
As large language models like GPT-4 and Gemini continue to advance, researchers are exploring ways to make their predictions more reliable for real-world applications. Confidence calibration remains a major obstacle, as even top-performing models can generate convincingly fluent but inaccurate text.
To address this challenge, Google AI has introduced a new framework called "ASPIRE". ASPIRE stands for Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs. The core idea is to train models to better evaluate the correctness of their own responses on question answering tasks via targeted fine-tuning.
Rather than relying on hand-designed heuristics, ASPIRE exposes models to training data so they learn to distinguish correct versus incorrect answers internally. This self-assessment capability comes from three key stages: task-specific tuning to boost accuracy, sampling high-likelihood candidate answers, and specialized training so models can effectively label these candidates as accurate or not.
Additionally, ASPIRE enables models to output an uncertainty warning like "I don't know!" along with the prediction if the confidence score is low. For instance, if the selection score is just 0.1, indicating doubt in the answer, the LLM can further respond with "I don't know!" to caution users against trusting the output and suggest verifying it via other sources. This transparent signaling of potential inaccuracies serves as an additional reliability safeguard.

Experiments demonstrate ASPIRE significantly outperforms existing selective prediction methods across various question-answering datasets like CoQA, TriviaQA, and SQuAD. Notably, on the CoQA benchmark, ASPIRE improved the Area Under Accuracy-Coverage Curve (AUACC) from 91.23% to 92.63% and the Area Under the Receiver Operating Characteristic Curve (AUROC) from 74.61% to 80.25%.
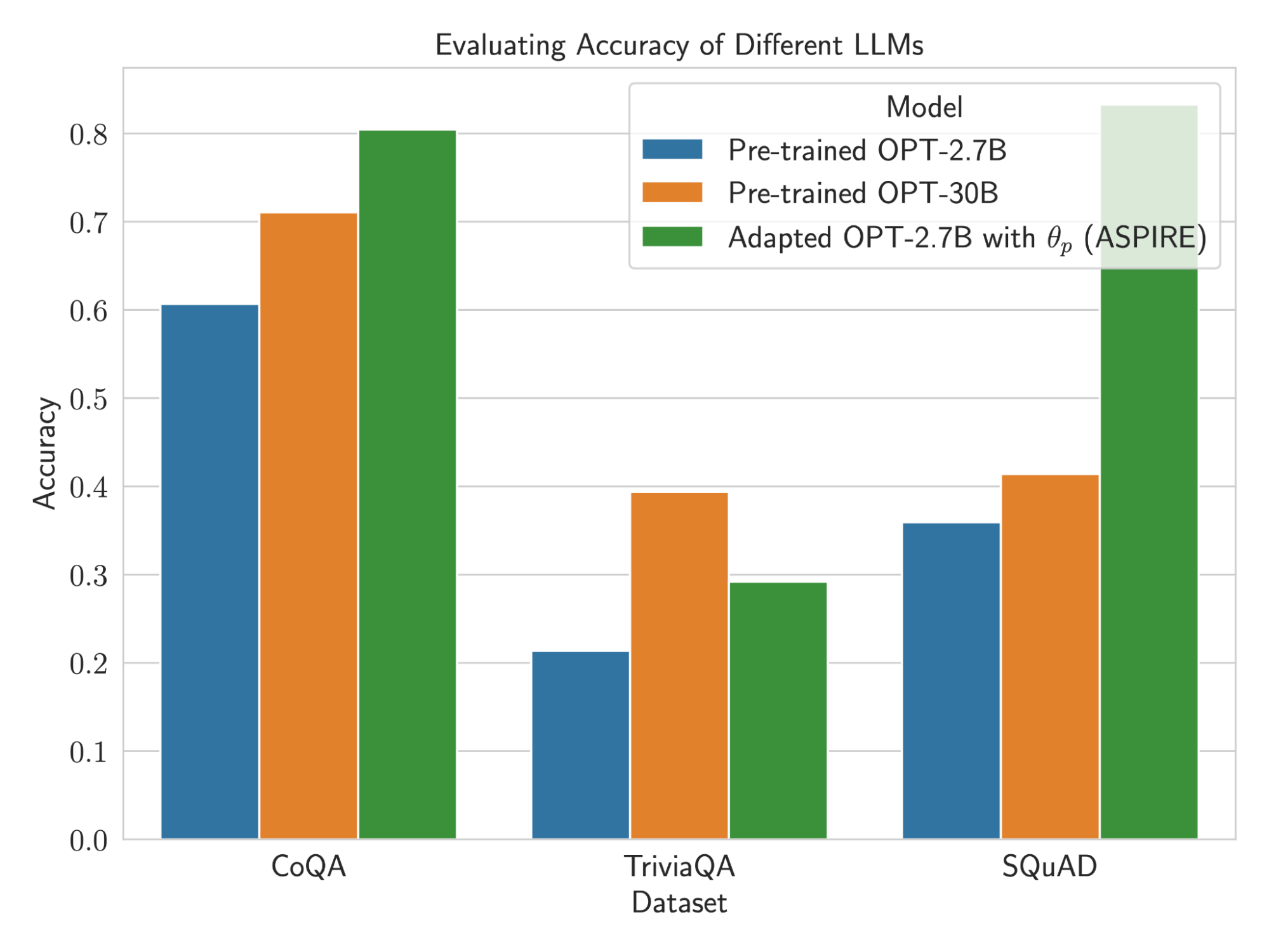
Intriguingly, smaller models enhanced with ASPIRE also exceeded the selective prediction prowess of larger default models in some cases. The researchers suggest specialized self-evaluation training may prove more valuable than scale for particular applications needing to identify the certainty of model-generated text.
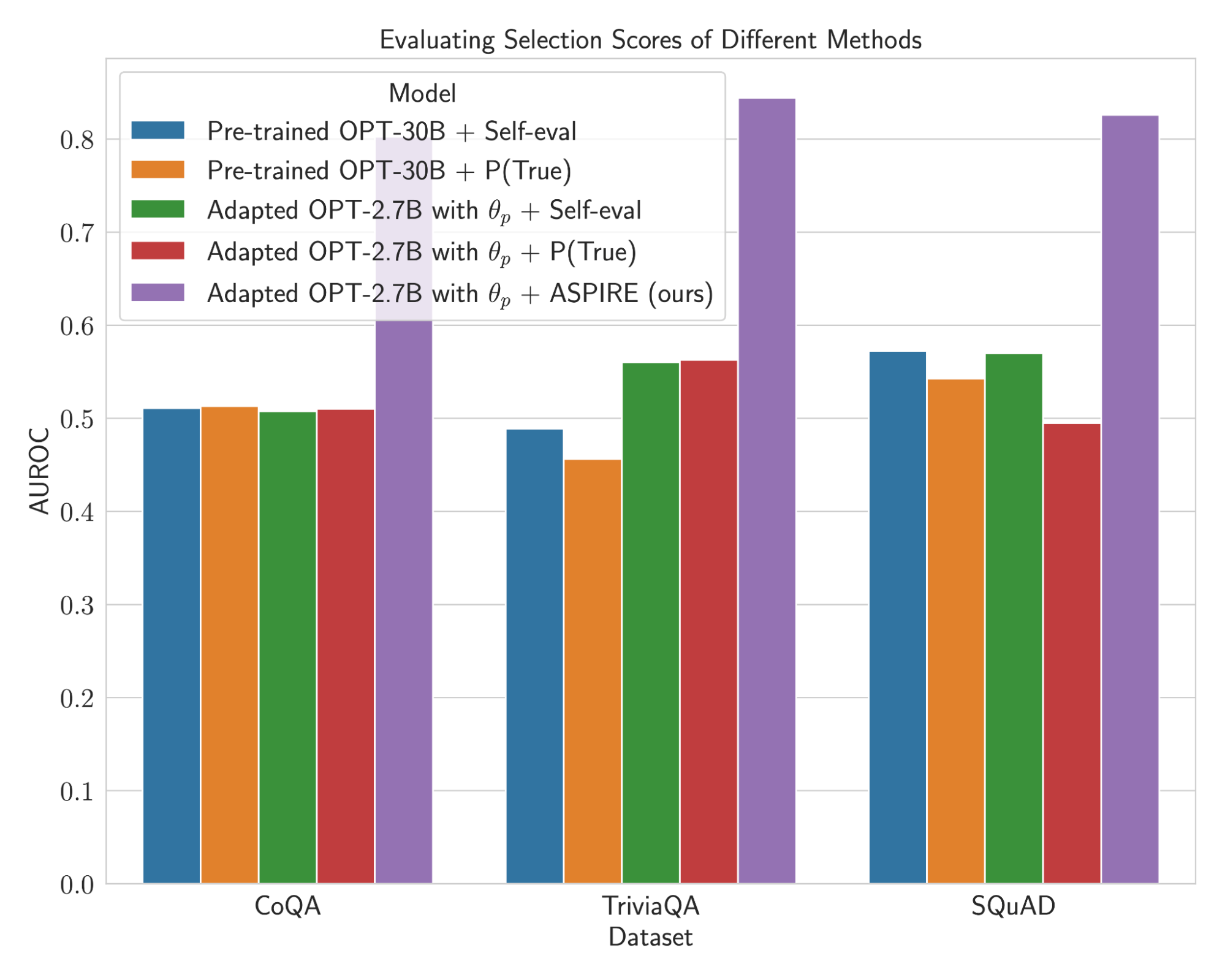
ASPIRE's success in enhancing LLM reliability opens new avenues for their application in critical decision-making fields. The ability of LLMs to discern the accuracy of their predictions holds immense potential in healthcare, legal, and other sensitive sectors where precision is paramount. Boosting self-awareness could complement ongoing advances in underlying model quality on the road to reliable AI.