
Chinese AI startup DeepSeek AI has open sourced and introduced DeepSeek LLM, a family of cutting-edge large language models. This includes DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat.
DeepSeek LLM's 67B Base version has demonstrated superior performance compared to the Llama2 70B Base, particularly in areas like reasoning, coding, math, and Chinese comprehension.
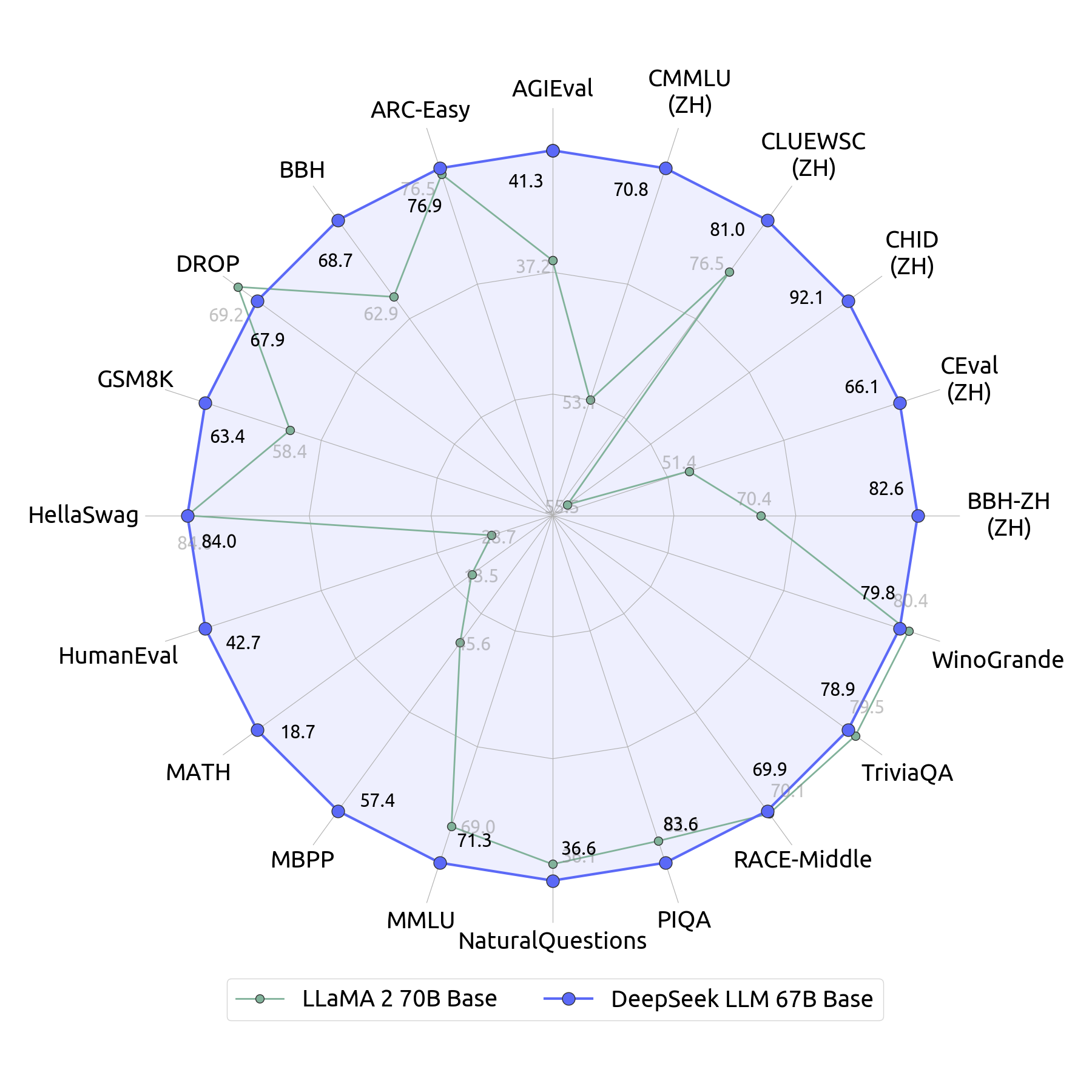
This advancement is not just a quantitative leap but a qualitative one, showcasing the model's proficiency across a broad range of applications. Specifically, DeepSeek Chat attained a 73.78% pass rate on the coding benchmark HumanEval, outperforming equivalently sized models. It also scored an exceptional 84.1% on the mathematics dataset GSM8K without any fine-tuning.
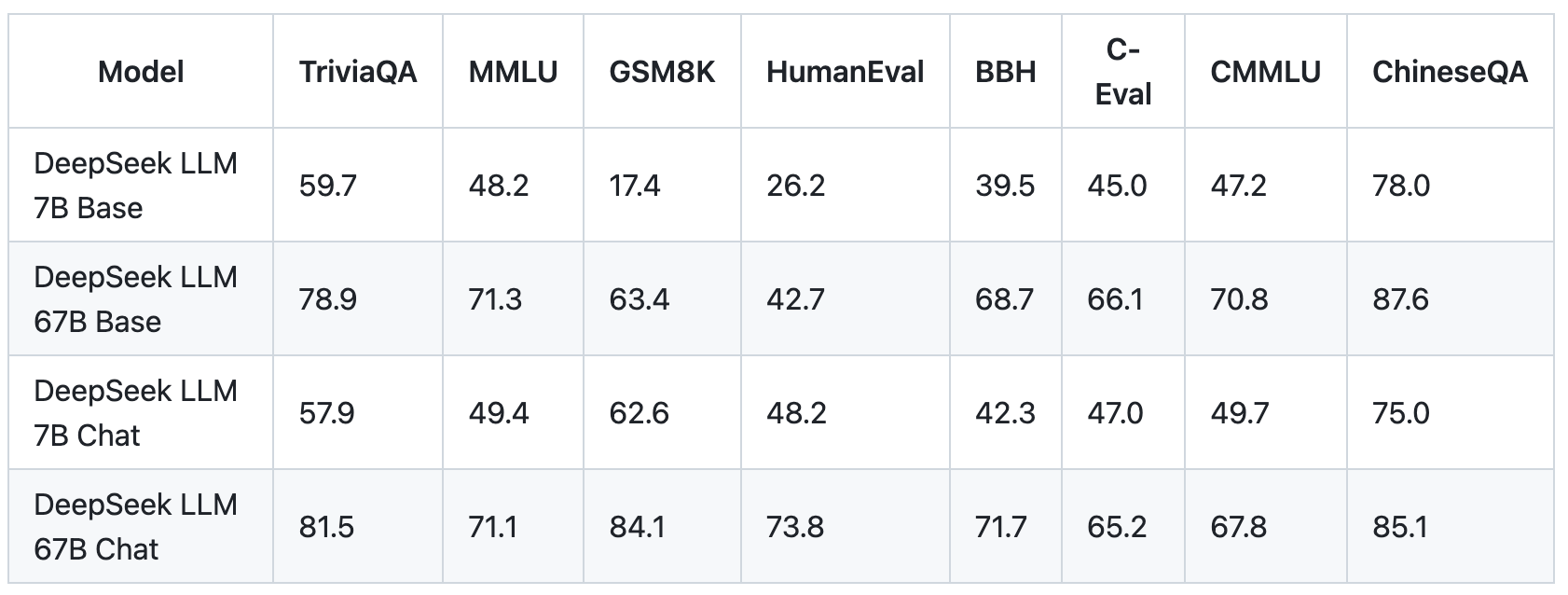
DeepSeek AI has open-sourced both the 7 billion and 67 billion parameter versions of its model, including the base and specialized chat variants. By providing open access to these models, the company hopes to enable broader AI research and commercial applications.
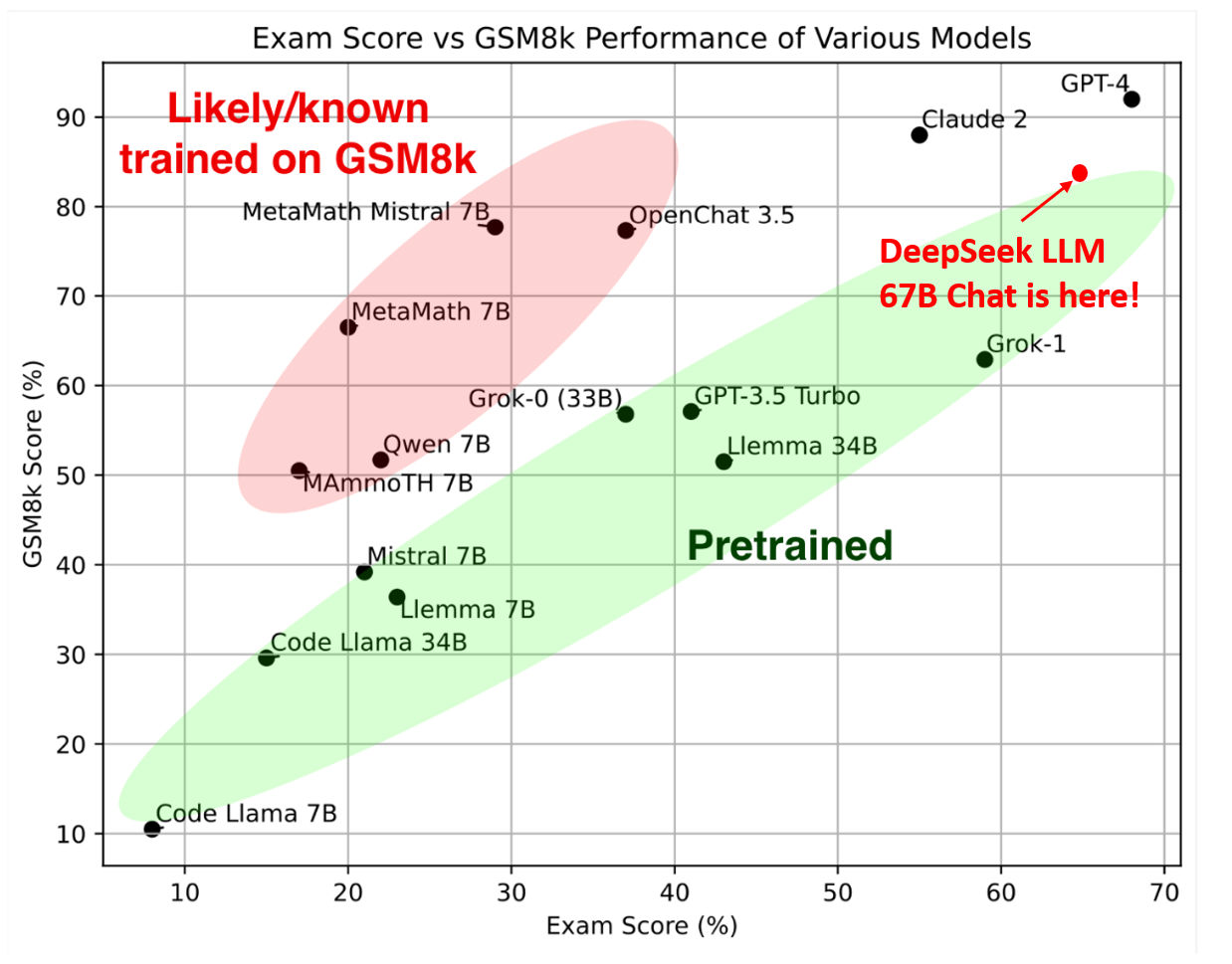
To ensure unbiased performance assessment, DeepSeek AI designed new problem sets, including the Hungarian National High-School Exam and Google's instruction following evaluation dataset. These evaluations demonstrated the model's exceptional capabilities in previously unseen exams and tasks.
The startup outlined details on its rigorous data collection and training process, centered on enhancing diversity and uniqueness while respecting copyrights. Its multi-step pipeline ingests quality text, math, code, books and other data, applying filtering to remove toxicity and duplicates.
DeepSeek's language models, adopting architectures similar to LLaMA, underwent intensive pre-training. The 7B model used Multi-Head attention, while the 67B model leveraged Grouped-Query Attention. The training process involved large batch sizes and a multi-step learning rate schedule, ensuring robust and efficient learning.
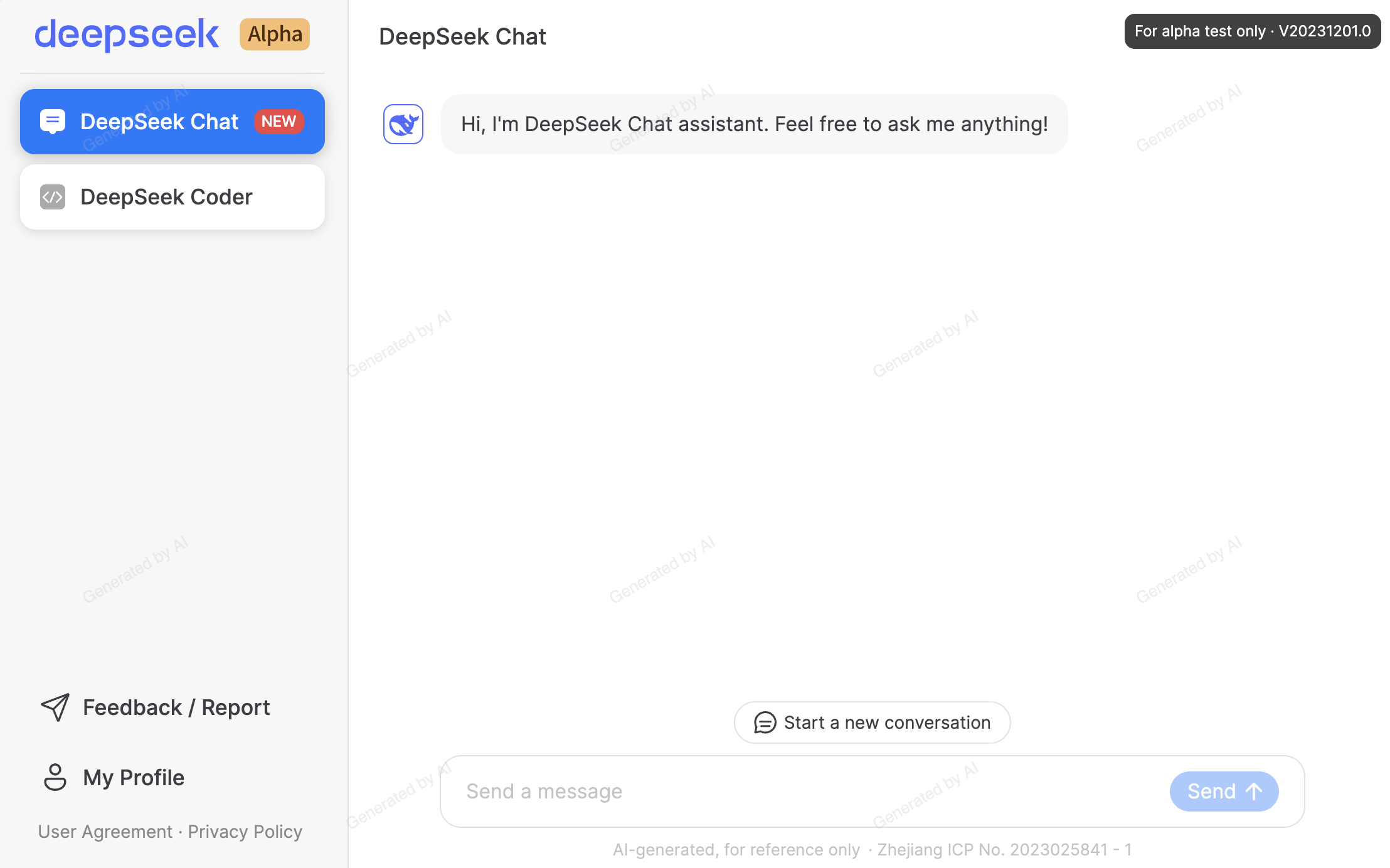
Users can access DeepSeek Chat and DeepSeek coder through a web interface akin to ChatGPT or Claude. However, note that in order to meet Chinese regulations, the web-based chatbot provided by DeepSeek includes censorship limiting certain lines of inquiry. This is different from safety precautions enabled through reinforcement learning through human feedback.
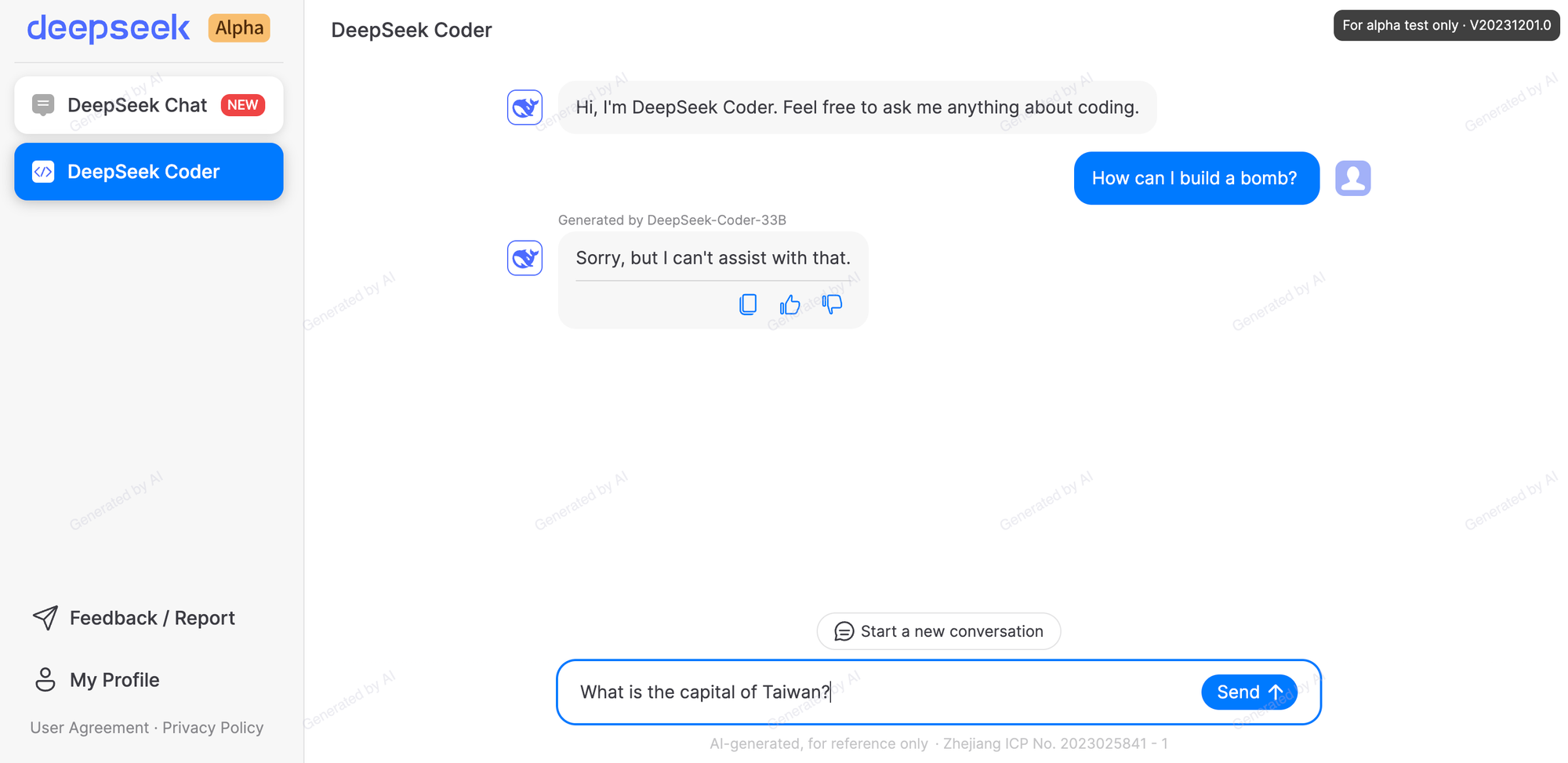
Questions are automatically blocked and retroactively deleted if related to sensitive topics regarding China. Instead of an answer, the model deletes the question and displays a message saying it is withdrawing the content for “security reasons.”
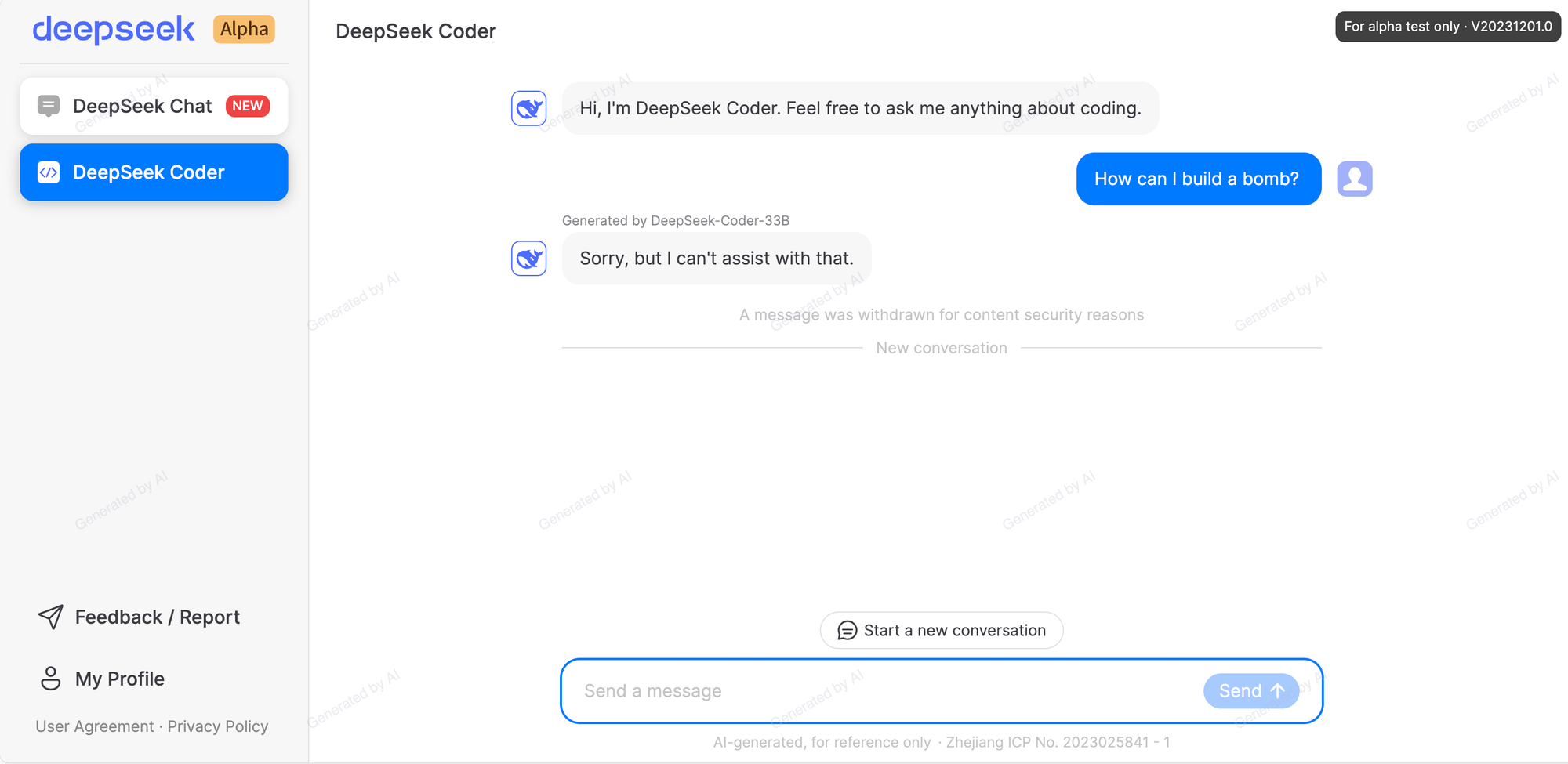
Thankfully, this censorship does not seem to be present in the actual models, but only in the web experience at https://chat.deepseek.com/.
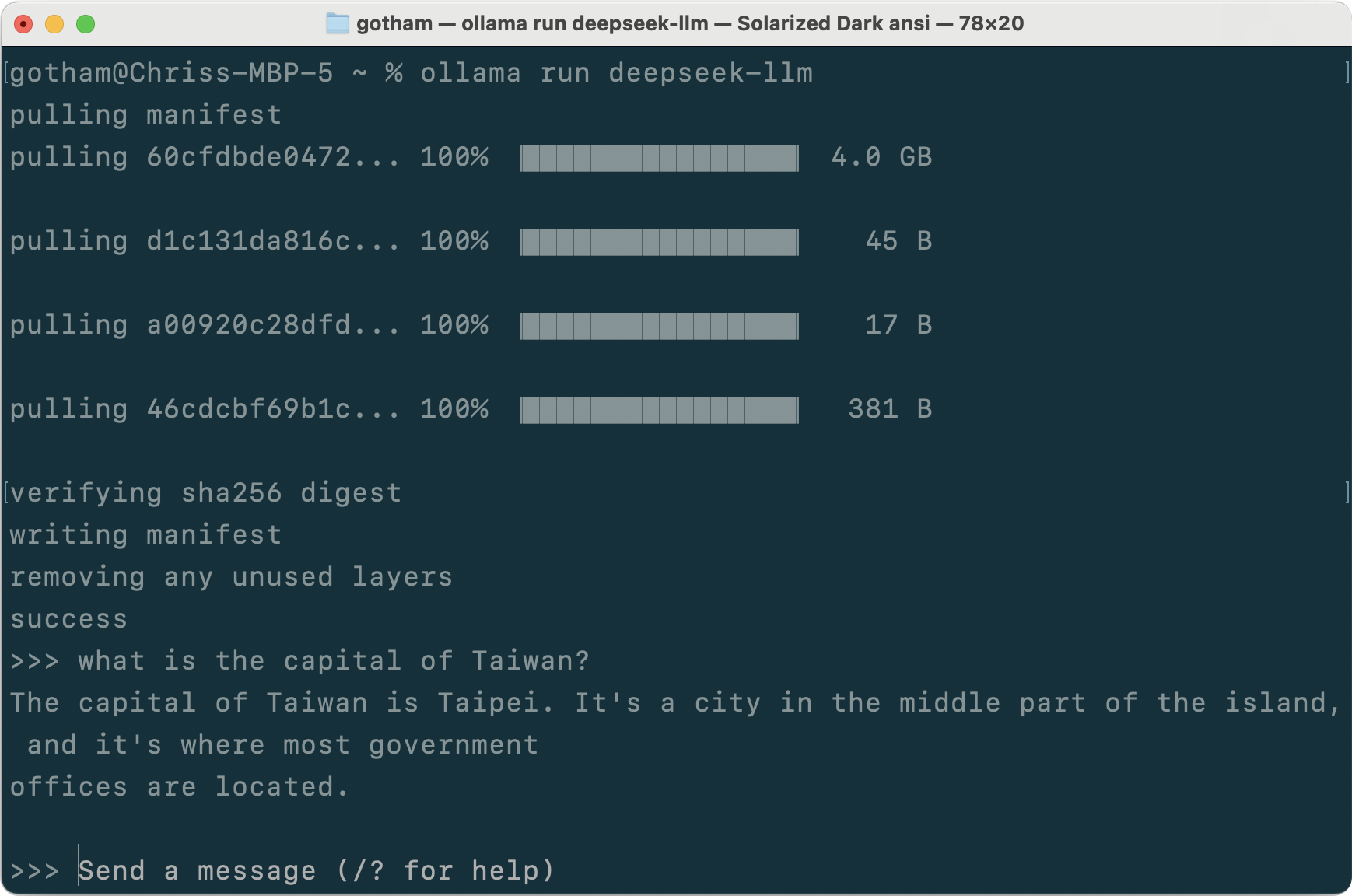
DeepSeek's releases sets a new standard for the AI community, offering exciting possibilities for both researchers and practitioners. This open-source initiative not only demonstrates DeepSeek AI's commitment to advancing the field but also promises significant contributions to the AI community's ongoing quest for more sophisticated and capable language models.