
IBM today unveiled the third generation of their Granite ecosystem of tools tailored for a wide range of enterprise use-cases, and aimed at making generative AI scalable, safe, and commercially viable for enterprise deployment. Granite 3.0 is the company's most advanced offering yet, featuring new language models, enhanced AI guardrails, and a mix of innovations that address real-world business needs.
IBM says their Granite 3.0 models are purpose-built for the modern enterprise—combining performance, customization, and responsible AI practices. Beyond that, the company is being deliberate in addressing some of the biggest concerns that enterprises often raise about frontier models from OpenAI, Anthropic, Google and Meta. This includes transparency about training data and methodologies, indemnification from IBM, and full commercial rights, which collectively lower the barriers for enterprises to safely integrate these powerful AI models into their workflows.
The release includes multiple models tuned for different use cases, such as Granite-3.0-8B-Instruct and Granite-3.0-2B-Instruct, which are designed to support enterprise AI tasks like retrieval-augmented generation (RAG), advanced reasoning, and code generation. Granite models can be fine-tuned using proprietary enterprise data, allowing companies to get highly specialized performance at a fraction of the cost.
To be clear, these models are not intended to compete with the large frontier models like GPT-4, Claude Opus, Llama 3 405B, and Gemini Pro. The largest Granite model is only 8B parameters, so by many measures, these models could be considered small language models.

The full Granite 3.0 family includes:
- General Purpose/Language:
Granite 3.0 8B Instruct,Granite 3.0 2B Instruct,Granite 3.0 8B Base,Granite 3.0 2B Base - Guardrails & Safety:
Granite Guardian 3.0 8B,Granite Guardian 3.0 2B - Mixture-of-Experts:
Granite 3.0 3B-A800M Instruct,Granite 3.0 1B-A400M Instruct,Granite 3.0 3B-A800M Base,Granite 3.0 1B-A400M Base - Accelerated inference:
Granite-3.0-8B-Instruct-Accelerator - Granite Time Series Tiny Time Mixer:
TTM-R1,TTM-R2
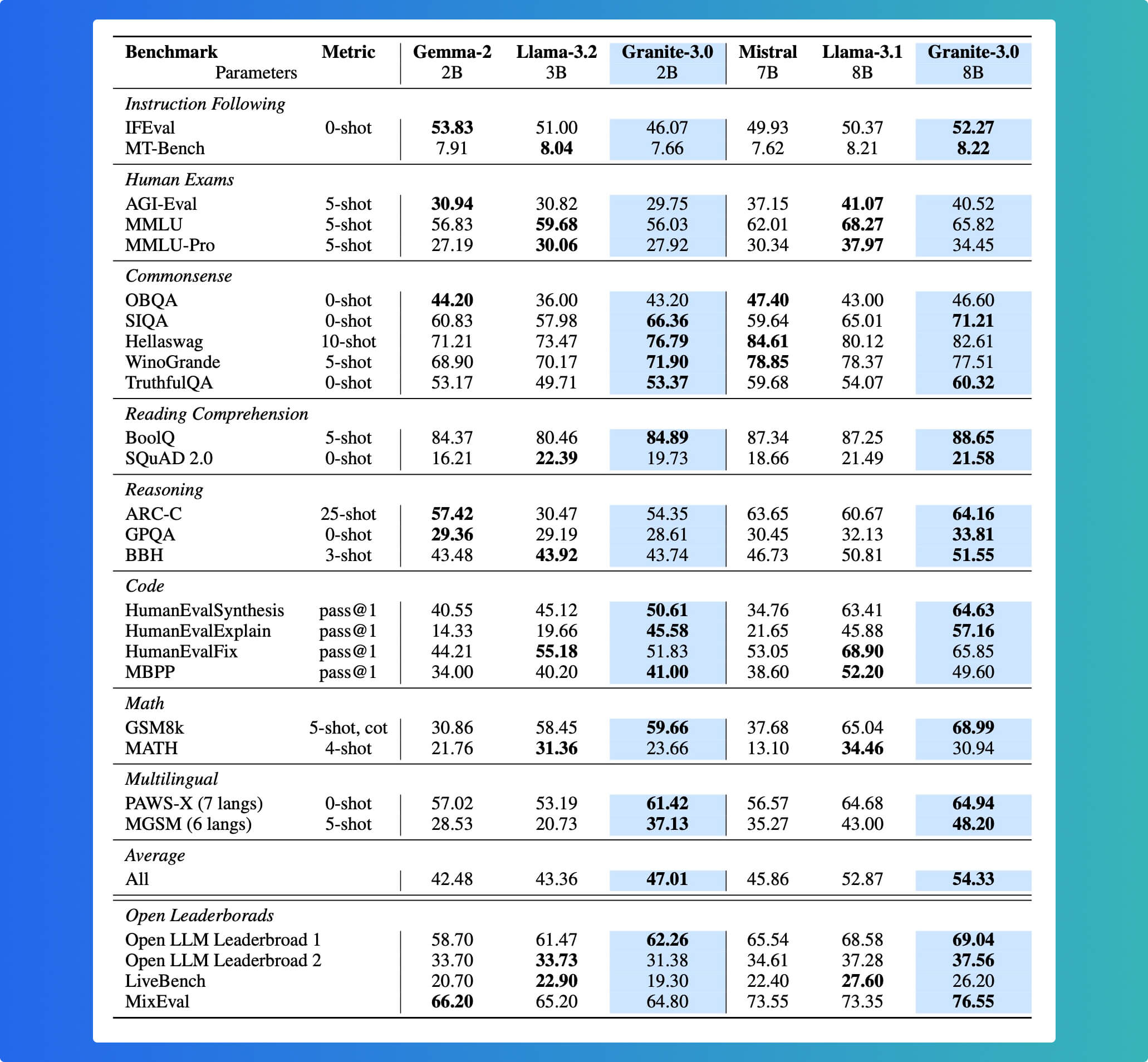
The Granite 3.0 8B Instruct model was trained on over 12 trillion tokens across 12 natural languages and 116 programming languages. It shows impressive performance on both academic benchmarks and real-world enterprise applications, rivaling or surpassing similar-sized models from competitors like Meta and Mistral AI.
The Granite Guardian 3.0 model suite is specifically focused on mitigating AI risks by monitoring user prompts and outputs for bias, violence, profanity, and other harmful content. Early tests suggest these models outperform Meta's LlamaGuard, showcasing superior performance across a wide range of safety and bias detection benchmarks.
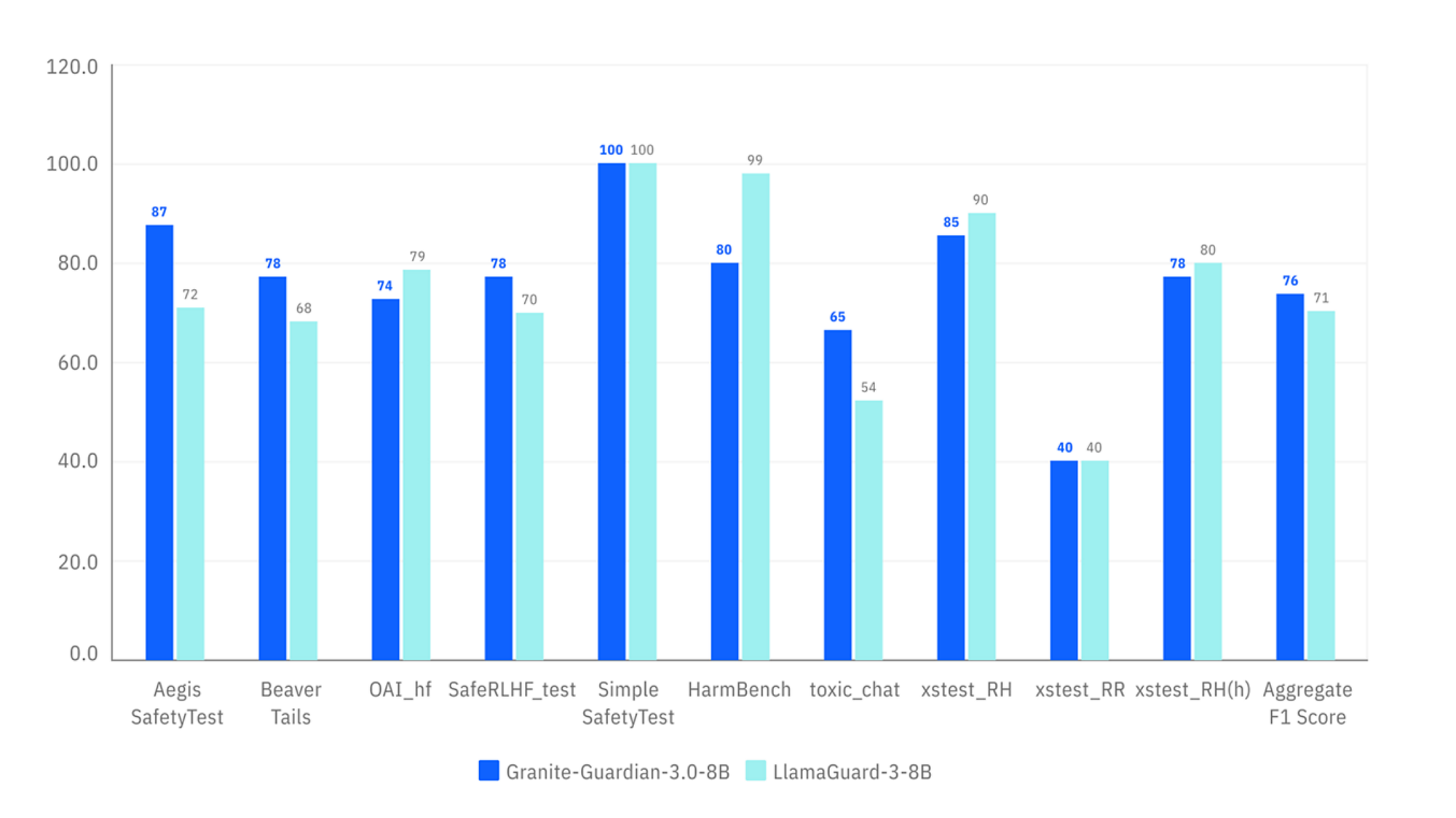
With capabilities for preventing jailbreaking and ensuring the factuality of outputs in RAG workflows, the Granite Guardian models offer enterprises a reliable tool for maintaining ethical standards while deploying AI solutions.
Another standout release is the introduction of Granite Accelerators, which utilize speculative decoding to significantly reduce latency and improve throughput. The Granite-3.0-8B-Instruct-Accelerator model achieves twice the inference speed compared to standard methods, thanks to advanced speculative techniques that streamline token prediction.
This approach allows enterprises to implement Granite models in more demanding real-time environments, such as customer service bots or on-device applications, providing quick responses without compromising the quality of the output.
IBM also unveiled the first-generation Granite Mixture-of-Experts (MoE) models, which offer high efficiency at minimal tradeoffs. These lightweight models (1B and 3B parameters) run with fewer parameters during inference, making them ideal for low-resource environments while still maintaining robust performance levels. With Granite MoE, IBM is targeting on-device and edge deployments—areas where compute resources are constrained, but AI-driven decisions are still required.
The release also includes an updated version of Granite Time Series models, which are compact (1-3 million parameters) pre-trained models for multivariate time-series forecasting. Known as Tiny Time Mixers (TTMs), these models can run on CPU-only machines, support both channel independence and channel-mixing approaches, and excel at zero-shot and few-shot forecasting by utilizing over 700 million time points from publicly available datasets. Impressively, these models have outperformed competitors more than 10 times their size on several benchmark datasets.
Lastly, the deployment versatility of the Granite models makes them highly attractive for enterprises. They can be run on a wide range of platforms, including on IBM's watsonx, NVIDIA NIM, Hugging Face, Google Cloud's Vertex AI Model Garden, and even locally on laptops using Ollama.
IBM's latest AI offerings clearly target enterprises that need scalable, safe, and effective AI tools. With the inclusion of comprehensive safety measures through Granite Guardian, enhanced efficiency via speculative decoding, and the adaptability of MoE architectures, IBM is catering to organizations looking to integrate AI into mission-critical systems without sacrificing speed or safety.
Granite 3.0 is also a statement about IBM's commitment to the responsible use of AI. By offering transparency in data usage, open-source licensing, and indemnification, IBM is setting a standard for AI models that are powerful yet governed with enterprise concerns in mind.
In practical terms, Granite 3.0 models are well-suited for tasks like cybersecurity, code generation, and customer service. With models like Granite Guardian taking the lead in safety and the Granite Accelerators enhancing speed, these tools bring a balance of reliability and efficiency that enterprises require. IBM’s Consulting Advantage platform is also integrating Granite as its default model, empowering IBM consultants to better serve clients with AI-powered insights.
The models are available on a wide range of platforms, including on IBM's watsonx, Nvidia NIM, Hugging Face, Google Cloud's Vertex AI Model Garden, and some can even run locally on laptops using Ollama. This flexibility makes Granite 3.0 accessible to a broad audience, from enterprise environments to individual developers looking for convenient on-device AI capabilities.
As the adoption of AI continues to surge across industries, IBM is focusing on providing not just the technology but the guardrails and assurances that enterprises need to move forward confidently. Granite 3.0 represents a carefully balanced mix of innovation, efficiency, and ethical governance—a combination that is likely to resonate well with enterprises navigating the complex landscape of AI adoption.