
A team of AI researchers from MIT, Tsinghua University, and Canadian startup MyShell have introduced OpenVoice, an impressive open-source voice cloning tool with unprecedented versatility and nearly instantaneous results.
OpenVoice only requires a short audio sample from a target speaker to accurately replicate their unique vocal tone and characteristics. It can then generate natural-sounding speech mimicking that voice in multiple languages while providing users granular control over parameters like emotion, accent, rhythm, and intonation.
The researchers say the advantages of OpenVoice are three-fold:
1. Accurate Tone Color Cloning. OpenVoice can accurately clone the reference tone color and generate speech in multiple languages and accents.
2. Flexible Voice Style Control. OpenVoice enables granular control over voice styles, such as emotion and accent, as well as other style parameters including rhythm, pauses, and intonation.
3. Zero-shot Cross-lingual Voice Cloning. Neither of the language of the generated speech nor the language of the reference speech needs to be presented in the massive-speaker multi-lingual training dataset.
This level of flexible voice manipulation has not been achieved in other cloning solutions, representing a major leap forward. OpenVoice also accomplishes zero-shot cross-lingual cloning, meaning it can clone voices and generate speech in languages completely absent from its training data.
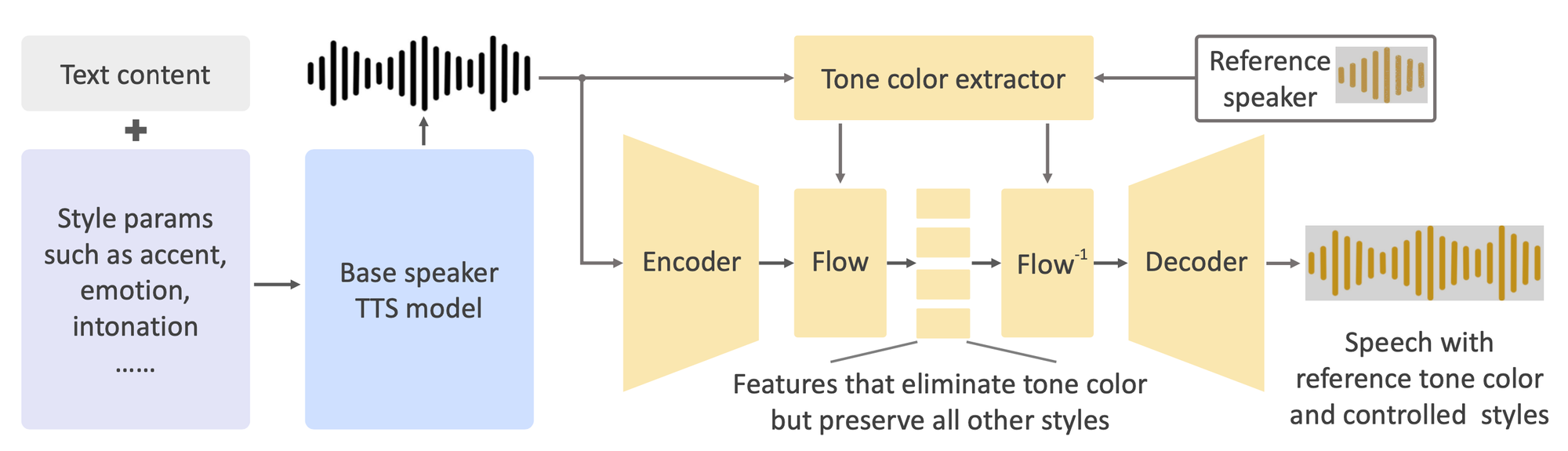
Under the hood, OpenVoice uses a base speaker text-to-speech (TTS) model to define language, style parameters and baseline tone built using 30K recorded voice samples from 20K individuals. A separate tone color converter then shifts that tone to precisely match the reference speaker, while retaining all other defined qualities.
This combination allows for the unique decoupling of voice cloning elements – tone color from voice styles and languages. This structure enables not just the cloning of the voice's tone color but also the flexibility to manipulate various style parameters. This significant advancement overcomes limitations of previous voice cloning methods, which were often constrained by their reliance on massive-speaker multi-lingual datasets and lacked the ability to alter voice styles post-cloning.
Additionally, it uses normalizing flows, an invertible neural network architecture that removes then re-embodies tone data without losing other vocal elements like accent or prosody. The base model can be a single-speaker or multi-speaker TTS system fitted with control interfaces.
OpenVoice can accurately clone the reference tone color and generate speech in multiple languages and accents.
OpenVoice’s zero-shot achievement for new languages works because the model’s training methodology encourages language-agnostic intermediate representations. Using International Phonetic Alphabet phoneme labels likely also boosted its cross-lingual transferability.
The potential applications of OpenVoice are vast and varied, from enhancing media content creation to revolutionizing chatbots and interactive AI interfaces. Its ease of use and computational efficiency make it a viable option for both commercial and research purposes. To encourage further advancements in the field, the researchers have publicly released OpenVoice’s source code and model weights to accelerate advancements in voice cloning.
MyShell says an internal version of OpenVoice has already been used "tens of millions of times" by users in 2023 as it powers the instant voice cloning backend of MyShell.ai.
While showcasing impressive technical capabilities, the release of OpenVoice also sparks urgent ethical and security discussions given the sensitivity of voice identity and authentication.