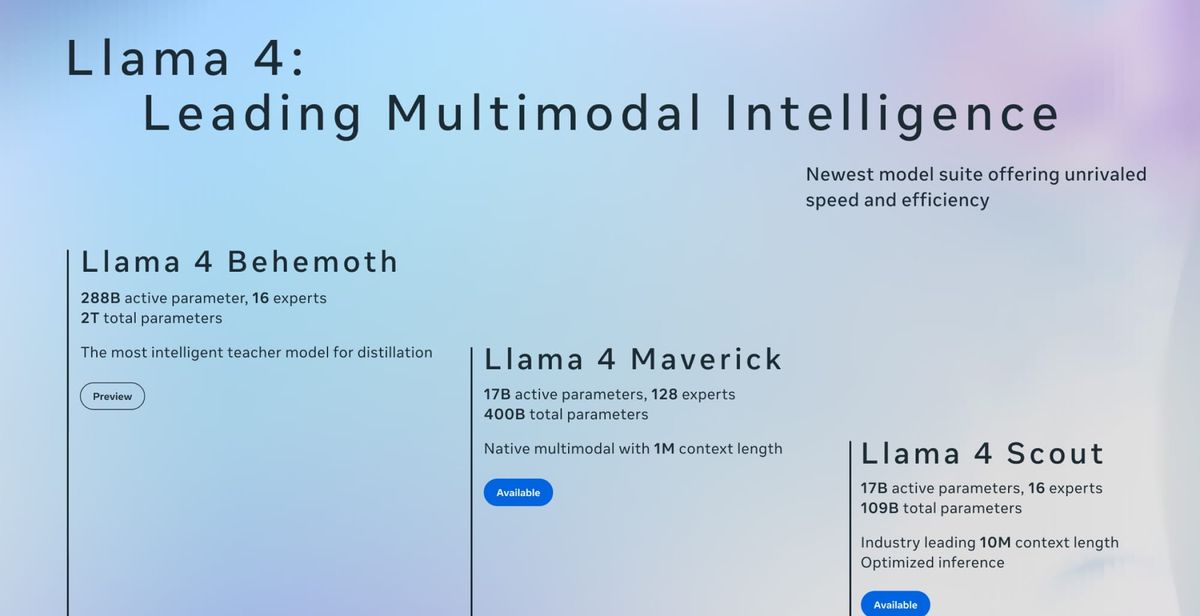
Meta has launched its most advanced AI models yet with the introduction of Llama 4, natively multimodal AI models that leverage a mixture-of-experts architecture to offer industry-leading performance in text and image understanding.
Key Points:
- Two new open-weight models: Llama 4 Scout (16 experts) and Maverick (128 experts), both with 17B active parameters.
- Maverick outperforms GPT-4o on reasoning, coding, and vision tasks—with half the parameters of DeepSeek V3.
- Scout offers a 10M token context window, best in class for long-context tasks like summarizing huge codebases.
- Both are distilled from Llama 4 Behemoth, a 288B-parameter research model still in training.
When Meta CEO Mark Zuckerberg first started talking about open-source AI, skeptics questioned whether the company could meaningfully challenge the closed models from OpenAI and Google. With Llama 3, and today's announcement of the Llama 4 family, those doubts seem increasingly misplaced.
The latest lineup introduces two models available immediately - Llama 4 Scout and Llama 4 Maverick - while teasing a much larger model still in training called Llama 4 Behemoth. This is Meta's first foray into mixture-of-experts (MoE) architecture, a technique that activates only a fraction of a model's total parameters for any given input, resulting in substantial efficiency gains.
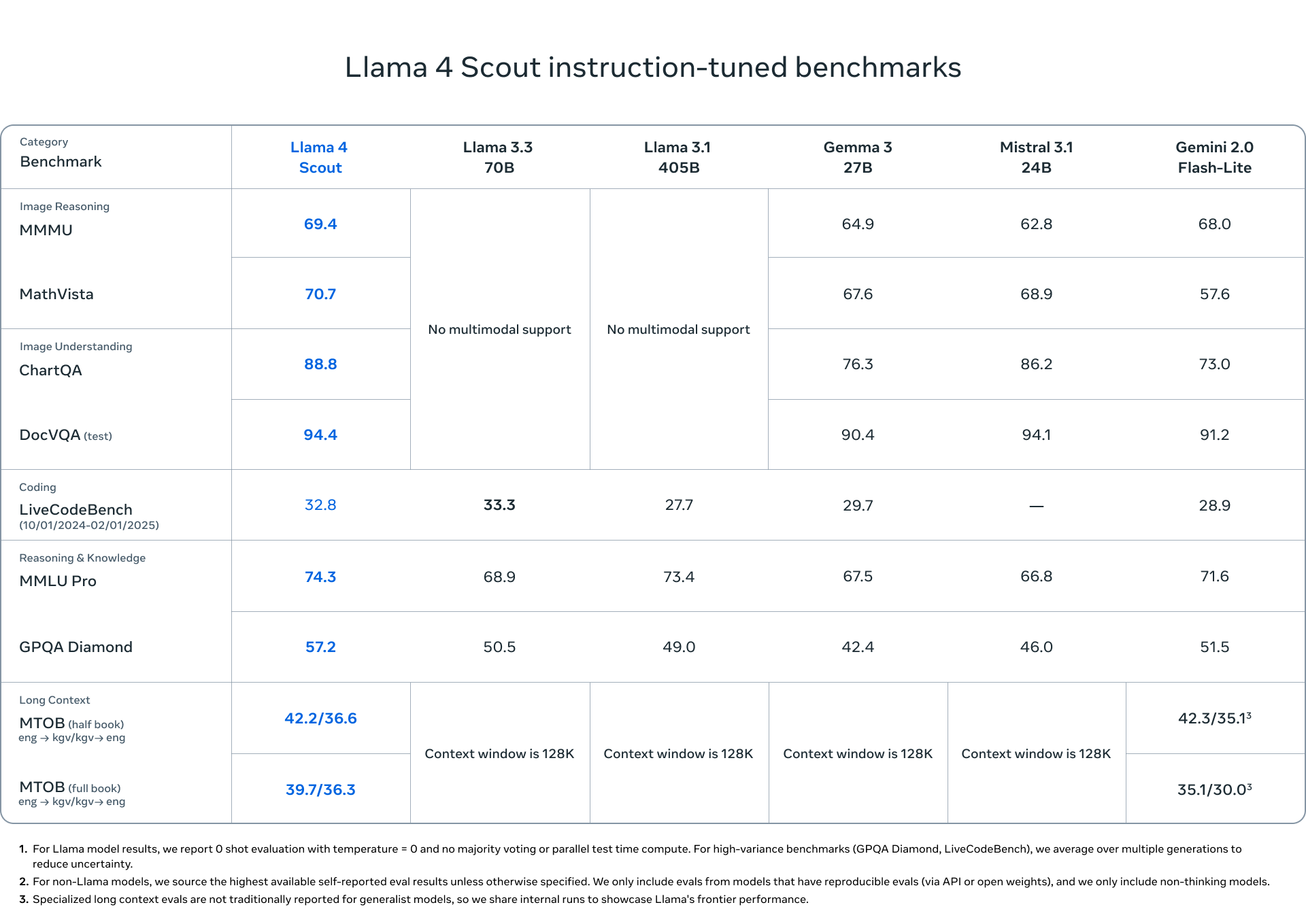
Llama 4 Scout, with 17 billion active parameters (but 109 billion total parameters across 16 experts), fits on a single H100 GPU when quantized to Int4. It boasts an industry-leading 10 million token context window - far exceeding previous limits - and reportedly outperforms comparable models like Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 across standard benchmarks.
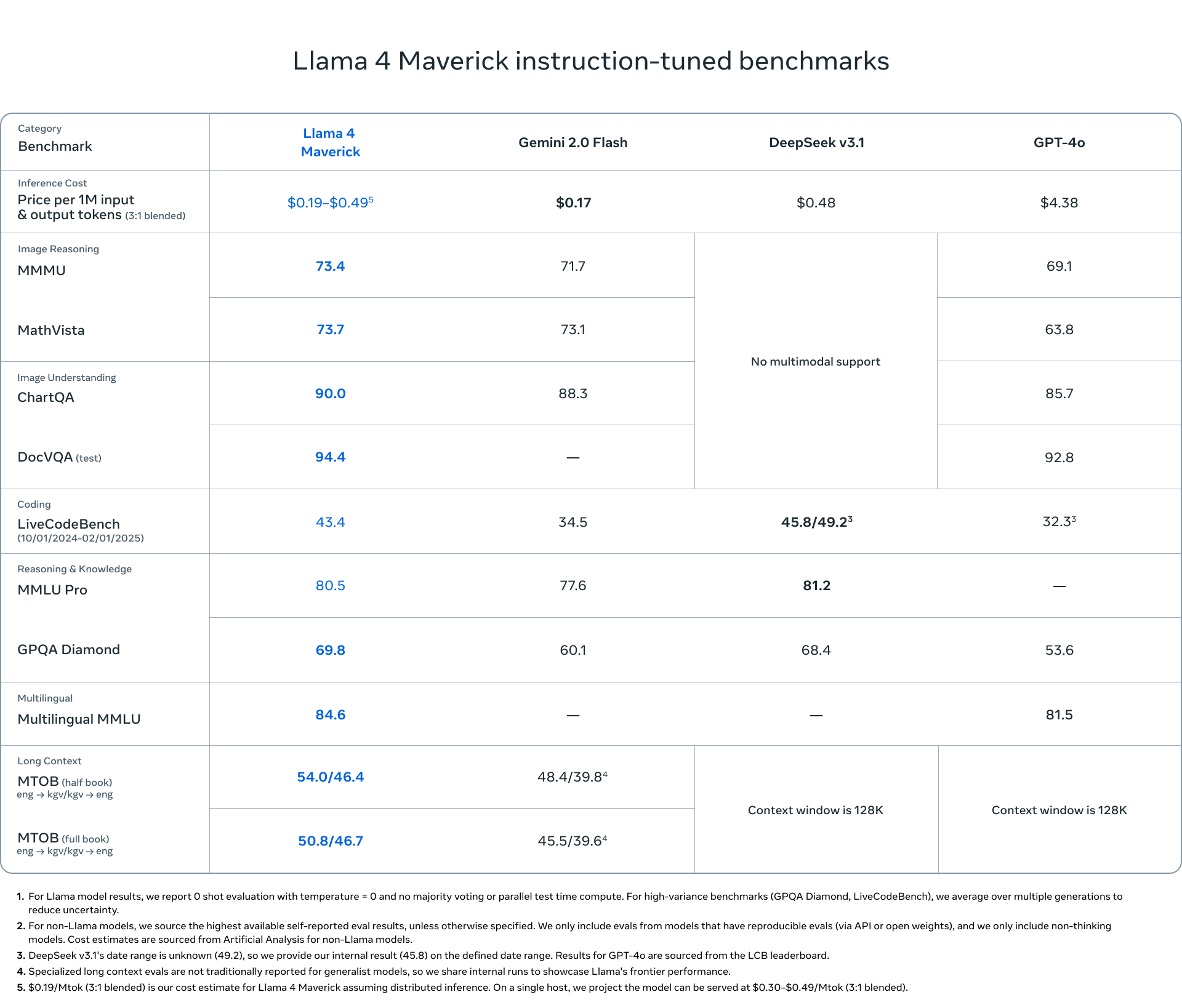
Meanwhile, Llama 4 Maverick steps things up considerably with the same 17 billion active parameters but spread across 128 experts for a total of 400 billion parameters. Meta claims this model beats OpenAI's GPT-4o and Google's Gemini 2.0 Flash on numerous benchmarks while achieving comparable results to DeepSeek v3 on reasoning and coding tasks despite having less than half the active parameters.
Both models feature native multimodality through "early fusion," meaning text and vision are integrated directly into the model backbone rather than being bolted on afterward. This approach allowed Meta to jointly pre-train the models on massive amounts of unlabeled text, image, and video data - over 30 trillion tokens in total, more than double what Llama 3 used.
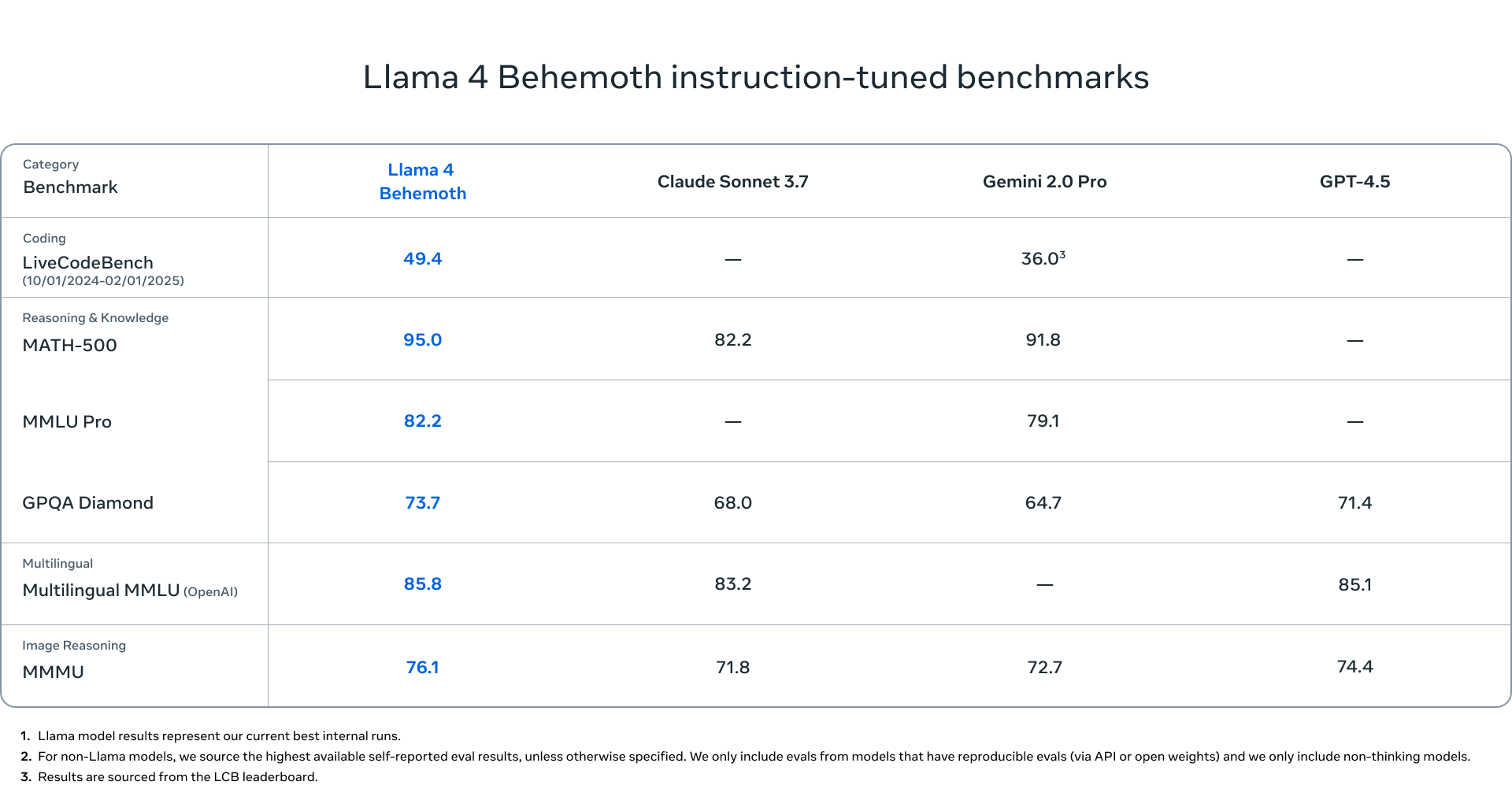
The most intriguing part of Meta's announcement might be what's still coming. Llama 4 Behemoth, which remains in training, comprises 288 billion active parameters across 16 experts for a total approaching two trillion parameters. According to internal benchmarks, this model already outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused tests.
Both Scout and Maverick are available for download today on llama.com and Hugging Face under Meta's Llama 4 Community license, with availability on major cloud platforms to follow soon. Meta is also using these models to power its own Meta AI assistant, available in WhatsApp, Messenger, Instagram Direct, and on the web.
For developers who've been building on Llama models, these advances could substantially improve capabilities while maintaining the accessibility and customizability that made previous versions popular. The 10 million token context window of Scout, in particular, opens possibilities for applications working with extensive documents, codebases, or multi-document analysis.
The release continues to set up an interesting contrast in AI development approaches. While companies like OpenAI and Anthropic have largely maintained closed models accessible primarily through APIs, Meta continues pushing the open-source frontier forward. The question now is whether Meta's approach can continue scaling to match or exceed the capabilities of the most advanced closed models.
With LlamaCon coming up on April 29, Meta is clearly positioning these releases as just the beginning of a new era for its AI strategy. For developers and businesses considering which AI foundation to build upon, the Llama 4 family offers a compelling mix of power, efficiency, and accessibility that deserves serious consideration.