
Anthropic has introduced prompt caching, a new feature for its Claude AI models that promises significant cost savings and performance improvements for developers. The feature, now in public beta, allows reuse of large context across multiple API requests. Anthropic claims this feature can reduce costs by up to 90% and cut latency by up to 85% for long prompts.
Prompt caching allows developers to maintain a consistent context across multiple interactions with the AI. Instead of sending a large block of information with every API request, developers can cache that context once and reuse it, enhancing the efficiency of their systems.
This proves particularly useful in applications like conversational agents, coding assistants, and processing large documents. For example, developers can include entire books or coding examples in their prompts without incurring significant delays in response time.
When a request is sent with prompt caching enabled, the system checks if the prompt prefix is already cached from a recent query. If found, it uses the cached version, reducing processing time and costs. Otherwise, it processes the full prompt and caches the prefix for future use.
The cache has a 5-minute lifetime and is refreshed with each use, making it ideal for long multi-turn conversations or complex tasks requiring multiple API calls. Here are some examples of where prompt caching may be useful:
- Conversational agents: Reduce costs and latency for extended interactions, particularly those with long instructions or documents.
- Coding assistants: Store summarized versions of a codebase to improve autocomplete and codebase Q&A performance.
- Large document processing: Include full-length materials like books or articles without increasing response time.
- Detailed instruction sets: Incorporate extensive lists of instructions or examples to fine-tune responses.
- Agentic tool use: Improve scenarios involving multiple rounds of tool calls or iterative steps, which typically require new API requests.
- Long-form content interaction: Embed complete documents, podcasts, or papers into the prompt, allowing users to query these knowledge bases directly.
Anthropic notes that the minimum cacheable prompt length is 1,024 tokens for Claude 3.5 Sonnet and 2,048 tokens for Claude 3 Haiku. Shorter prompts cannot be cached, even if marked.
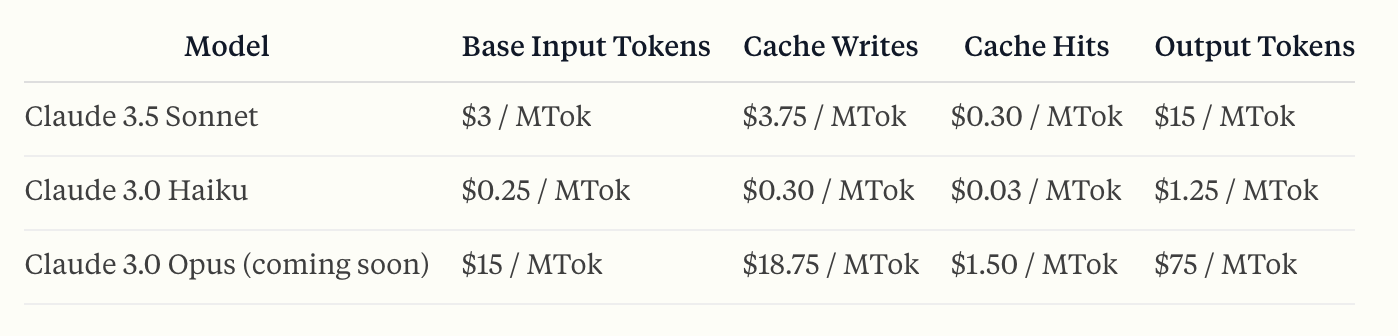
Prompt caching is currently available for Claude 3.5 Sonnet and Claude 3 Haiku, with support for Claude 3 Opus expected soon. Pricing is structured around input token usage: writing to the cache costs 25% more than the base token price, but retrieving cached content is 90% cheaper than the standard input token rate.
As AI integration becomes more prevalent in software applications, features like prompt caching may play a crucial role in making advanced language models more accessible and economically viable for developers and businesses. By optimizing API usage and reducing costs, prompt caching could enable more sophisticated AI applications across various industries.