
In the big finale for their "12 Days of OpenAI" event, OpenAI previewed their next frontier models, o3 and o3-mini, setting new benchmarks in technical capabilities and safety advancements. The o3 model family represents a significant leap in AI capabilities, excelling particularly in coding, math, and scientific reasoning, while incorporating advanced safety techniques.
Key Points:
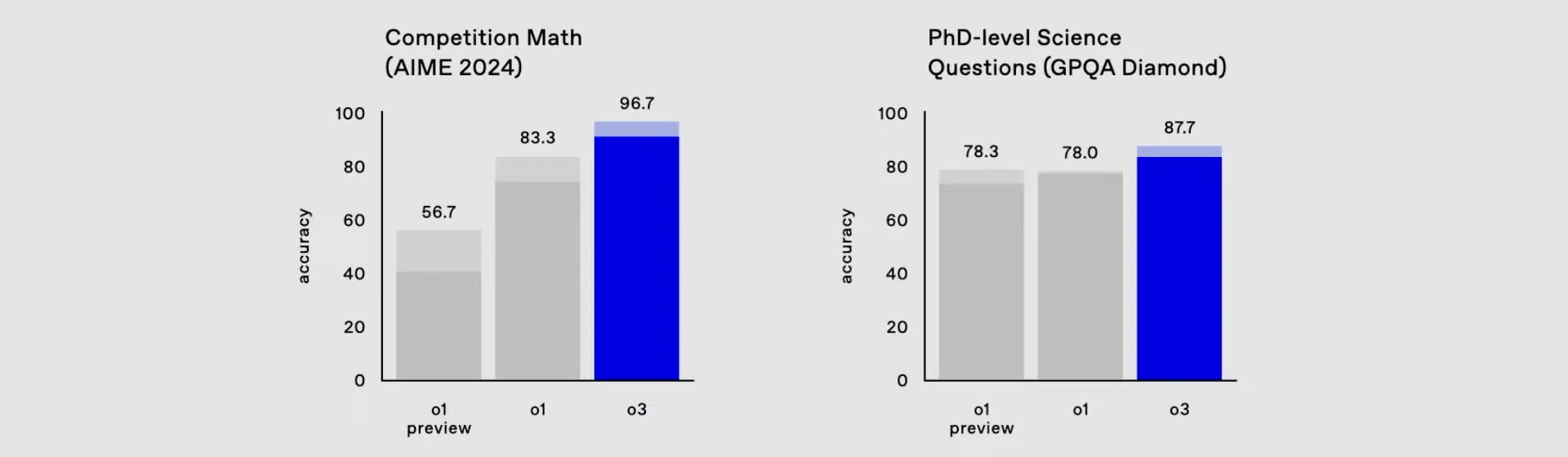
- o3 outperforms previous models in coding (Codeforces rating: 2727), math (96.7% on AIME 2024), and science (87.7% on GPQA Diamond).
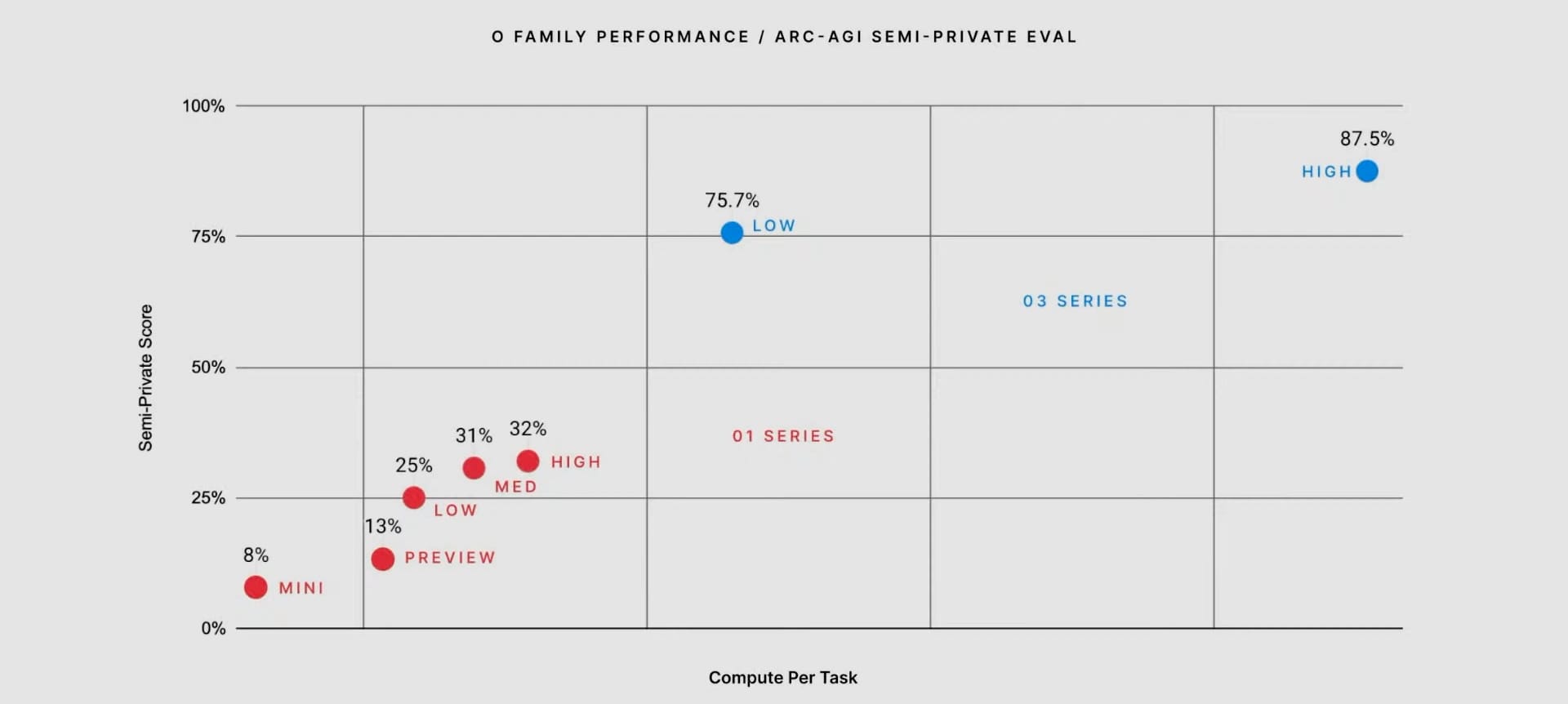
- Achieved 25.2% on EpochAI's Frontier Math (previous best under 2%) and surpassed human-level performance on the ARC-AGI benchmark with a verified score of 87.5%.
- OpenAI introduced deliberative alignment techniques to enhance safety boundaries and address adversarial prompts effectively.
- Applications are open for safety and security researchers to evaluate o3 and o3-mini.
The o3 model sets new records across various technical benchmarks, with particularly impressive results in mathematics and coding. On the AIME 2024 mathematical competition, o3 achieved a remarkable 96.7% accuracy, missing just one question. In scientific reasoning, it scored 87.7% on GPQA Diamond, surpassing typical PhD-level expert performance of 70%.
One of the most remarkable milestones was o3's performance on EpochAI's Frontier Math benchmark, where it solved 25.2% of problems—a dramatic leap from the previous model's 2% accuracy ceiling. On the ARC-AGI benchmark, o3 scored 87.5%, surpassing human performance and marking a milestone in conceptual reasoning.
Accompanying o3 is o3-mini, a distilled version optimized for efficiency in coding tasks. o3-mini maintains impressive performance with lower computational costs and supports adjustable reasoning effort settings—low, medium, and high—enabling flexibility across diverse tasks.
OpenAI says it is taking a measured approach to rolling out o3. The company announced plans to make both models available for public safety testing for the first time, with applications open through January 10th, 2025. The full release is expected around late January for o3-mini, with o3 following shortly after.
The company also unveiled a new safety technique called deliberative alignment, which leverages the models' reasoning capabilities to better identify and handle potentially unsafe prompts. This development represents a significant step forward in AI safety, demonstrating improved performance in both accurately rejecting inappropriate requests and avoiding over-refusal of legitimate ones.