
Perplexity, an AI startup focused on reinventing search with AI systems, has announced the release of two new large language models designed to provide helpful, factual, and current information. These models pplx-7b-online and pplx-70b-online, represent the first publicly available online LLMs accessible via an API.
Online LLMs differentiate themselves by leveraging live internet data, enabling real-time, accurate responses instead of pre-trained information. For example, offline LLMs like Claude 2 struggle with fresh queries like "What was the Warriors game score last night?" whereas Perplexity's system can tap into the latest sports results.
What sets the pplx online models apart in the AI landscape is their unique offering through an API. While popular LLMs like Google Bard, ChatGPT, and BingChat have made strides in online browsing capabilities, they have not extended this functionality via an API.
The company credits its in-house search infrastructure for powering this capability. Perplexity's index covers a massive trove of high-quality websites, prioritizing authoritative sources and using sophisticated ranking to surface relevant, trustworthy information. These real-time "snippets" get fed into the LLMs to inform up-to-date responses. Both models are built on top of mistral-7b and llama2-70b base models.
Perplexity AI has not only integrated these models with cutting-edge technology but has also fine-tuned them for optimal performance. The meticulous process involves using diverse, high-quality training sets curated by in-house data contractors. This ongoing refinement ensures that the models excel in helpfulness, factuality, and freshness.
To validate the effectiveness of these models, Perplexity AI conducted thorough evaluations. Using a diverse set of prompts, the models were assessed on helpfulness, factuality, and up-to-dateness. The evaluation involved side-by-side comparisons with other leading models, including OpenAI's gpt-3.5 and Meta AI's llama2-70b, with a focus on holistic performance as well as specific criteria.
The results of these evaluations are impressive. Both pplx-7b-online and pplx-70b-online models consistently outperformed their counterparts in terms of freshness, factuality, and overall preference. For instance, in the freshness criterion, pplx-7b and pplx-70b achieved estimated Elo scores of 1100.6 and 1099.6, surpassing gpt-3.5 and llama2-70b.
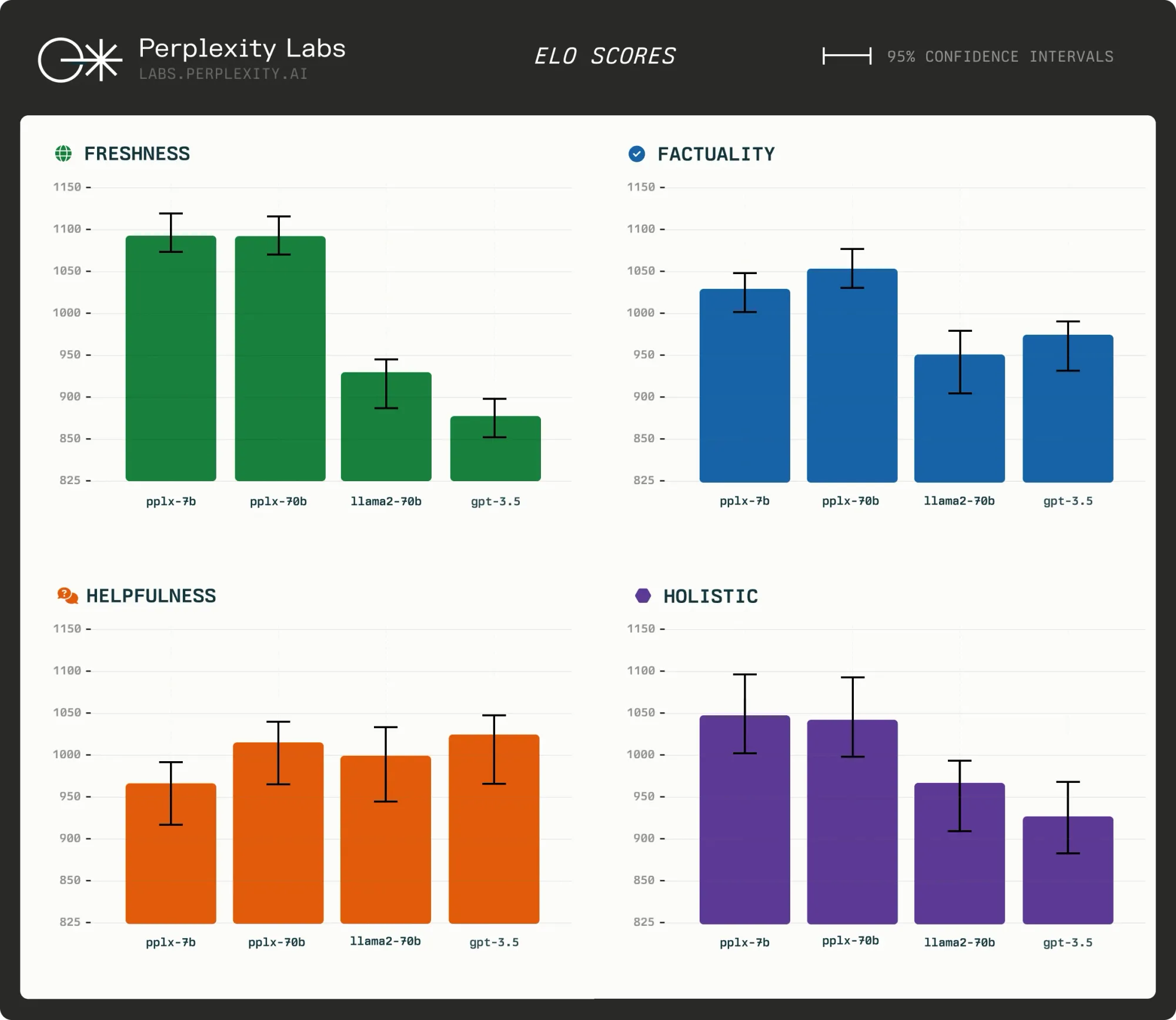
pplx-7b (-online), pplx-70b (-online), llama2-70b, and gpt-3.5 across four different evaluation sets. For example, on the freshness axis, pplx-7b and pplx-70b perform better than gpt-3.5 and llama2-70b, with an estimated Elo score of 1100.6 and 1099.6 vs 879.3 and 920.3, respectively.Starting today, developers can access Perplexity's API to build apps leveraging the unique capabilities of these models. Pricing is usage-based, with special plans available for early testers.