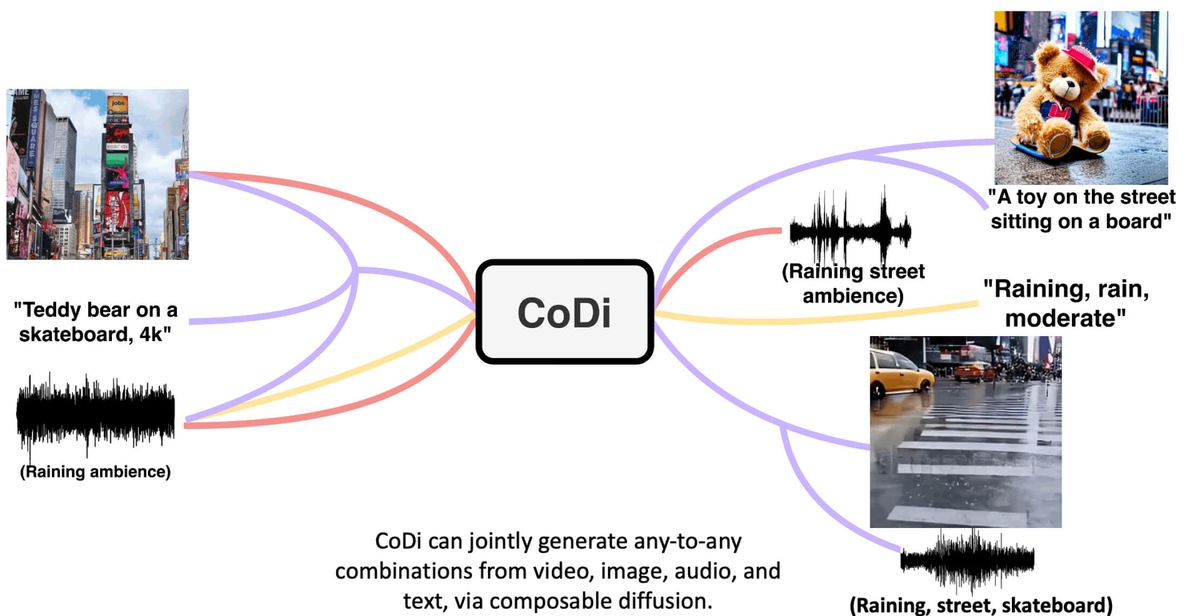
Researchers from Microsoft and University of North Carolina at Chapel Hill recently published a paper introducing Composable Diffusion or CoDi, a groundbreaking model that can process and simultaneously generate combinations of modalities such as language, image, video, and audio from any combination of inputs.
Unlike traditional models, CoDi brings together multiple modalities in parallel, which vastly improves its generation capabilities. This flexibility offers a more complete representation of the multimodal nature of human understanding, opening up possibilities for more immersive human-AI interactions. Checkout the project page for a really impressive demo of its multimodal capabilities.
CoDi employs a composable generation strategy to build a shared multimodal latent space, enabling synchronized generation of interdependent modalities like video and audio. The model architecture consists of individual latent diffusion models for each modality that are first trained separately on modality-specific data. CoDi then aligns these models through a bridging alignment mechanism that projects the latent representations of each modality into a shared space. This allows CoDi to generate any output modalities from any input modalities, even without direct training data for many of these combinations.
CoDi has demonstrated the capability for diverse generation tasks such as single-to-single modality generation, multi-condition generation, and joint generation of multiple modalities. For instance, it can generate synchronized video and audio from a text input prompt, or generate video from an image and audio input. Its performance on eight multimodal datasets showcases exceptional generation quality across various scenarios.
CoDi's development marks a major advancement in the field of multimodal AI. By facilitating the generation of multiple modalities simultaneously, it has the potential to more accurately replicate the multimodal nature of the world and human comprehension. This paves the way for a plethora of applications, from creating more immersive multimedia content to designing more natural and engaging human-AI interfaces. With continued progress, models like CoDi could power virtual environments or digital assistants that generate and synthesize various modalities. Overall, CoDi highlights the potential of composable generative AI systems and marks an important milestone in building artificial general intelligence.