
Microsoft researchers have achieved a new state-of-the-art performance on a key AI benchmark by developing an advanced prompting technique to better steer OpenAI's powerful GPT-4 language model.
The researchers focused on the well-established MMLU benchmark, which tests AI systems across 57 diverse areas of knowledge from math to medicine. By modifying an approach called Medprompt, originally designed for medical questions, the team attained the highest MMLU score ever recorded - 90.10%.
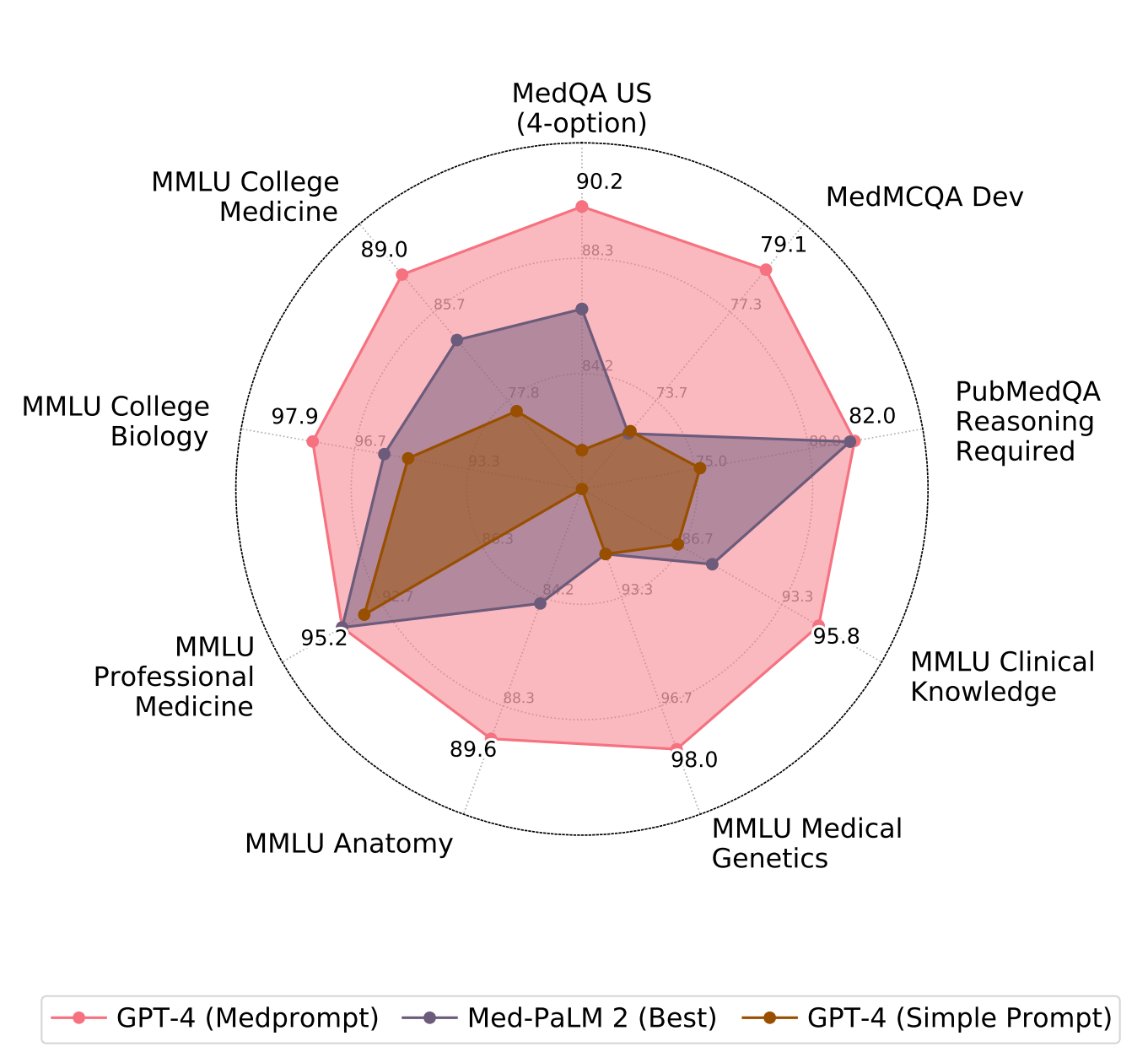
Medprompt combines three distinct prompting strategies:
- Dynamic few-shot selection
- Self-generated chain of thought
- Choice-shuffle ensembling
Firstly, the dynamic few-shot selection leverages the power of few-shot learning to adapt quickly to specific domains. This method innovatively selects different few-shot examples for varied task inputs, enhancing relevance and representation.
The second strategy involves self-generated Chain of Thought (CoT). This approach prompts the model to generate intermediate reasoning steps, improving its ability to tackle complex reasoning tasks. Unlike traditional methods relying on human-crafted examples, Medprompt automates this process, reducing the risk of erroneous reasoning paths.
Finally, the Majority Vote Ensembling strategy amplifies the predictive performance by combining outputs from various algorithms. This includes a unique trick called choice-shuffling for multiple-choice questions, enhancing the robustness of the model's responses.
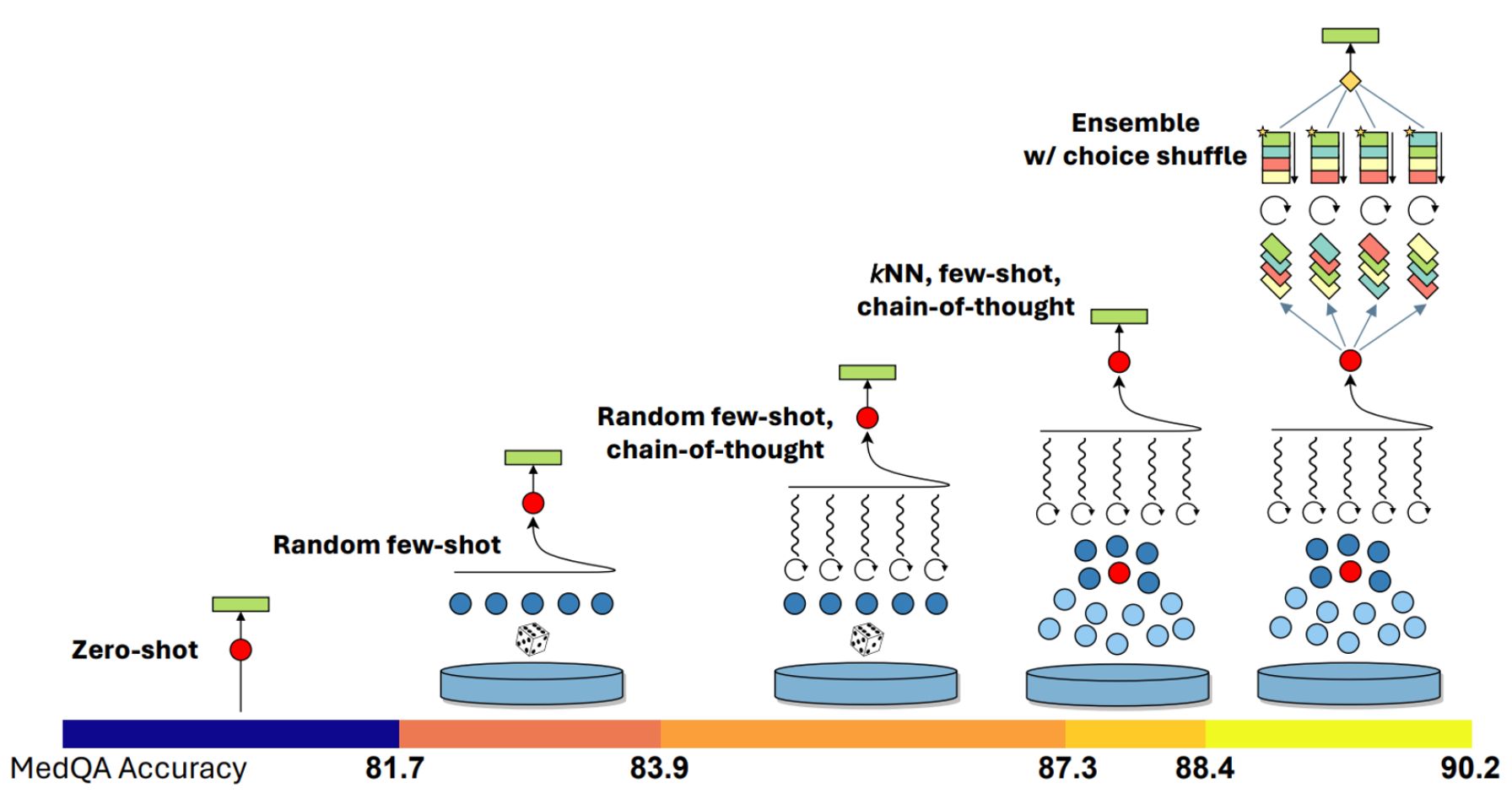
While initially specialized for the medical domain, Microsoft found Medprompt’s careful prompting methodology transferred well to the wide range of disciplines. This can be seen when it is applied to the comprehensive MMLU (Measuring Massive Multitask Language Understanding) benchmark. The original application of Medprompt on GPT-4 achieved an impressive 89.1% score on MMLU. However, refining the method by increasing the number of ensembled calls and integrating a simpler prompting method alongside the original strategy led to the development of Medprompt+.
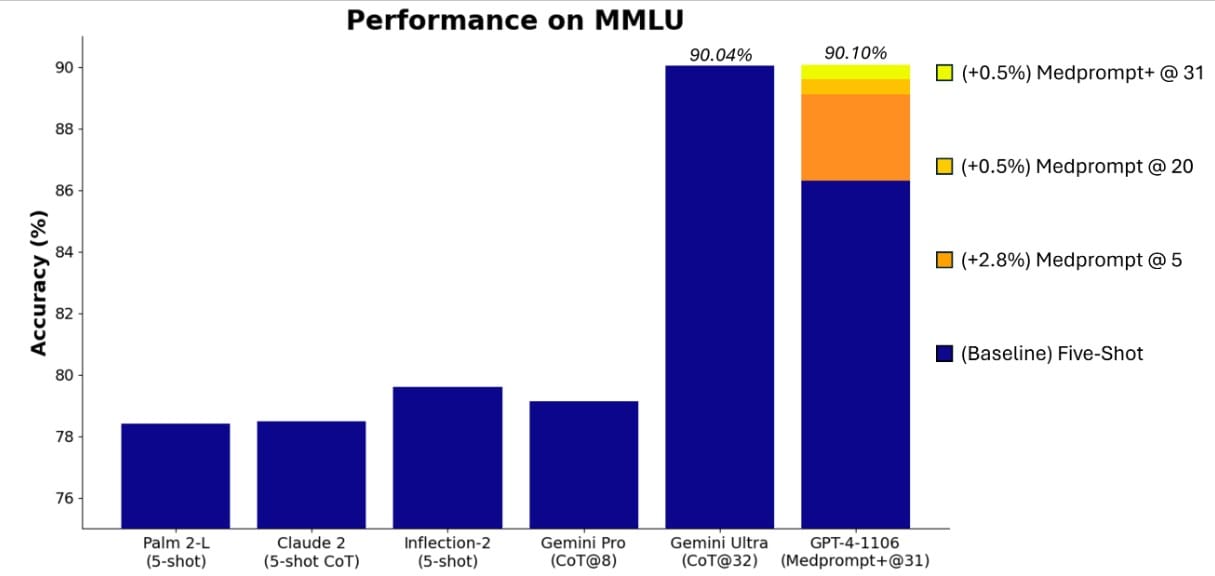
Medprompt+ achieved a landmark performance, scoring a record 90.10% on MMLU. This was made possible by integrating outputs from both the base Medprompt strategy and simpler prompts, guided by a control strategy that utilizes inferred confidences of candidate answers. Notably, this approach leverages GPT-4's ability to access confidence scores (logprobs), a feature soon to be publicly available.
Microsoft also open-sourced promptbase, an evolving collection of resources, best practices, and example scripts for eliciting the best performance from foundation models like GPT-4. The goal is to lower barriers for researchers and developers aiming to tap into models’ potential through optimized prompting.
Microsoft's success with GPT-4 and Medprompt gains additional significance, particularly when juxtaposed against Google's latest AI system, Gemini Ultra. Google's announcement of Gemini Ultra (which won't actually be available until some time next year) was accompanied by a highly publicized but misleading demo video that has become a point of contention in the AI community. The video, initially acclaimed for its portrayal of real-time AI interactions, was later admitted by Google to be a compilation of staged responses using still images and text prompts, rather than the dynamic, live interaction it depicted.
Now, Microsoft's prompting innovations have expanded GPT-4’s competencies beyond what Gemini Ultra is expected to achieve when launched next year. On all the popular benchmarks, prompted GPT-4 now outscores the results anticipated from Gemini Ultra.
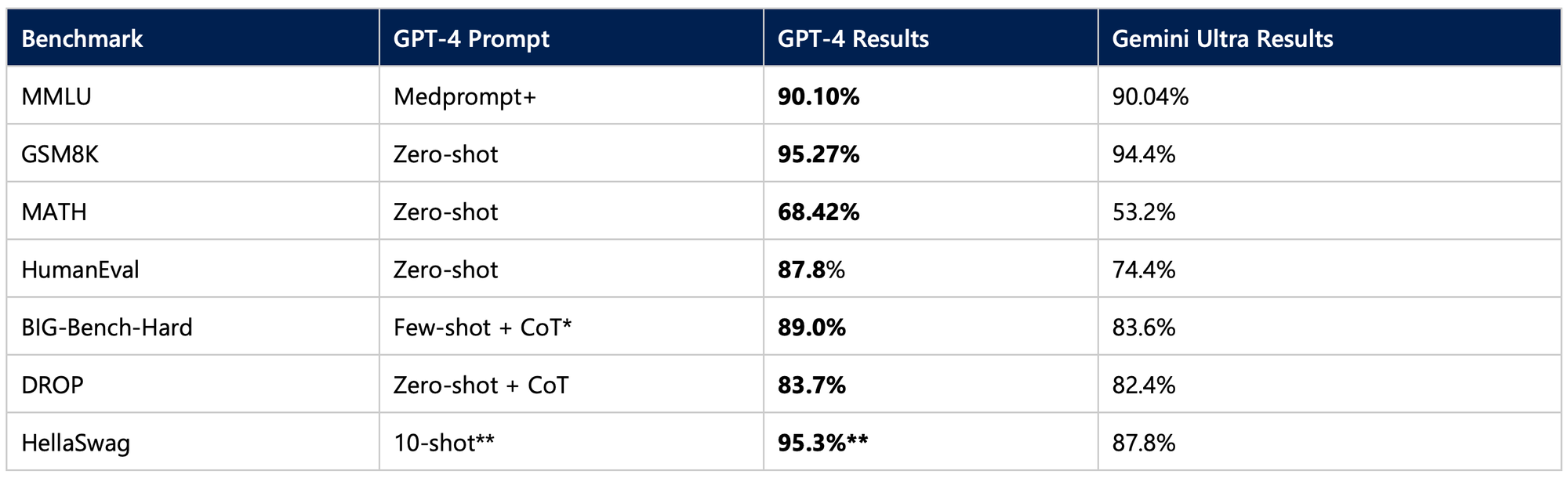
With GPT-4 already displaying intelligence akin to subject matter experts when sufficiently guided, this milestone demonstrates both the models’s extraordinary natural language capabilities as well as the promising opportunity to extend its abilities further through more sophisticated prompting. Microsoft’s latest advances highlight that as AI models progress, better prompting strategies will likely be key to steering these powerful tools toward reliable, ethical and beneficial outcomes.