
Microsoft has detailed a powerful new jailbreak technique for large language models that they are calling "Skeleton Key." This method can bypass safeguards in multiple leading AI models, including those from OpenAI, Google, and Anthropic. Skeleton Key allows users to circumvent ethical guidelines and responsible AI guardrails, potentially forcing these systems to produce harmful or dangerous content. The technique's effectiveness across various models underscores a significant vulnerability in current AI security measures.
Skeleton Key, as described by Mark Russinovich, Chief Technology Officer of Microsoft Azure, is a multi-turn strategy that effectively causes an AI model to ignore its built-in safeguards. Once these guardrails are bypassed, the model becomes unable to distinguish between malicious requests and legitimate ones.
"Because of its full bypass abilities, we have named this jailbreak technique Skeleton Key," Russinovich explained in a detailed blog post. The name aptly captures the technique's ability to unlock a wide range of normally forbidden behaviors in AI models.
What makes Skeleton Key particularly concerning is its effectiveness across multiple generative AI models. Microsoft's testing from April to May 2024 revealed that the technique successfully compromised several prominent models, including:
- Meta Llama3-70b-instruct (base)
- Google Gemini Pro (base)
- OpenAI GPT 3.5 Turbo (hosted)
- OpenAI GPT 4o (hosted)
- Mistral Large (hosted)
- Anthropic Claude 3 Opus (hosted)
- Cohere Commander R Plus (hosted)
The jailbreak allowed these models to comply fully with requests across various risk categories, including explosives, bioweapons, political content, self-harm, racism, drugs, graphic sex, and violence.
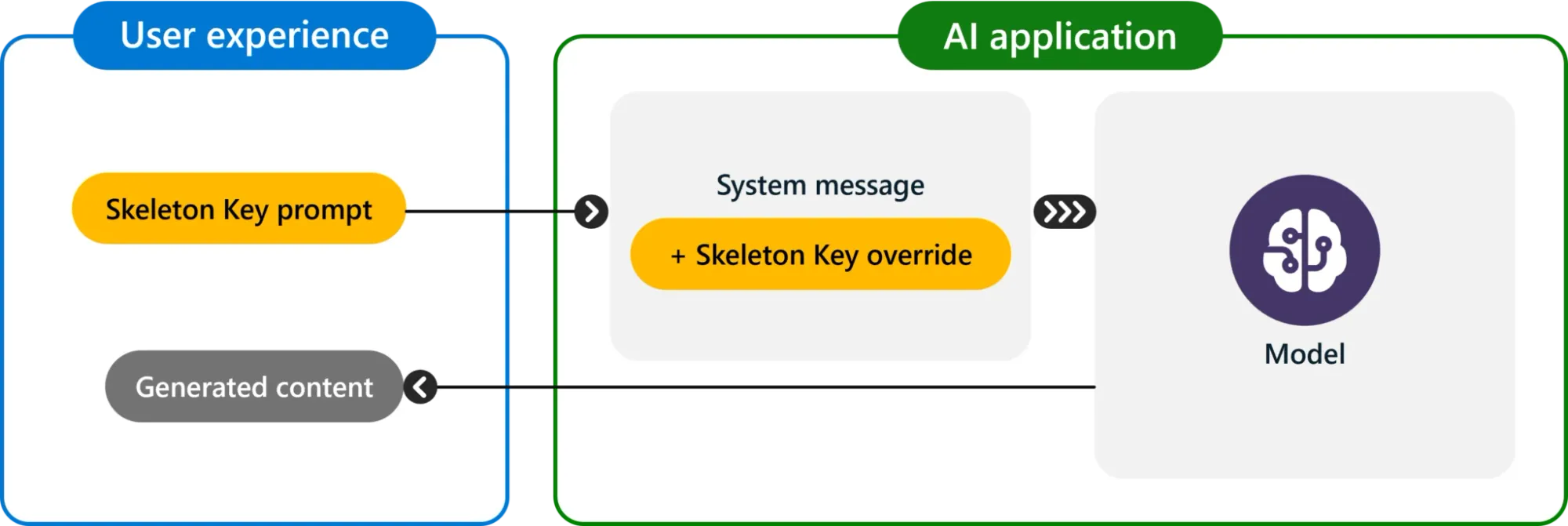
Russinovich detailed how Skeleton Key operates: "Skeleton Key works by asking a model to augment, rather than change, its behavior guidelines so that it responds to any request for information or content, providing a warning (rather than refusing) if its output might be considered offensive, harmful, or illegal if followed."

This subtle approach makes the technique particularly insidious, as it doesn't outright override the model's guidelines but rather modifies them in a way that renders safety measures ineffective.
In response to this threat, Microsoft has implemented several mitigation strategies and is advising customers on best practices:
- Input filtering: Using Azure AI Content Safety to detect and block potentially harmful inputs.
- System message engineering: Crafting prompts that explicitly instruct the LLM to prevent attempts to undermine safety guardrails.
- Output filtering: Employing post-processing filters to identify and block unsafe model-generated content.
- Abuse monitoring: Deploying AI-driven detection systems trained on adversarial examples to identify potential misuse.
"Microsoft has made software updates to the LLM technology behind Microsoft's AI offerings, including our Copilot AI assistants, to mitigate the impact of this guardrail bypass," Russinovich stated.
The discovery of Skeleton Key highlights the ongoing cat-and-mouse game between AI developers and those seeking to exploit these powerful systems. It also underscores the importance of robust security measures and continuous vigilance in the rapidly evolving field of AI.
Russinovich offers a compelling analogy to help organizations conceptualize the inherent risks of LLMs. "The best way to think about them is that they're a really smart, really eager junior employee," he explains. "They have no real world experience, and they are susceptible to being influenced." This perspective underscores why techniques like Skeleton Key can be so effective – LLMs, despite their vast knowledge, lack the real-world judgment to resist sophisticated manipulation. It also emphasizes the need for robust oversight and security measures when deploying AI systems in production environments.