Google today publicly unveiled Gemini 2.5 Computer Use, a specialized variant of Gemini 2.5 Pro designed to operate graphical user interfaces (GUIs) rather than just consuming APIs. This move bridges a longstanding gap in agentic systems: the ability to “see” a UI and act on it much like a human user would.
Key Points
- Gemini 2.5 Computer Use enables AI agents to execute literal UI actions (click, type, scroll, manipulate dropdowns) within a browser loop.
- In internal and third-party benchmarks, it outperforms existing browser-control alternatives on accuracy and latency.
- It’s currently optimized for web and mobile interface tasks—not yet OS-level desktop control.
- Safety and guardrail features are built in, with per-step checks and developer control over sensitive actions.
For years, AI agents have struggled when faced with interfaces not designed for machines: think customized web portals, legacy dashboards, or mobile apps lacking APIs. Gemini 2.5 Computer Use addresses that by embedding “vision + action” into the agent workflow.
Developers feed the model three key inputs: the user’s intent, a screenshot of the UI, and a recent action log. The agent then proposes the next UI operation (e.g. “click this button”, “enter text here”). Once executed client-side, a fresh screenshot and URL are fed back, restarting the loop until the task is done or needs human intervention.
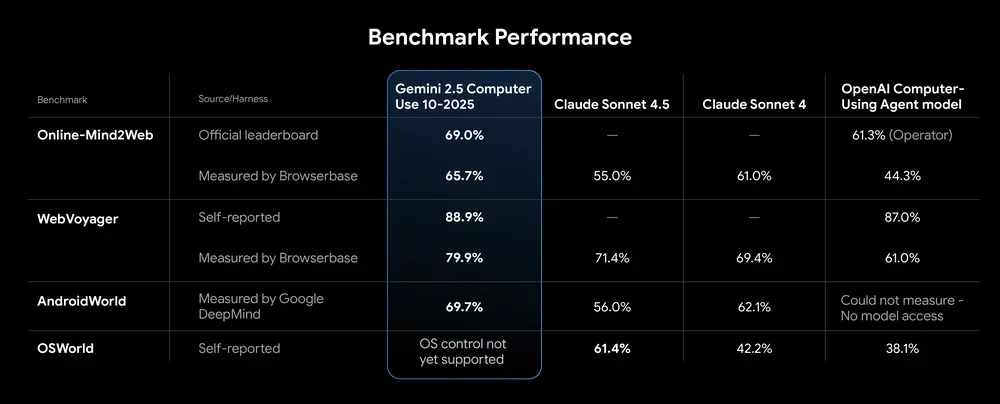
In internal tests, Google positions the model as not just accurate but fast. On benchmarks like Browserbase’s web control tasks, Gemini 2.5 Computer Use hits lower latency and higher success rates than competing solutions. While the model demonstrates promise on mobile UI tasks, Google is explicit that it’s not yet tuned for full desktop OS control.
From a product standpoint, this unlocks new automation possibilities: onboarding tools that must click and configure settings behind multiple screens, automated form filling in environments lacking APIs, UI testing that self-corrects, and agents that navigate complex third-party dashboards as humans would. Early use cases already cited include the agentic layers in Google’s own AI Mode, Project Mariner, and internal UI testing tooling.
That said, the new capability carries inherent risks. Automatic UI control opens up attack vectors: accidental clicks, phishing mimicry, or prompt injection hacks behind the same interfaces. To mitigate, Google layers in a per-step safety service and gives developers the option to require end-user confirmation for risky actions (such as purchases or system modifications).
One interesting aspect: Google exposes this via a new computer_use tool in its Gemini API, usable through Google AI Studio or Vertex AI. If you'd like to try it, the open-source Browserbase project offers a playground where folks can watch the model execute browser tasks from natural language prompts.
It’s worth flagging limitations:
- Because the model works via UI inference, its reliability may degrade in rapidly changing or dynamically styled interfaces.
- It may struggle in environments with heavy JavaScript frameworks or nonstandard UI components.
- The safety guarantees are only as robust as the developer’s configuration; missteps could induce unintended actions.
- It’s not (yet) a general OS controller: tasks like file system operations, window management, or native apps remain out of reach.
For business leaders, the takeaway is that we’re inching closer to agents that don’t just compute, but operate digital environments autonomously. That shift presents both opportunity (automation across non-API tools) and risk (governance, error control, auditing).