
OpenAI’s latest benchmark, SWE-Lancer, poses a simple but provocative question: can AI models compete with human freelance software engineers? Drawing from over 1,400 real-world Upwork tasks—ranging from $50 bug fixes to $32,000 feature builds—the benchmark attempts to measure AI’s practical coding abilities. The verdict? Despite impressive advances, AI still falls short, earning only a fraction of the available payouts.
Key Points:
- SWE-Lancer evaluates AI models on authentic Upwork tasks, testing full-stack engineering and managerial decision-making.
- The benchmark links AI performance to real-world earnings, offering insights into AI’s economic viability.
- Current frontier models fail most tasks, with the top performer, Claude 3.5 Sonnet, earning just over 40% of the potential $1 million.
- OpenAI has released part of the dataset, SWE-Lancer Diamond, to foster further research on AI’s role in software development.
Software engineering has long been considered one of the more resilient professions in the face of AI disruption. OpenAI’s newly released SWE-Lancer benchmark puts that assumption to the test by evaluating AI models on a dataset of 1,400+ real freelance coding tasks sourced from Upwork, worth a combined $1 million in payouts.
Unlike previous coding benchmarks that focus on isolated programming problems, SWE-Lancer reflects the complexity of real-world software engineering. Tasks span the entire development lifecycle, from UI/UX refinements and bug fixes to designing complex system architectures. The dataset also includes managerial challenges, where AI must assess and select the best implementation proposal—mirroring the decision-making of software leads.
To make the evaluation as realistic as possible, OpenAI graded independent coding tasks using triple-verified end-to-end tests written by professional engineers. Managerial decisions were compared against those made by the original hiring managers.
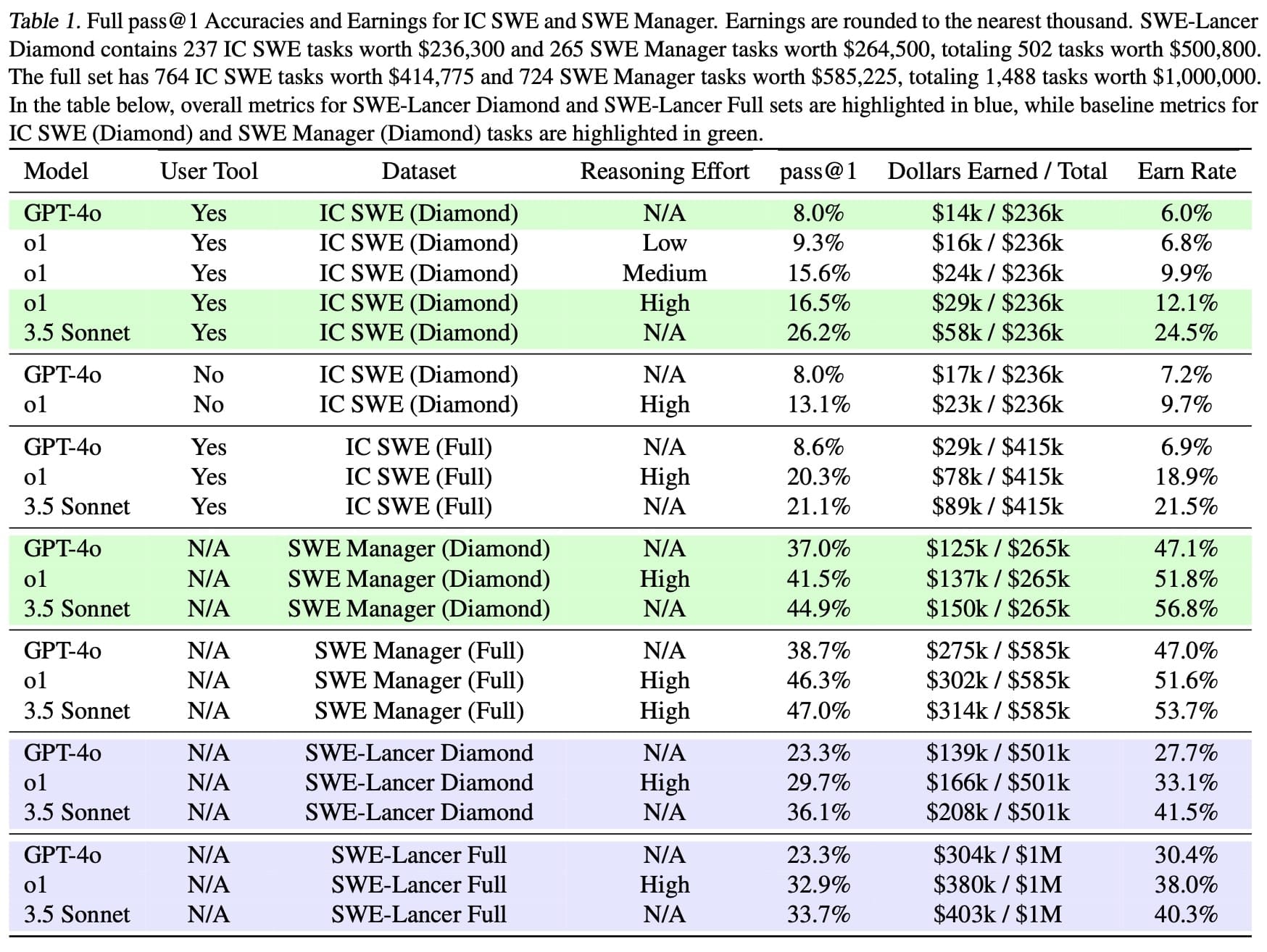
The results, however, indicate that AI still struggles with real-world software development. The best-performing model, Anthropic’s Claude 3.5 Sonnet, earned just over $400,000 out of the possible $1 million across all tasks. OpenAI’s own GPT-4o and other models performed even worse, failing to complete the majority of assignments. On individual contributor (IC) tasks, which required writing and debugging code, models had an even lower success rate—underscoring the limitations of current AI in handling the full scope of software engineering work.
One of SWE-Lancer’s key contributions is its attempt to quantify AI’s software engineering capabilities in financial terms. By linking performance to actual payouts, OpenAI provides a more tangible measure of AI’s value in the coding workforce. This approach could help businesses and policymakers assess AI’s economic impact on the software job market more effectively.
To encourage further research, OpenAI has open-sourced part of the dataset, called SWE-Lancer Diamond, which includes a public evaluation split with $500,800 worth of tasks. Researchers can use this dataset to benchmark new models and explore strategies to improve AI’s ability to tackle complex software engineering problems.
The release of SWE-Lancer highlights both the rapid progress and the remaining challenges of AI in software development. While models have shown remarkable improvements in coding ability—advancing from textbook problems to competitive programming in just a few years—SWE-Lancer suggests that AI is still far from replacing human engineers. The benchmark provides a valuable reality check on AI’s limitations and a roadmap for future advancements in automated software engineering.