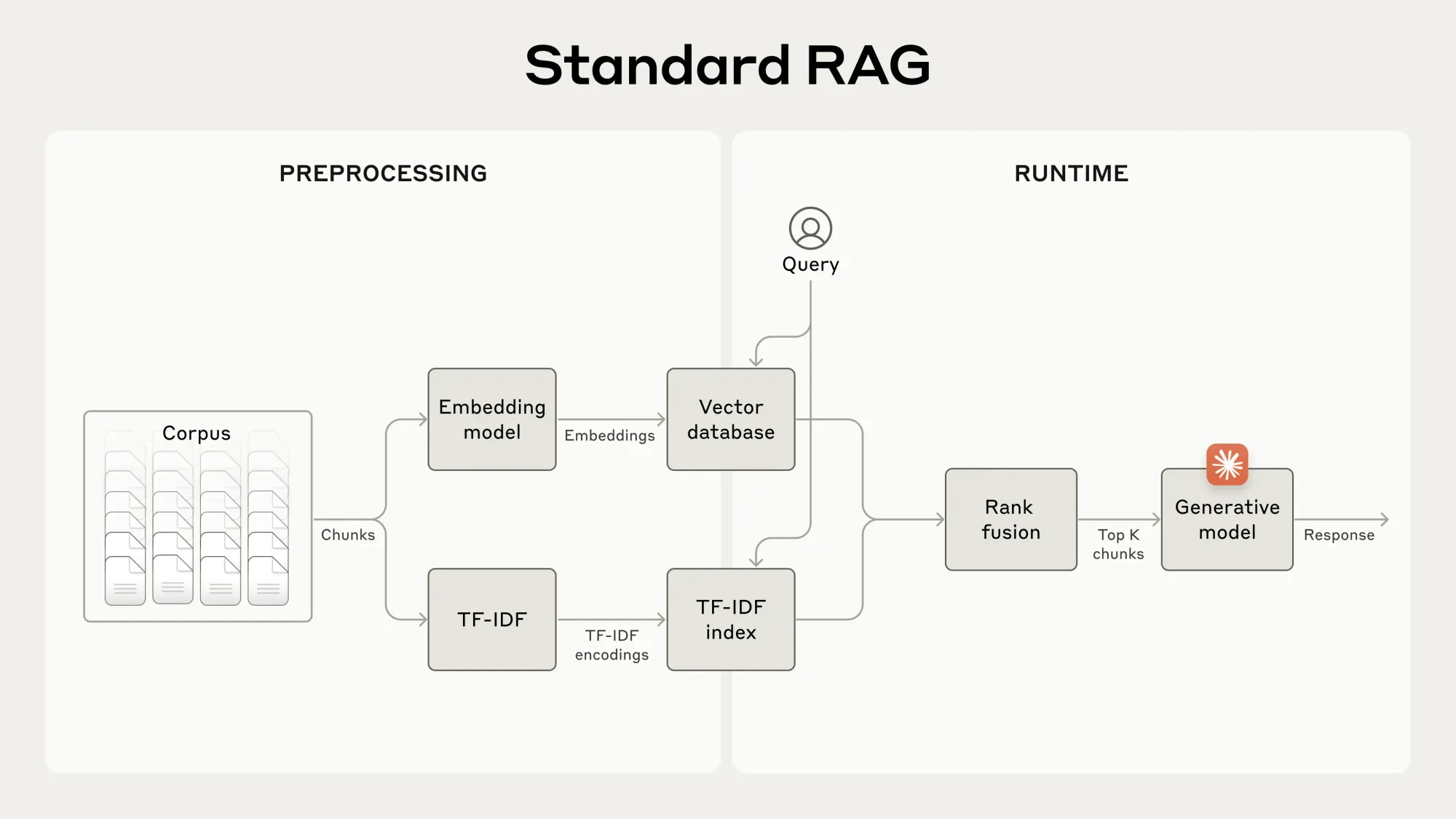
Contextual Retrieval tackles a fundamental issue in RAG: the loss of context when documents are split into smaller chunks for processing. By adding relevant contextual information to each chunk before it's embedded or indexed, the method preserves critical details that might otherwise be lost.
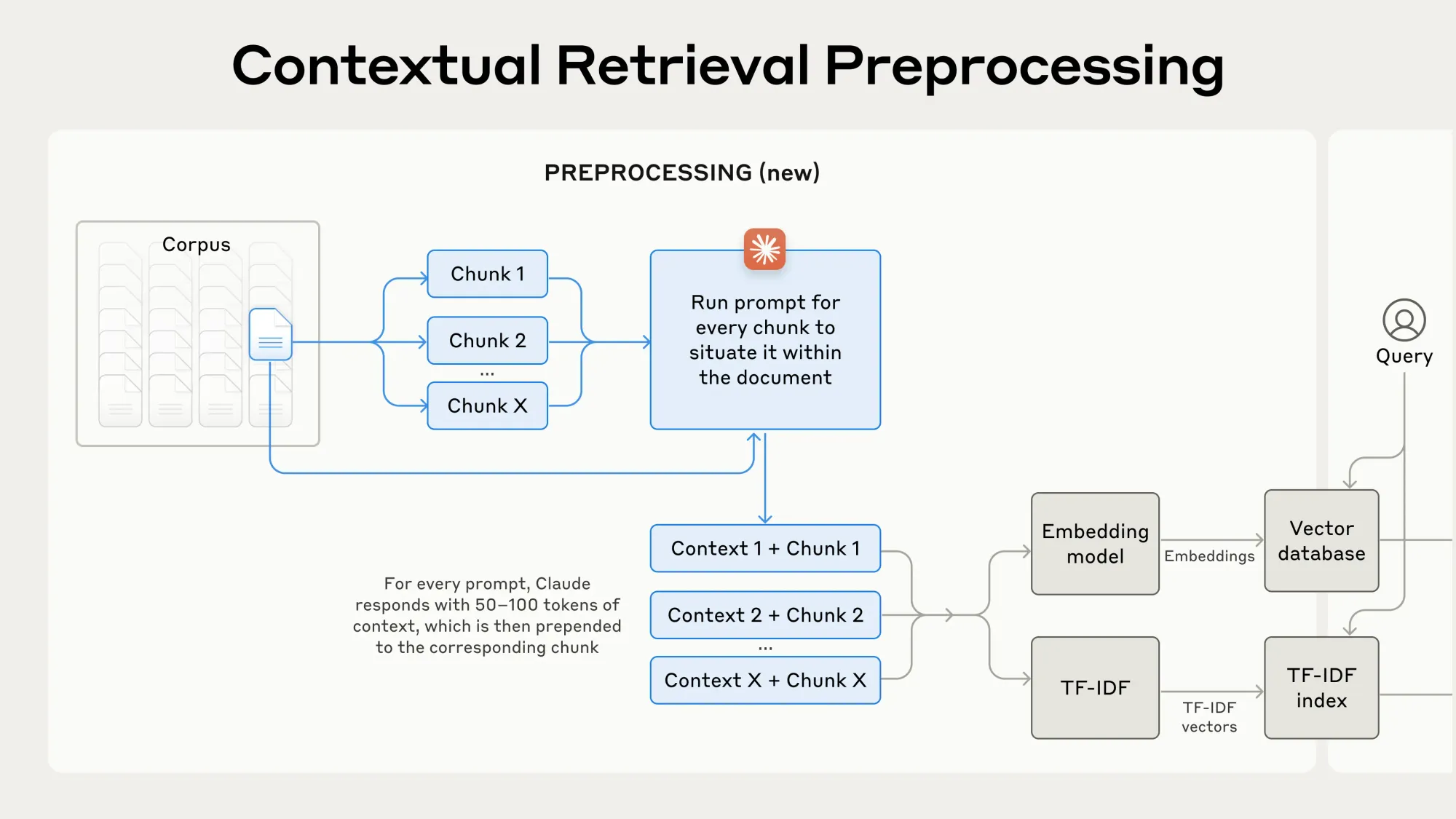
In practical terms, this involves using Anthropic’s Claude model to generate chunk-specific context. For instance, a simple chunk stating, “The company’s revenue grew by 3% over the previous quarter,” becomes contextualized to include additional information such as the specific company and the relevant time period. This enhanced context ensures that retrieval systems can more accurately identify and utilize the correct information.
The technique employs two key components: Contextual Embeddings and Contextual BM25. These work together to dramatically reduce retrieval failures - instances where the AI fails to find the most relevant information.
Alex Albert, Head of Developer Relations at Anthropic, highlighted the significance of this advancement: "Contextual Retrieval reduces incorrect chunk retrieval rates by up to 67%. When combined with prompt caching, it may be one of the best techniques there is for implementing retrieval in RAG apps."
Excited to share our latest research on Contextual Retrieval - a technique that reduces incorrect chunk retrieval rates by up to 67%.
— Alex Albert (@alexalbert__) September 19, 2024
When combined with prompt caching, it may be one of the best techniques there is for implementing retrieval in RAG apps.
Let me explain: pic.twitter.com/UG1H8DLMxZ
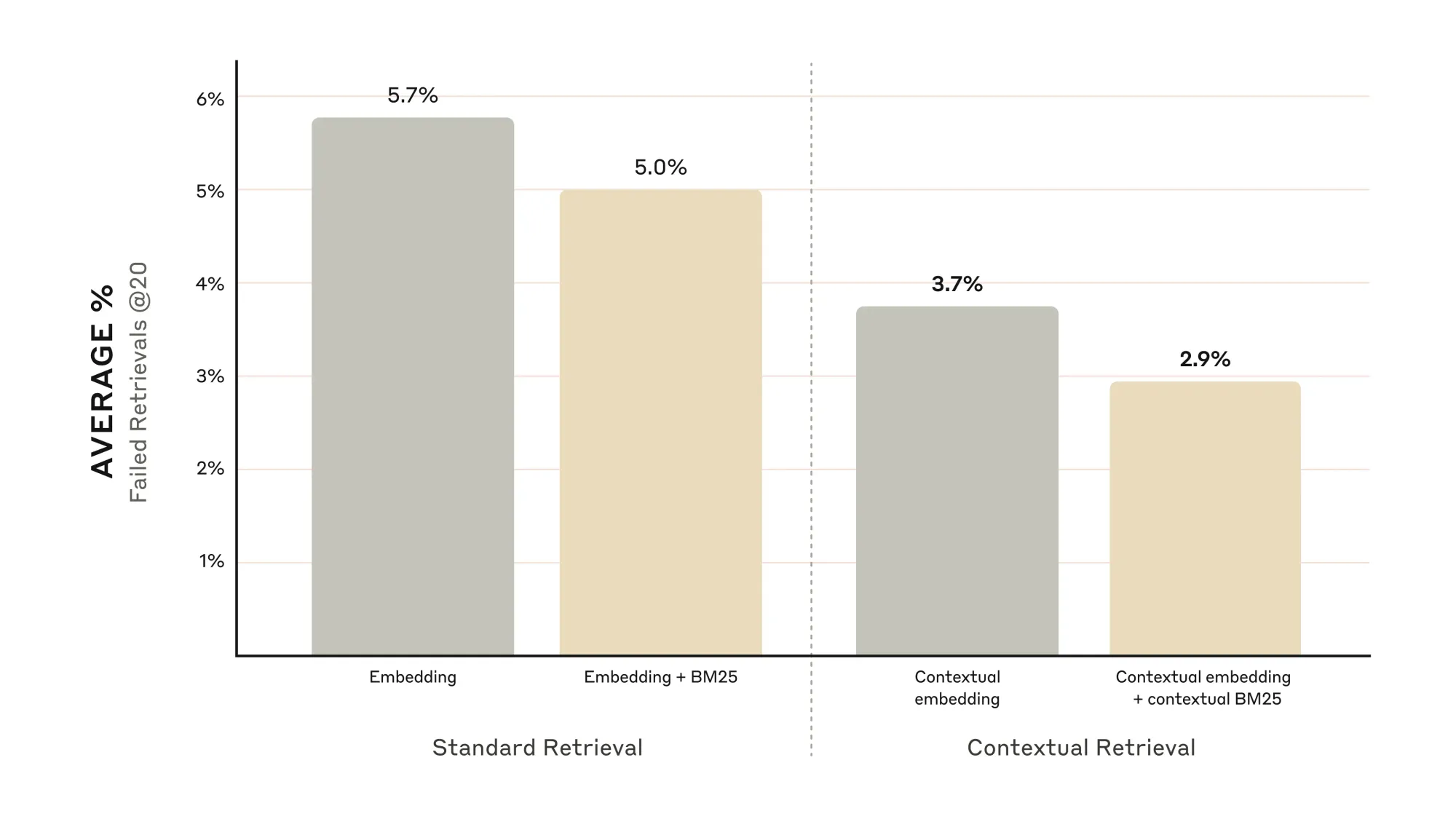
The improvements are substantial:
- Contextual Retrieval embeddings alone cut retrieval failures by 35%
- Combining Contextual Retrieval embeddings with contextual BM25 reduces failures by 49%
- Adding a reranking step on top of these techniques slashes failures by 67%
These gains in accuracy directly translate to better performance in downstream tasks, potentially improving the quality of AI-generated responses across a wide range of applications.
Anthropic's research demonstrates the effectiveness of Contextual Retrieval across various knowledge domains, including codebases, fiction, scientific papers, and financial documents. The technique showed consistent improvements regardless of the embedding model used, though some models like Gemini and Voyage embeddings were found to be particularly effective.
One of the key innovations enabling Contextual Retrieval is prompt caching, which the company announced last month, and significantly lowers implementation costs. The estimated cost for contextualization is only $1.02 per million document tokens. This cost-efficiency makes Contextual Retrieval accessible for large-scale applications, where manual annotation of chunks would be impractical.
If you're interested in implementing Contextual Retrieval, Anthropic has released a cookbook detailing the process. The company encourages experimentation with the technique, noting that custom prompts tailored to specific domains may yield even better results.