
In what can truly be described as a significant advancement for the AI ecosystem, MiniMax Research has introduced MiniMax-01, a new series of open-source models which include MiniMax-Text-01, a language model, and MiniMax-VL-01, a visual multimodal model. These models not only rival top-tier AI systems in performance but also introduce a novel architecture capable of processing contexts up to 4 million tokens, setting a new benchmark for language and vision-language models.
Key Points:
- MiniMax-01 offers an unprecedented 4-million-token context window, 32x larger than competitors like GPT-4o.
- It is 10x cheaper than GPT-4o, with API costs at $0.20/M input tokens and $1.10/M output tokens.
- Lightning Attention enables near-linear computational complexity, a first in commercial-grade models.
To put things in perspective, the context window of MiniMax-01 is 32 times larger than that of frontier models like GPT-4o. A context window of this size allows the model to handle the equivalent of a small library’s worth of information in one input-output exchange.
This breakthrough is enabled by Lightning Attention, an innovative mechanism achieving near-linear computational complexity, marking the first commercial-grade implementation of linear attention. MiniMax-Text-01 integrates this architecture with Softmax Attention and Mixture-of-Experts (MoE), activating 45.9 billion parameters per token to process ultra-long inputs efficiently.
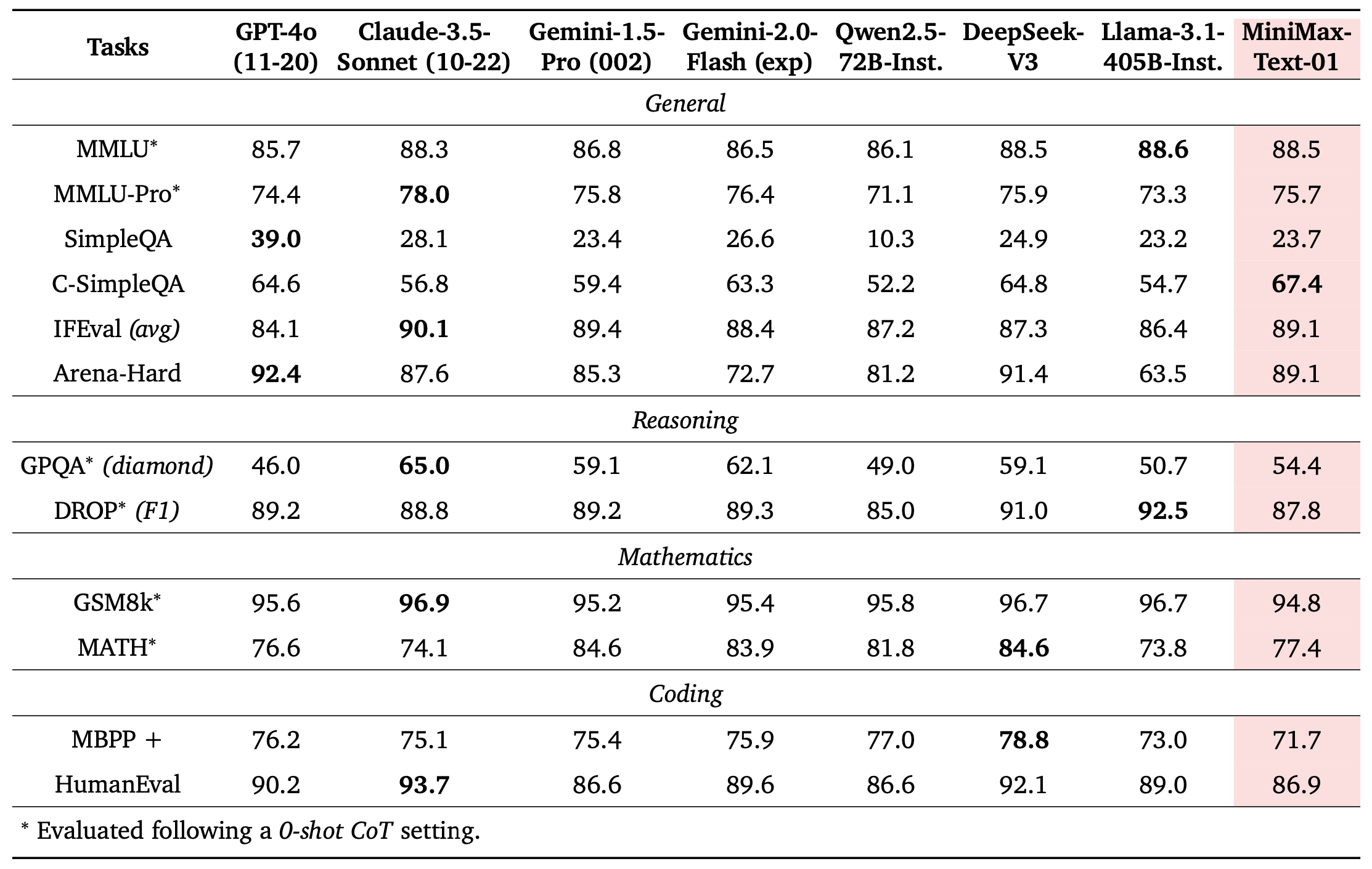
This architecture delivers exceptional performance on tasks requiring long-term memory. Specifically, MiniMax-Text-01 achieved 100% accuracy on the Needle-In-A-Haystack task with a 4-million token context. The company also says that their models demonstrate minimal performance degradation as the input length increases.

Its multimodal counterpart, MiniMax-VL-01, outpaces leading models like Claude 3.5 in vision-language tasks, showcasing robust capabilities for diverse applications such as virtual assistants and AI-driven content creation.
Affordability further distinguishes MiniMax-01. Its API costs just $0.20 per million input tokens and $1.10 per million output tokens, making it ten times cheaper than GPT-4o. These cost savings result from infrastructure optimizations like Varlen Ring Attention, LASP+ (Linear Attention Sequence Parallelism Plus), and Expert Tensor Parallel (ETP), which reduce computational waste and enhance scalability.
In case, you haven't been paying attention, Chinese AI startups have been on a roll lately. Three weeks ago, Hangzhou-based DeepSeek unveiled its third-generation model, trained in just two months with fewer resources than competitors like Llama 3. Yet, DeepSeek V3 matches the performance of leading models like GPT-4o and Claude-3.5-Sonnet. Today's release of MiniMax-01 highlights the resilience of China’s AI industry despite U.S. export controls.
MiniMax-01 models are now available on GitHub and HuggingFace. MiniMax’s APIs and models can also be accessed directly on Hailuo AI and through the company’s API. The company has also published a comprehensive research paper with additional details.