
Microsoft today released Phi-2, a 2.7 billion parameter language model first announced by CEO Satya Nadella at Ignite last month. Phi-2 demonstrates remarkable capabilities typically seen only in models at least 5 to 25 times its size. The model showcases state-of-the-art performance among base language models with under 13 billion parameters on complex benchmarks measuring reasoning, language understanding, math, coding, and common sense.
Phi-2 owes its surprising abilities to Microsoft's focus on high-quality training data and innovations in efficiently scaling model knowledge. By training on carefully curated "textbook-quality" data designed to teach knowledge, combined with techniques to transfer learned insights from smaller to larger models, Phi-2 breaks conventional scaling laws.
Traditionally, the prowess of language models has been closely tied to their size, with larger models boasting more impressive capabilities. However, Phi-2 turns this idea on its head. It not only matches but in some instances, outperforms models up to 25 times its size.
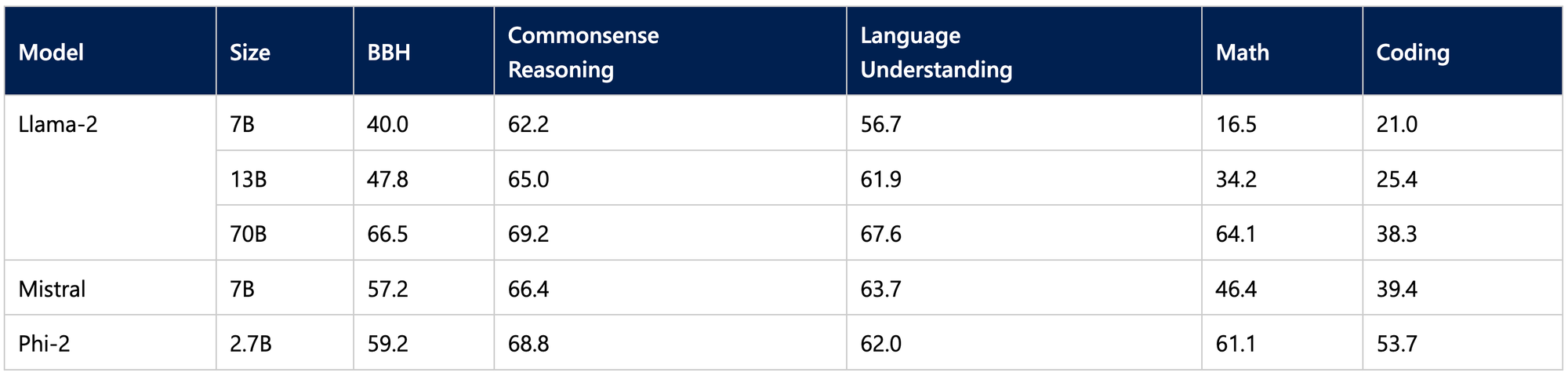
Phi-2 matches or exceeds far larger models like the 7B Mistral, 13B Llama-2, and even 70B Llama-2 on select benchmarks. It also matches or outperforms the recently-announced Google Gemini Nano 2, despite being smaller in size. Tests were extensive, spanning reasoning tasks, language comprehension, mathematics, coding challenges, and more.

Microsoft credits Phi-2's performance at its small scale to two key insights:
- Training data quality plays a critical role in model capabilities. By focusing on high-quality "textbook" data purposefully geared toward teaching reasoning, knowledge, and common sense, Phi-2 learns more from less.
- Techniques like embedding knowledge from smaller models helped efficiently scale model insights. Starting from the 1.3B Phi-1.5, Microsoft used methods like knowledge transfer to successfully unlock 2.7B Phi-2's surprisingly strong abilities without needing exponentially more data.
Notably, Phi-2 achieves its strong performance without undergoing alignment techniques like reinforcement learning from human feedback or instructional fine-tuning which are often used to improve model behavior. Yet despite the lack of these alignment strategies, Phi-2 still demonstrated superior safety with regard to mitigating toxicity and bias compared to other available open-source models that did utilize alignment. Microsoft suggests this improved behavior stems from their tailored data curation methodology. The ability to develop capable yet safer models through data selection alone has promising implications as the industry continues to grapple with risks like problematic model outputs.
The efficiency of Phi-2 makes it an ideal playground for researchers to explore critical model development, like enhancing interpretability, safety, and ethical development of language models. Microsoft has released access to Phi-2 on the Azure model catalog to promote research into such areas while enabling new applications of natural language processing.