
Google made two significant announcements today aimed at massively boosting the compute power available for developing cutting-edge AI models. The company unveiled Cloud TPU v5p, its next generation tensor processing unit (TPU) chip delivering major leaps in speed and scale for training large language models and other demanding workloads. Additionally, Google introduced AI Hypercomputer, a new cloud infrastructure optimized from the silicon up for efficiently running AI workloads.
Together, these launches represent Google's latest move to stay ahead of the relentless growth in AI model size and data demands. Over the past five years, the number of parameters in leading generative AI models has increased by 10x annually. Training these models, which can contain hundreds of billions or even trillions of parameters, requires specialized systems spanning months in some cases.
Google's new TPU v5p aims to slash these training times using the company’s most advanced TPU architecture yet. Each TPU v5p-based pod contains 8,960 chips, allowing customer models to scale to unprecedented sizes. Compared to the previous generation TPU v4, the v5p delivers more than 2x higher floating point operations per second (FLOPs) and 3x greater high-bandwidth memory. For large language model workloads, TPU v5p also trains 2.8x faster than its predecessor.
The new chip generation also flexes improved versatility through its second-generation sparsity technology. This innovation accelerates performance on embedding-heavy models by 1.9x versus the prior version, adapting TPU v5p to a broader range of cutting-edge AI applications.
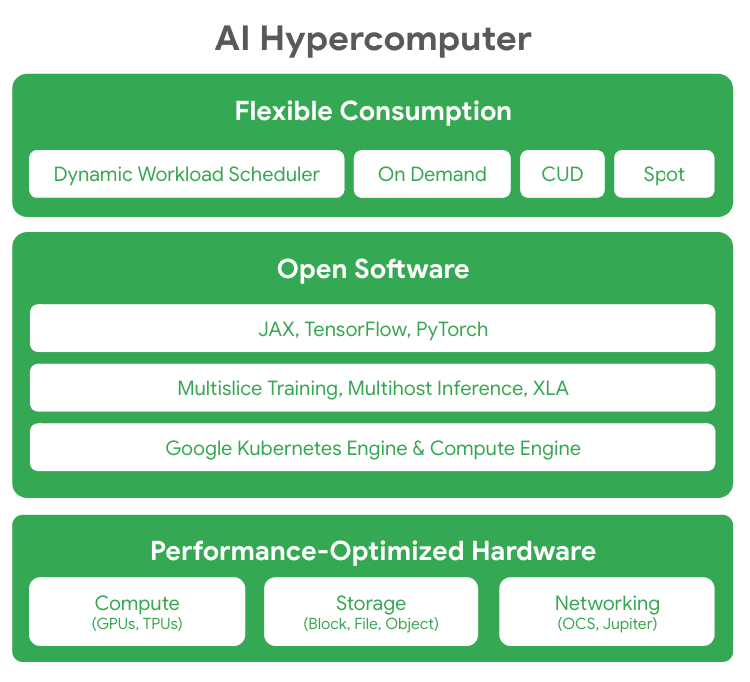
Complementing the upgraded hardware, AI Hypercomputer provides the surrounding cloud infrastructure and tooling for customers to utilize TPU v5p and run models at Google-level scale. The company describes its hypercomputer concept as "a groundbreaking supercomputer architecture” employing extensive software and systems optimization. Key components include high-density data centers with liquid cooling, Kubernetes integrations, and flexible pricing models tailored to AI workloads.
Early adopters Salesforce and Lightricks are already reporting considerable improvements training models on TPU v5p-powered hypercomputer resources. Salesforce saw 2x faster training over the previous TPU generation, while Lightricks praised v5p’s “remarkable performance” for rapidly iterating text-to-video models. Meanwhile, Google DeepMind and Google Research observed similar 2x speedups over TPU v4.
With TPU v5p and AI Hypercomputer, Google Cloud aims to massively crank up the dial on AI innovation by providing next-generation infrastructure for enterprises, researchers, and developers. If Moore’s Law continues advancing apace, even more powerful generations of TPUs and optimized cloud systems likely await in the future.