
Databricks has announced and released the weights for DBRX, a state-of-the-art large language model that outperforms established open-source models on various benchmarks. The company's goal is to make high-quality, customizable AI accessible to enterprises seeking to harness the power of generative AI.
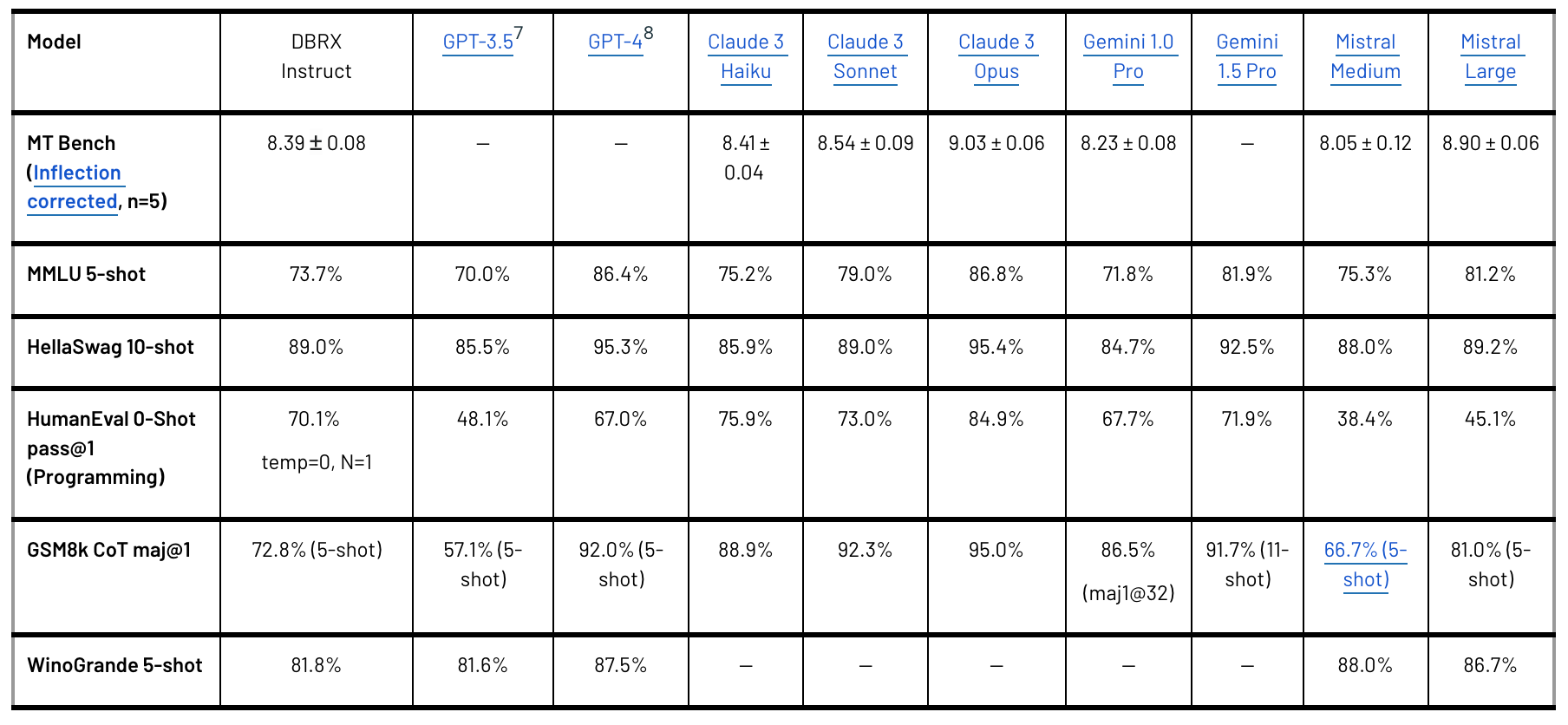
DBRX stands out for its impressive performance, surpassing models like LLaMA2-70B, Mixtral, and Grok-1 in language understanding, programming, math, and logic tasks. According to Databricks' open-source benchmark Gauntlet, DBRX leads in over 30 distinct state-of-the-art benchmarks, showcasing the continued improvement in the quality of open-source models.
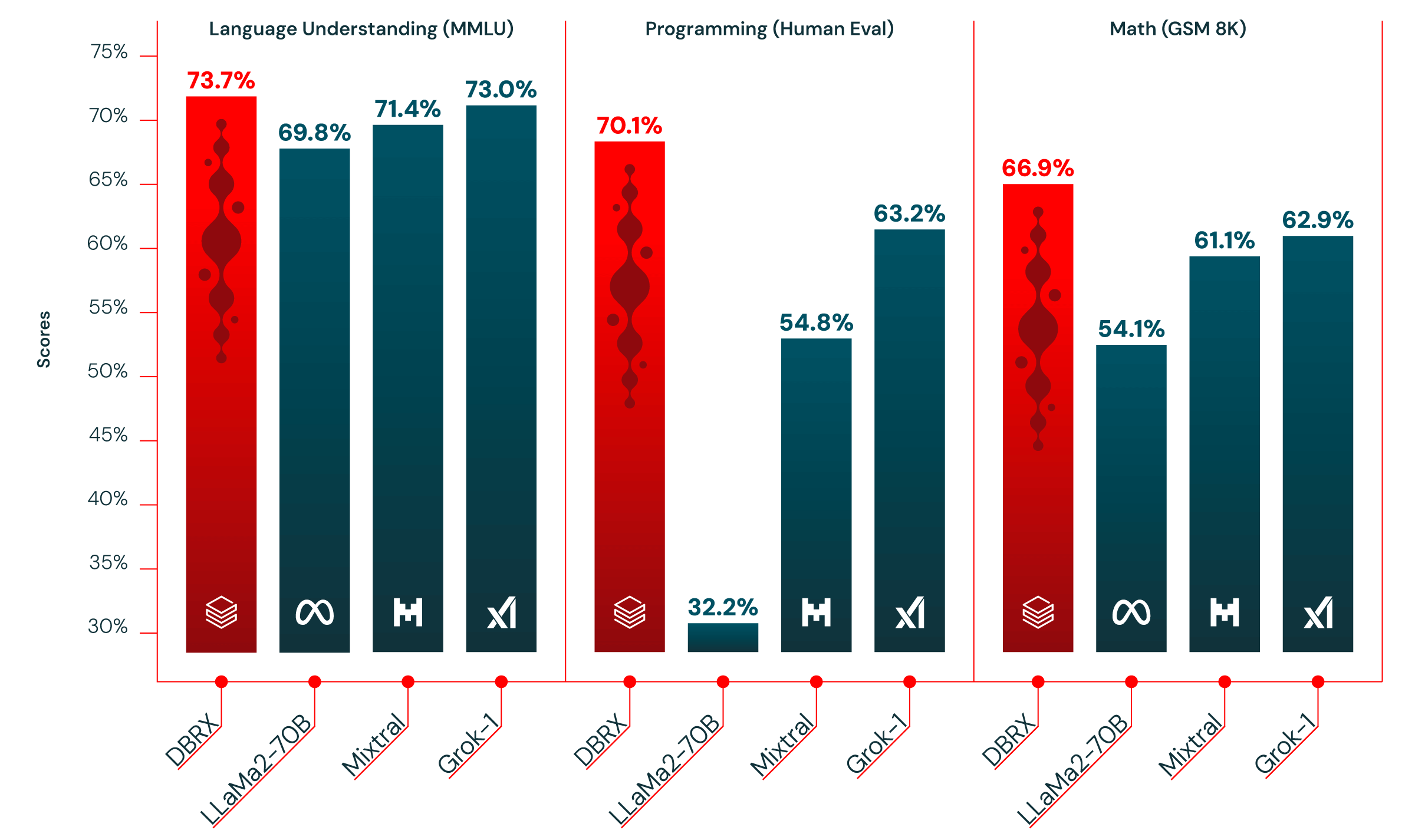
Notably, DBRX also outperforms GPT-3.5 on most benchmarks, which is particularly significant as enterprises increasingly replace proprietary models with open-source alternatives for better efficiency and control. Databricks has observed this trend among its 12,000+ customer base, with many achieving superior quality and speed by customizing open-source models for their specific tasks.
Another key aspect of DBRX is its Mixture-of-Experts (MoE) architecture, built on the MegaBlocks research and open-source project. This design allows for faster token generation while maintaining a relatively small active parameter count of 36 billion, compared to the model's total 132 billion parameters. The MoE architecture enables the training of larger models with faster throughput, offering the best of both worlds in terms of speed and performance.
Databricks trained DBRX with with up to a 32K token context window and built it entirely on its platform, using tools such as Unity Catalog for data governance, Apache Spark™ and Lilac AI for data processing and cleaning, and Mosaic AI Training service for large scale model training and fine-tuning.
Databricks designed DBRX to be easily customizable, empowering enterprises to improve the quality of their AI applications. Starting today, enterprises can interact with DBRX on the Databricks Platform, leverage its long context abilities in RAG systems, and build custom DBRX models on their private data. The model is accessible through Databricks' GitHub repository and Hugging Face (DBRX Base, DBRX Instruct). You can also try out the instruct model in the embedded Hugging Face Space below:
The weights of the base model (DBRX Base) and the finetuned model (DBRX Instruct) are available on Hugging Face under an open license. Starting today, DBRX is available for Databricks customers to use via APIs, and Databricks customers can pretrain their own DBRX-class models from scratch or continue training on top of one of our checkpoints using the same tools and science we used to build it.