OpenAI has released a suite of new audio models designed to power more natural, responsive voice agents. The ChatGPT maker says this is an important step toward bringing AI out of text-based interactions and into more intuitive spoken conversations.
Key Points
- Two new speech-to-text models outperform legacy systems in accuracy.
- The text-to-speech model now lets developers control tone and delivery.
- Updated Agents SDK enables simple conversion of text agents into voice agents.
The company's bet on voice comes after months of focusing on text-based agent capabilities through releases like Operator and the Agents SDK. But as OpenAI positions it, truly useful AI needs to communicate beyond just text.
"In order for agents to be truly useful, people need to be able to have deeper, more intuitive interactions with agents beyond just text—using natural spoken language to communicate effectively," the company explained during today's announcement.
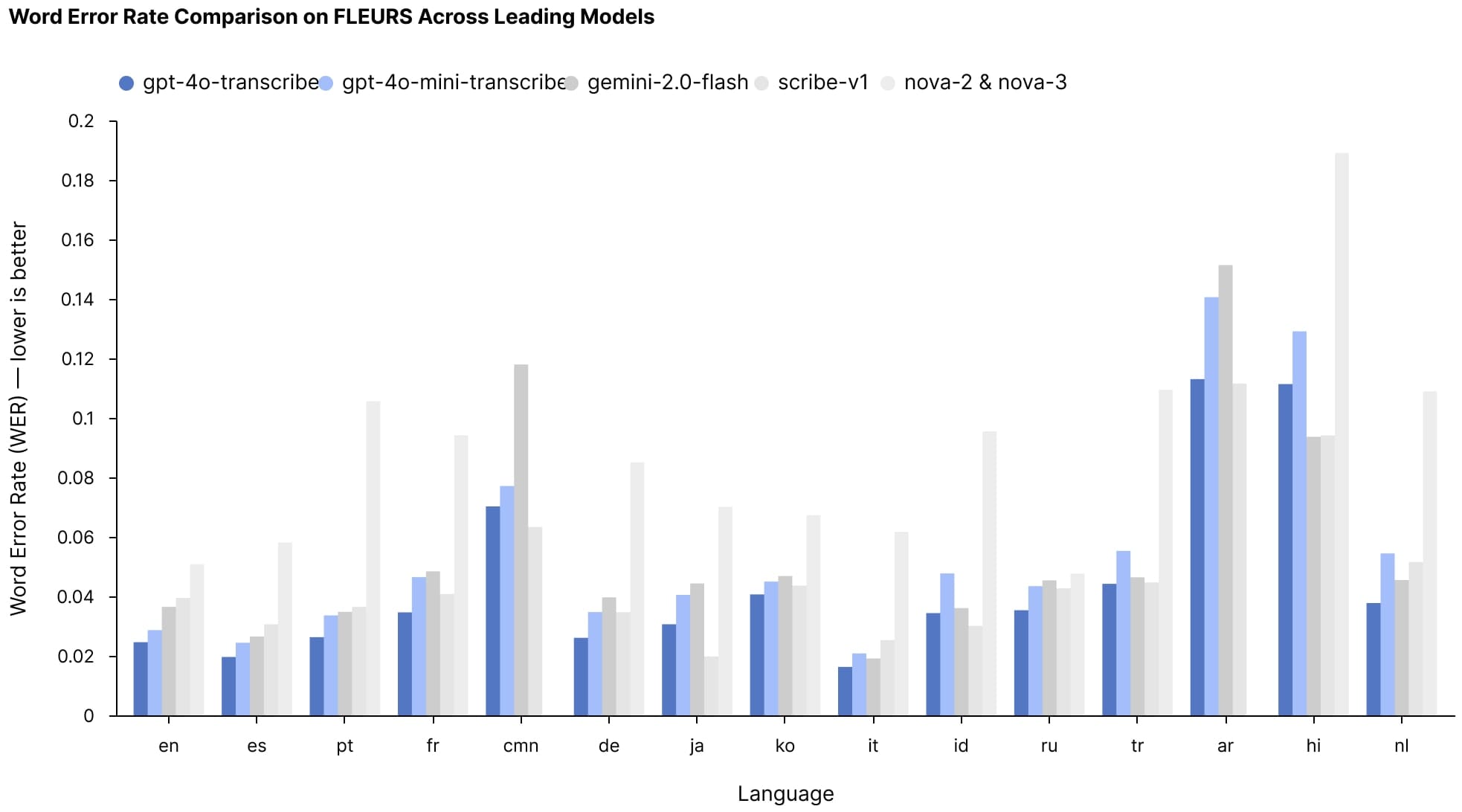
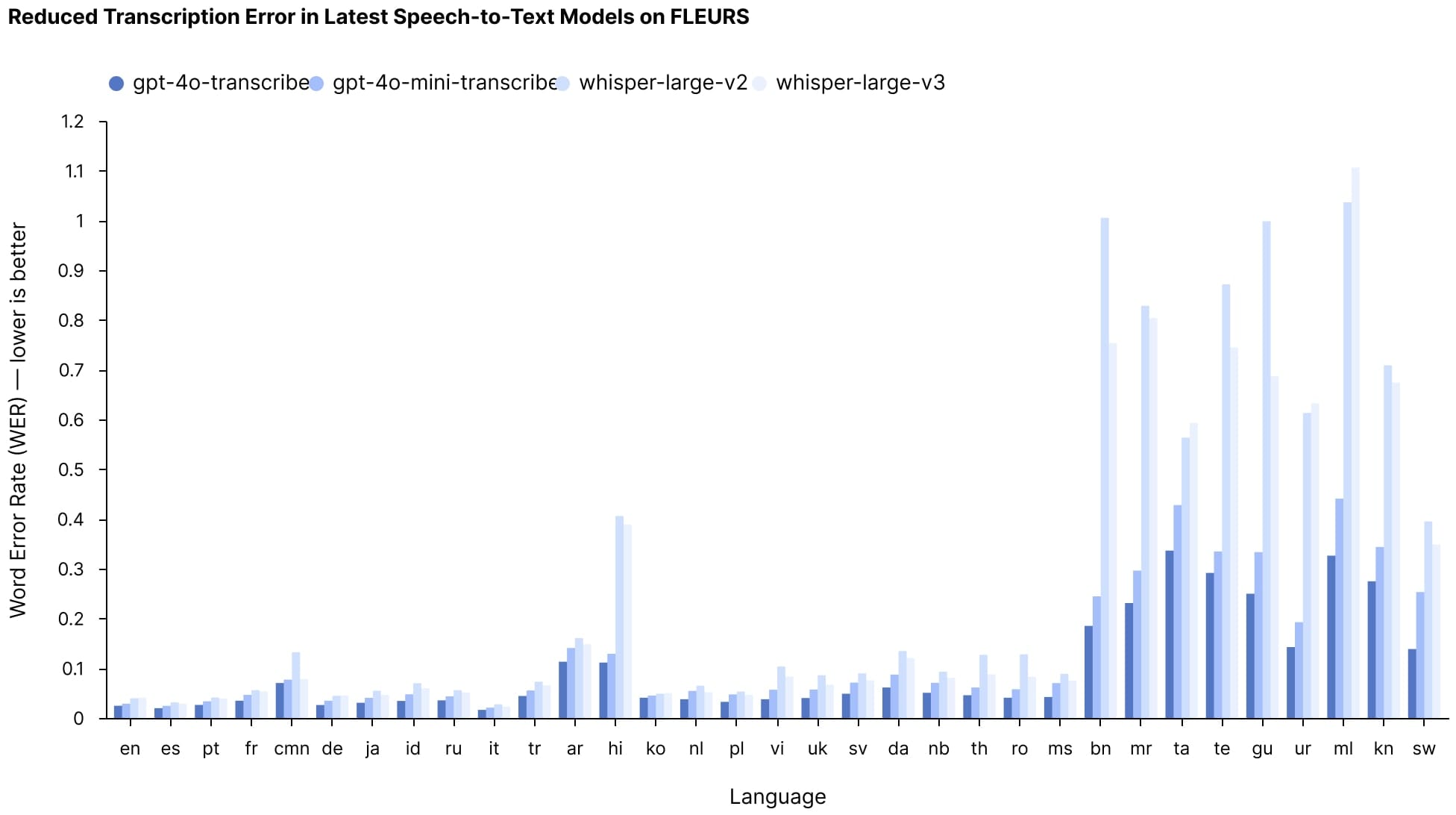
At the core of the release are two new speech-to-text models: GPT-4o-transcribe and GPT-4o-mini-transcribe. Both are designed to convert spoken language into text with significantly higher accuracy than OpenAI's previous Whisper models, achieving lower word error rates (WER) across multiple languages.
The improvements are particularly notable in challenging scenarios like understanding different accents, filtering background noise, and processing varying speech speeds — long-standing pain points in audio transcription technology.
On the FLEURS multilingual speech benchmark, which tests transcription accuracy across more than 100 languages, both new models consistently outperformed not only OpenAI's previous Whisper offerings but also competing solutions from other companies.
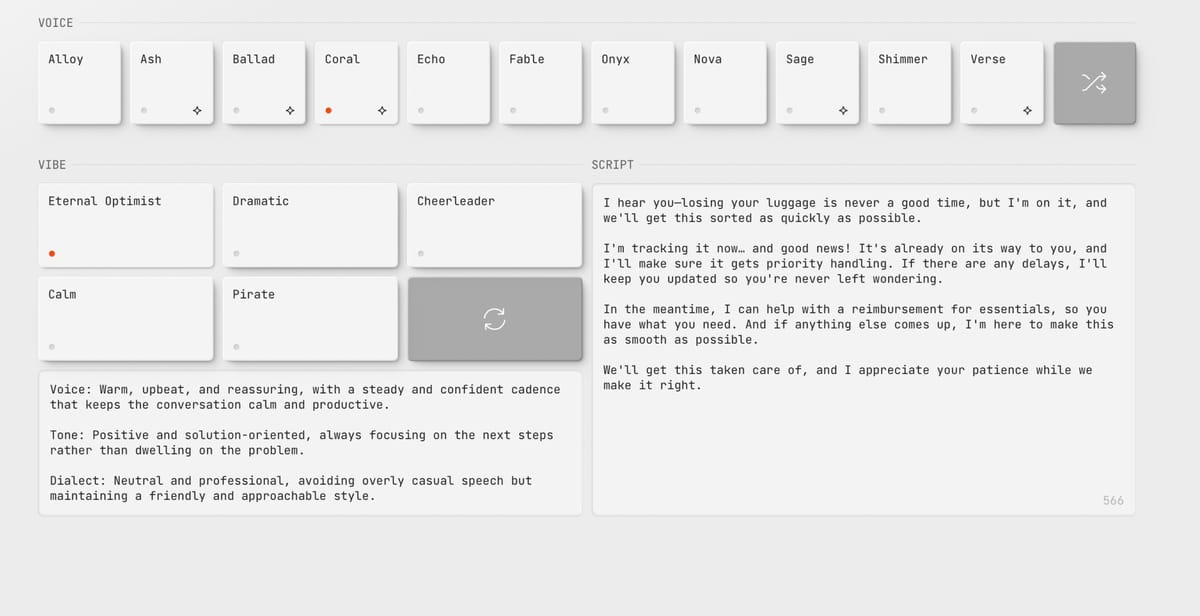
Perhaps more interesting for developers is the new GPT-4o-mini-tts text-to-speech model, which introduces what OpenAI calls "steerability" — the ability to instruct the model not just on what to say, but how to say it.
During a livestream demonstration, OpenAI engineer Iaroslav Tverdoklhib showed how developers can provide instructions like "speak like a mad scientist: high energy, chaotic" to dramatically change the delivery style of the same text. The company has launched openai.fm as an interactive demo site where developers can experiment with these voice variations.
"You can be as specific as you want," Iaroslav explained during the demo. "You can tell it exactly what kind of pacing, what kind of emotion you want to hear."
The pricing structure makes these capabilities relatively accessible, with GPT-4o-transcribe costing approximately $0.6 cents per minute, GPT-4o-mini-transcribe at $0.3 cents per minute, and GPT-4o-mini-tts at 1.5 cents per minute — all cheaper than previous offerings despite the performance improvements.
For developers who've already built text-based AI agents, OpenAI has made the transition to voice surprisingly simple. An update to the week-old Agents SDK allows developers to convert existing text agents into voice agents with minimal code changes.
During the demo, OpenAI showed how just nine lines of additional code could transform a text-based customer support agent into one that processes spoken queries and responds with natural speech. The updated SDK handles the complex pipeline of converting speech to text, processing it through a language model, and converting the response back to speech.
The technical innovations behind these models include pretraining with specialized audio datasets, advanced distillation techniques to transfer knowledge from larger models to smaller ones, and reinforcement learning to improve transcription accuracy.
The company says it plans to continue improving its audio models and exploring ways for developers to bring custom voices to the platform "in ways that align with our safety standards."
Voice technology has long promised to make human-computer interaction more natural, but has often fallen short due to transcription errors and robotic-sounding responses. If OpenAI's new models live up to their benchmarks, they could help close that gap — potentially transforming how we interact with everything from customer service systems to language learning applications.
The new audio models are available to all developers now through OpenAI's API.