

OpenAI’s latest foundation model, o3, has redefined AI’s ability to tackle complex reasoning tasks, achieving unprecedented performance on the ARC-AGI test—a milestone hailed as a leap forward in machine understanding of novel problems.
Key Points
- o3 scored 87.5% on the ARC-AGI benchmark in high-compute mode, far surpassing previous records and tripling its predecessor’s performance.
- The ARC-AGI test is designed to evaluate an AI’s ability to adapt to tasks without relying on pre-trained knowledge.
- EpochAI’s Frontier Math benchmark highlighted o3’s unique reasoning capabilities, solving 25.2% of problems where others remain below 2%.
- Researchers view this as a major milestone but emphasize that AGI remains a distant goal, as many simple ARC-AGI tasks remain unsolved.
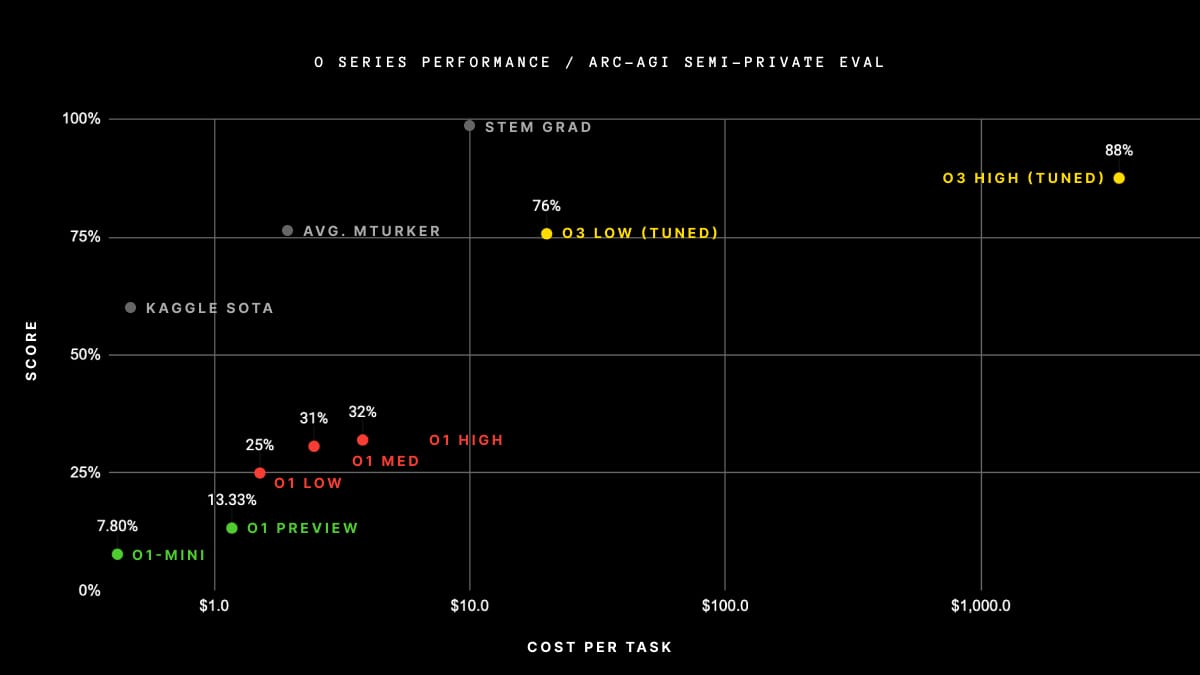
The ARC-AGI test, developed by renowned AI researcher François Chollet, evaluates models on their capacity for “adaptive general intelligence”—solving entirely novel problems without domain-specific training. Unlike benchmarks that test pattern recognition or brute-force computation, ARC-AGI challenges conceptual reasoning, an area traditionally dominated by human intelligence. By crossing the 85% threshold on this test, o3 has demonstrated capabilities that demand a reassessment of AI’s potential and its limitations.
o3’s performance represents a pivotal moment in AI research for several reasons. First, it bridges the gap between task-specific models and those capable of reasoning more flexibly, akin to human cognition.
Second, its success underscores the importance of designing rigorous benchmarks that push AI systems toward genuine understanding rather than rote learning.
Third, it highlights the evolving challenge of accurately measuring intelligence in advanced systems. As models like o3 push boundaries, benchmarks must adapt to remain relevant and rigorous, requiring new methodologies that go beyond brute computational force.
However, this achievement is not without caveats. Chollet, who collaborated with OpenAI on testing o3, points out that ARC-AGI v1 is nearing saturation, with ensemble approaches already scoring above 81%.
Furthermore, early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute (while a smart human would still be able to score over 95% with no training). This demonstrates the continued possibility of creating challenging, unsaturated benchmarks without having to rely on expert domain knowledge. You’ll know AGI is here when the exercise of creating tasks that are easy for regular humans but hard for AI becomes simply impossible.
OpenAI’s success with o3 highlights the role of high-compute, carefully curated datasets, and cutting-edge reasoning techniques in shaping the next generation of AI. It will be interesting to see whether the techniques behind o3 will be reproduced or extended by the open-source community in 2025.
Ultimately, o3’s record-breaking ARC-AGI performance is both a milestone and a challenge, setting a new bar for what AI can achieve while emphasizing how much farther it has to go to reach true general intelligence.