
Google has announced two new additions to its Gemma family of lightweight, state-of-the-art open models: CodeGemma for code-related tasks and RecurrentGemma for research experimentation. Built upon the same technology used in the Gemini models, these variants aim to empower machine learning developers to innovate responsibly.
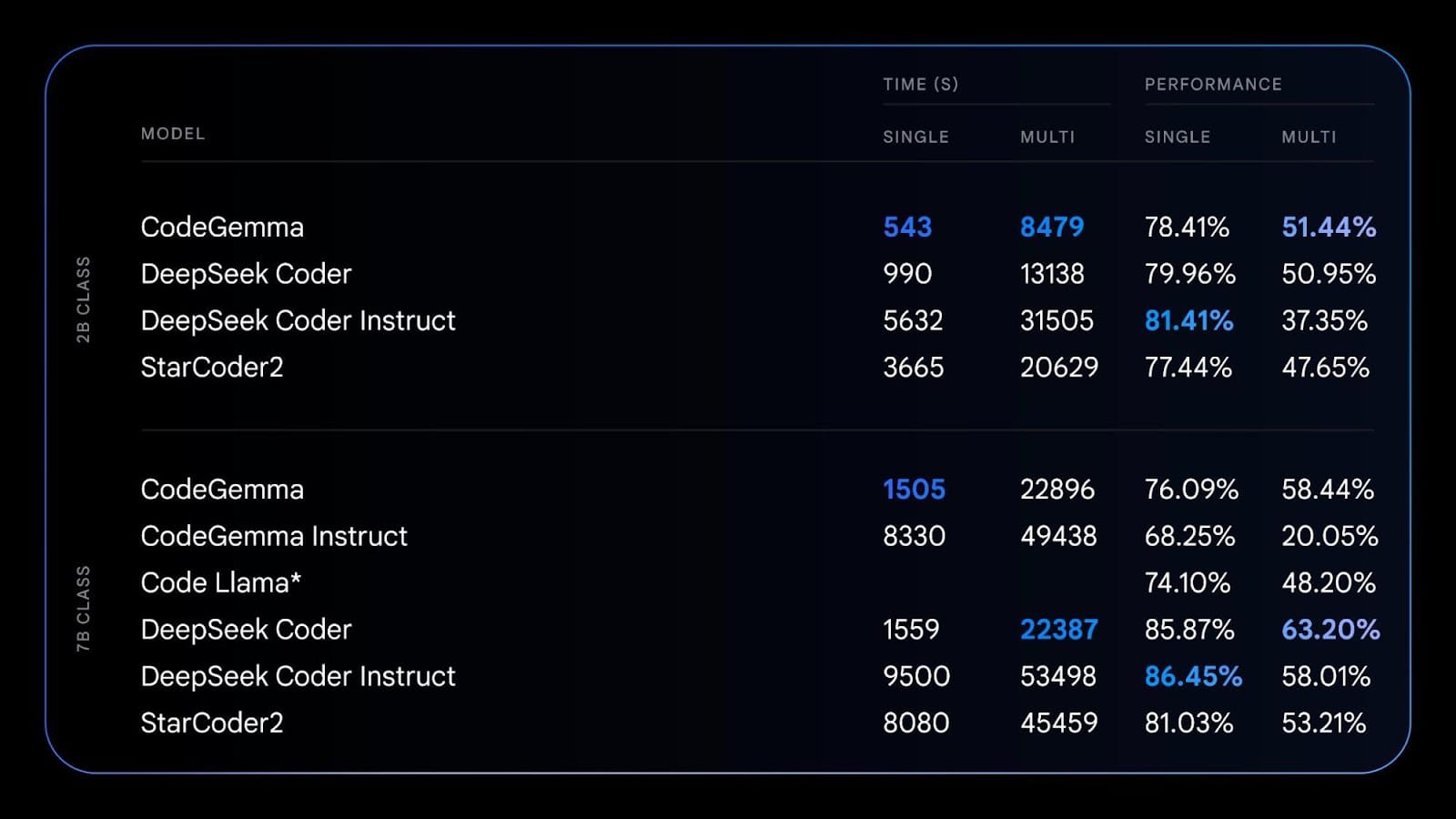
The first variant, CodeGemma, brings powerful coding capabilities in a lightweight package. Available in 7B pretrained, 7B instruction-tuned, and 2B pretrained variants, it excels at code completion, generation, and chat across popular languages like Python, JavaScript, and Java. With enhanced accuracy from training on 500 billion tokens of web documents, mathematics, and code, CodeGemma generates semantically meaningful code to reduce errors and debugging time. Developers can integrate it into their workflows to streamline writing boilerplate code and focus on differentiated code faster.
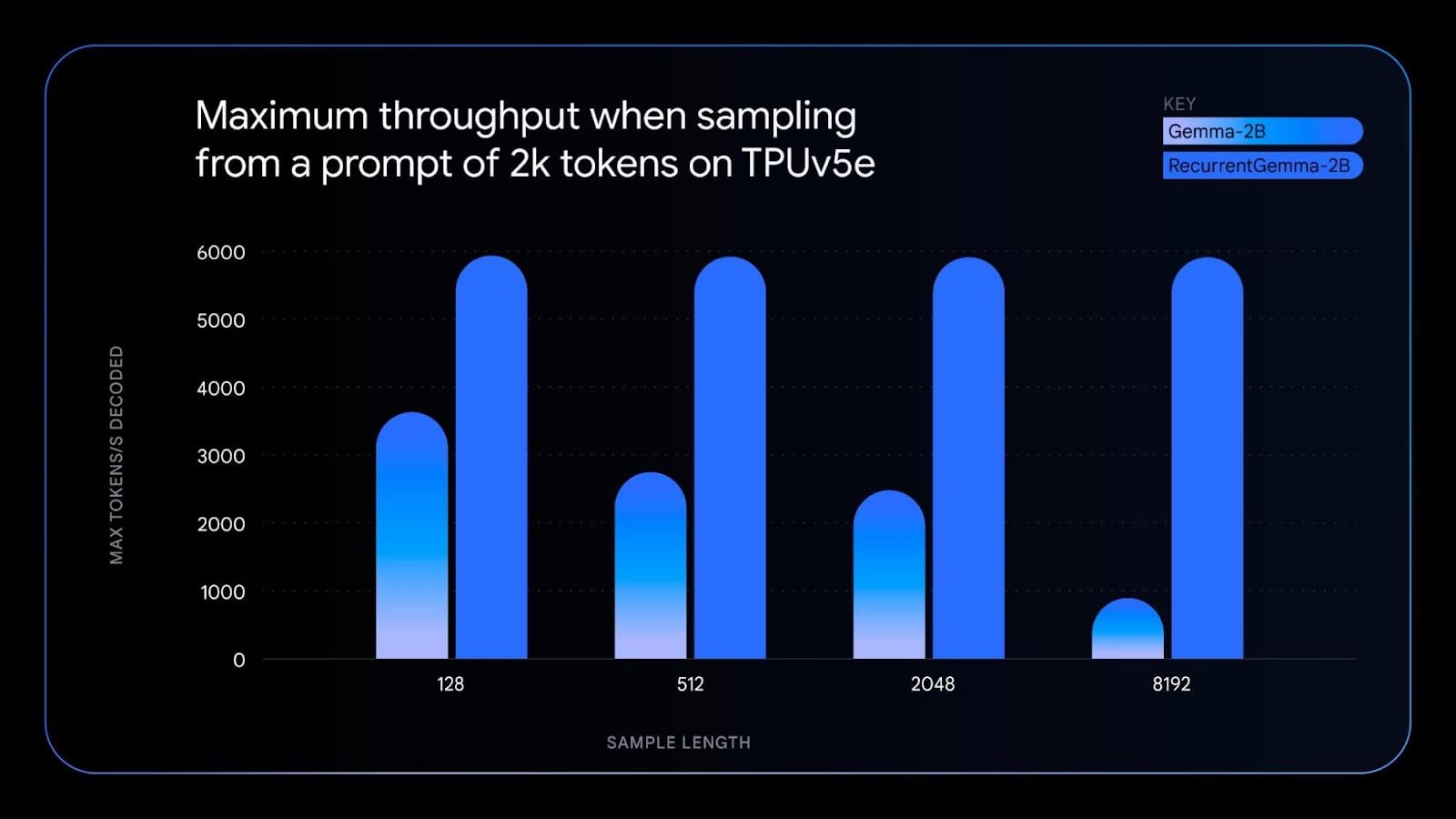
The second variant, RecurrentGemma, leverages recurrent neural networks and local attention for improved memory efficiency. While achieving similar benchmark scores to the Gemma 2B model, its unique architecture reduces memory usage, enables higher throughput, and allows for longer sample generation on resource-constrained devices. RecurrentGemma's ability to maintain sampling speed regardless of sequence length sets it apart from Transformer-based models like Gemma, which slow down with longer sequences. This model variant showcases advancements in deep learning research with a non-transformer architecture.
Both CodeGemma and RecurrentGemma uphold the principles of the original Gemma models, including open availability, high performance, responsible design, and flexibility across diverse software and hardware. They are compatible with various tools and platforms such as JAX, PyTorch, Hugging Face Transformers, and Gemma.cpp. CodeGemma also supports Keras, NVIDIA NeMo, TensorRT-LLM, Optimum-NVIDIA, and MediaPipe, with availability on Vertex AI.
Alongside these new variants, Google has released Gemma 1.1, which includes performance improvements, bug fixes, and updated terms based on developer feedback. The models are available starting today on Kaggle, Hugging Face, and Vertex AI Model Garden.