
Apple continues to explore and push the boundary of on-device AI with their latest research on MobileCLIP, a family of efficient image-text models optimized for mobile performance. Alongside this, they have introduced a new multi-modal reinforced training approach that leverages knowledge transfer to significantly boost learning efficiency.
Large image-text foundation models, such as CLIP, have shown impressive zero-shot performance and improved robustness across various tasks. However, deploying these models on mobile devices is challenging due to their large size and high latency.
MobileCLIP models are designed using hybrid CNN-transformer architectures with structural reparameterization in image and text encoders, reducing size and latency. The new models include S0, S1, S2, and B variants, covering various sizes and latencies for different mobile applications.
- The smallest variant
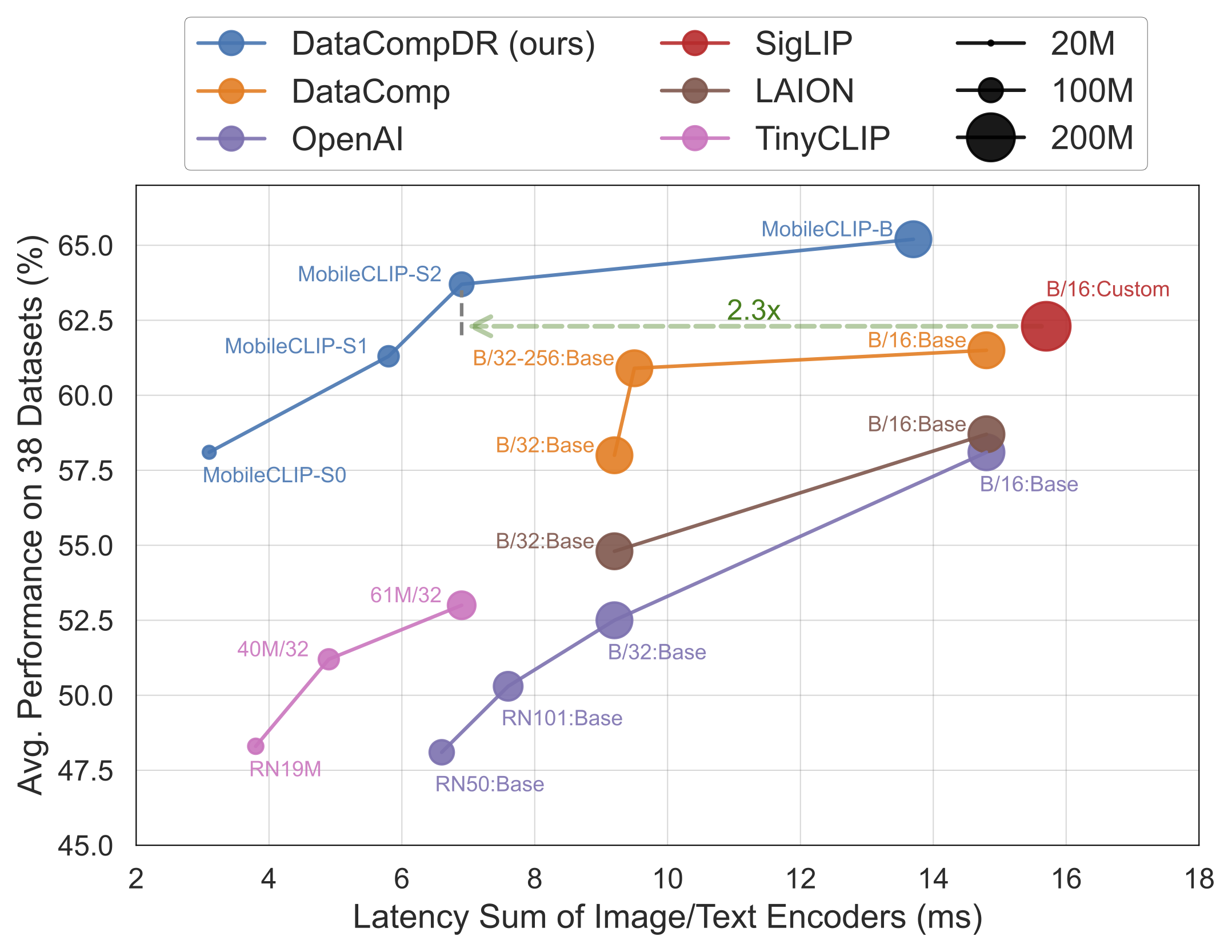
MobileCLIP-S0obtains similar zero-shot performance as OpenAI's ViT-B/16 model while being 4.8x faster and 2.8x smaller. MobileCLIP-S2obtains better avg zero-shot performance than SigLIP's ViT-B/16 model while being 2.3x faster and 2.1x smaller, and trained with 3x less seen samples.MobileCLIP-B(LT) attains zero-shot ImageNet performance of 77.2% which is significantly better than recent works like DFN and SigLIP with similar architectures or even OpenAI's ViT-L/14@336.
To improve the learning efficiency of MobileCLIP models, Apple has introduced multi-modal reinforced training, a novel training strategy that incorporates knowledge transfer from a pre-trained image captioning model and an ensemble of strong CLIP models. This approach avoids train-time compute overhead by storing the additional knowledge in a reinforced dataset.
The reinforced dataset, called DataCompDR, comes in two variants: DataCompDR-12M and DataCompDR-1B. Training with DataCompDR shows significant learning efficiency (10-1000x) improvement compared to standard CLIP training. For example, using DataCompDR-12M, a ViT-B/16-based CLIP model can achieve 61.7% zero-shot classification on ImageNet-val in approximately one day with a single node of 8×A100 GPUs.
At the core of MobileCLIP are hybrid CNN-transformer architectures for both the image and text encoders. For the image encoder, they introduce the MCi architecture - an improved hybrid vision transformer based on the recent FastViT model. Key optimizations include reducing the MLP expansion ratio in the feed-forward blocks and increasing model depth for better parameter efficiency.
For text encoding, Apple developed the Text-RepMixer - a convolutional token mixer that enables decoupling train-time and inference-time architectures. By strategically replacing self-attention layers with convolutional blocks, the Text-RepMixer achieves similar accuracy as pure transformer models while being smaller and faster.
The key innovation of multi-modal reinforced training is its ability to transfer knowledge from an image captioning model and an ensemble of pre-trained CLIP models. This approach, inspired by offline knowledge distillation techniques, avoids the computational overhead of running large teacher models during training. Instead, it stores additional knowledge in a reinforced dataset, making training more efficient.
The implications of this research are profound, especially for consumer devices like upcoming iPhones. On-device AI technology like MobileCLIP means features like smarter image search, real-time visual look-up, better object detection, and new augmented reality experiences could work seamlessly without an internet connection. Imagine pointing your iPhone camera or looking through your Vision Pro at an unfamiliar plant or landmark and instantly getting information about it, all processed locally on your device for maximum speed and privacy.
Given Apple's continued research and innovation around AI models for mobile devices, we will likely see a new generation of intelligent, responsive, and privacy-preserving experiences on their consumer devices later this year. Advanced computer vision and language understanding could become standard features, working hand-in-hand with dedicated AI hardware. It's an exciting glimpse into a future where powerful AI isn't just cloud-bound but is woven into the very devices we carry with us every day.