
MLCommons has released its latest MLPerf Inference v4.0 benchmark results, highlighting the rapid advancements in AI hardware and software. The new benchmarks introduce larger generative AI models and highlight the impressive performance gains achieved by leading tech companies.
The Machine Learning Performance (MLPerf) Inference v4.0 benchmark suite, developed by MLCommons, is an industry-standard tool that measures the performance of machine learning (ML) systems in various deployment scenarios. In order to keep up with the ever-changing generative AI landscape, the working group created a new task force to determine which models should be added to the v4.0 version of the benchmark. After careful consideration, two new benchmarks were included in the suite: Llama 2 70B and Stable Diffusion XL.
Llama 2 70B, a model with 70 billion parameters, is an order of magnitude larger than the GPT-J model introduced in MLPerf Inference v3.1. This larger model size requires a different class of hardware, providing an excellent benchmark for higher-end systems. The inclusion of Llama 2 70B in the MLPerf Inference v4.0 release represents a significant increase in model parameters, showcasing the rapid growth of generative AI models.
Stable Diffusion XL, with 2.6 billion parameters, is a popular text-to-image generative AI model used to create compelling images through text-based prompts. By generating a high number of images, the benchmark calculates metrics such as latency and throughput to understand overall performance.
The MLPerf Inference v4.0 results include over 8500 performance results and 900 power results from 23 submitting organizations. Four firms – Dell, Fujitsu, NVIDIA, and Qualcomm Technologies, Inc. – submitted data center-focused power numbers for MLPerf Inference v4.0, demonstrating continued progress in efficient AI acceleration.
NVIDIA's Hopper-based systems running TensorRT-LLM software provided the world's most powerful platform for generative AI. The H200 GPU, featuring 141GB of HBM3e memory and 4.8TB/s bandwidth, achieved a record 31,000 tokens/second on the Llama 2 benchmark, a 45% improvement over the H100 GPU.
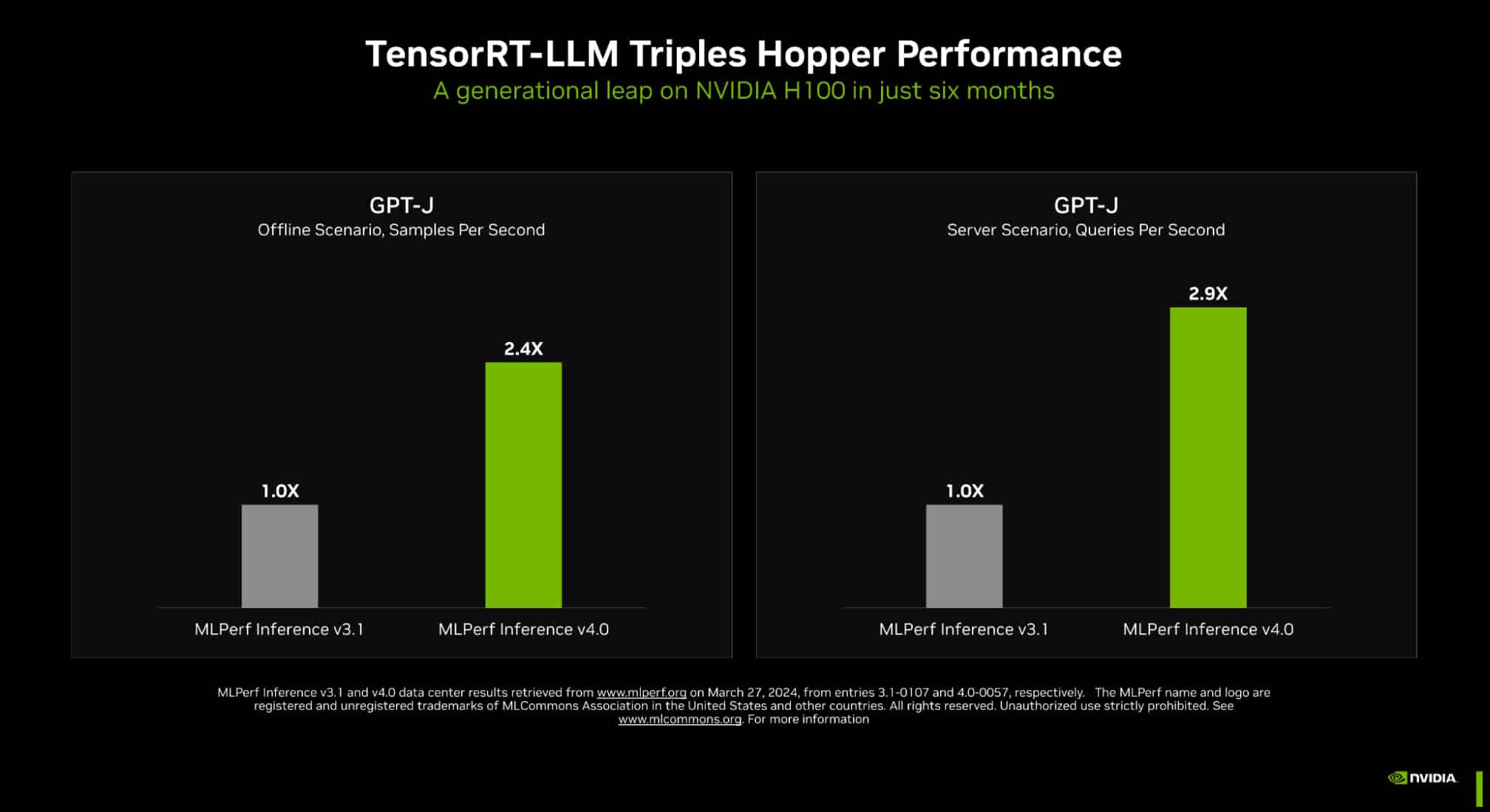
TensorRT-LLM, NVIDIA's software for optimizing inference on large language models, played a crucial role in these performance gains. It boosted the performance of Hopper GPUs on the GPT-J LLM nearly 3x compared to the results from just six months ago in MLPerf Inference v3.1. This shows the power of NVIDIA's full-stack approach, optimizing both hardware and software for generative AI workloads.
NVIDIA also showcased strong performance on the Stable Diffusion XL benchmark, with an 8-GPU NVIDIA HGX H200 system achieving 13.8 queries/second and 13.7 samples/second in server and offline scenarios, respectively. Furthermore, custom thermal designs for the H200 GPU, such as the MGX platform, can boost performance by up to 14% compared to standard air-cooled variants.

Intel's Gaudi 2 accelerator remains the only benchmarked alternative to NVIDIA's H100 GPU for generative AI performance in MLPerf Inference v4.0. While Gaudi 2's performance trails behind NVIDIA's offerings, Intel claims it provides strong performance-per-dollar, an important consideration for total cost of ownership.
Intel's 5th Gen Xeon Scalable processors with Intel Advanced Matrix Extensions (AMX) also demonstrated significant improvements in MLPerf Inference v4.0. The 5th Gen Xeon results showed an average of 1.42x performance gain compared to the previous generation across various MLPerf categories. Notably, for the GPT-J benchmark with software optimizations like continuous batching, the 5th Gen Xeon achieved a 1.8x performance boost over the v3.1 submission.
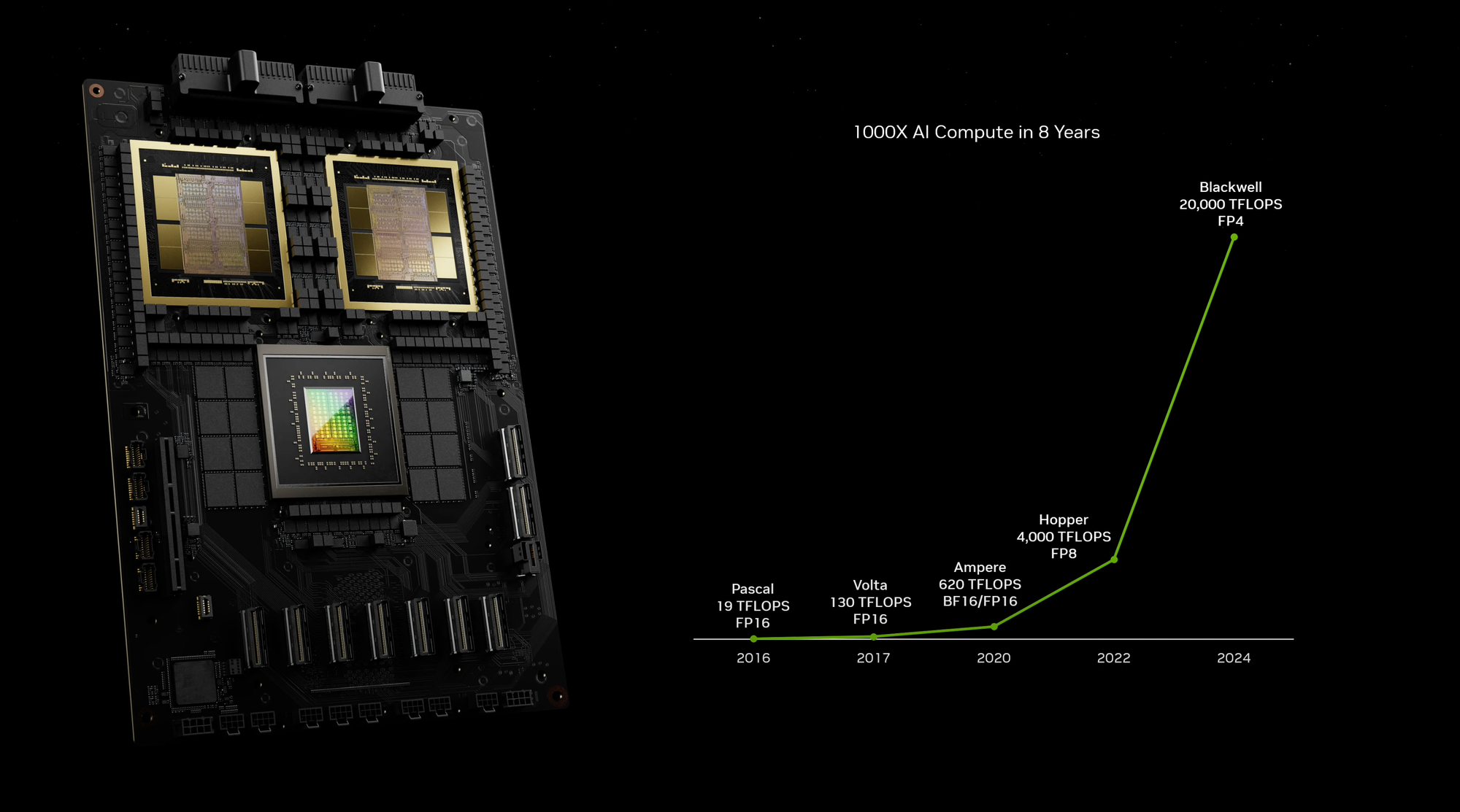
As the demand for generative AI continues to grow, hardware and software vendors are pushing the boundaries of performance. Just last week at GTC, NVIDIA's founder and CEO, Jensen Huang, announced that their upcoming Blackwell GPUs will deliver new levels of performance required for multitrillion-parameter AI models.
Meanwhile, Intel continues to improve its AI offerings across its portfolio, providing customers with a range of solutions for their diverse AI requirements.
The MLPerf Inference benchmarks serve as a valuable tool for customers to evaluate AI performance and make informed decisions when selecting systems for their specific workloads. As the industry-standard benchmark evolves to include more generative AI models and real-world scenarios, it will continue to drive innovation and competition in the AI hardware and software landscape.