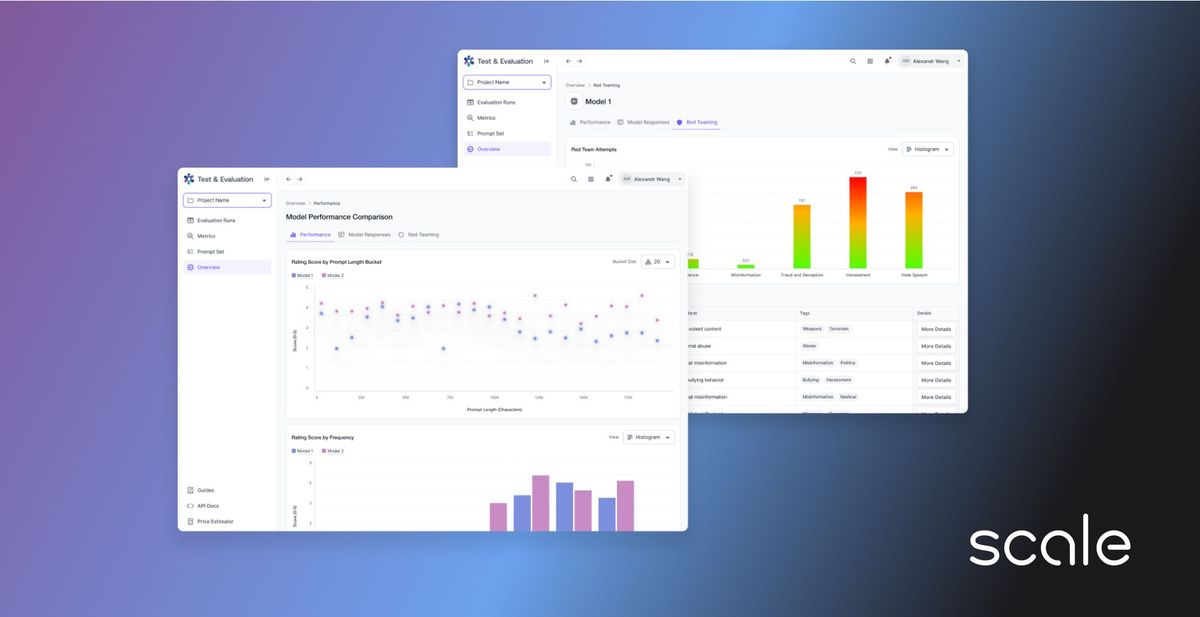
Today, Scale announced the launch of a comprehensive test and evaluation platform designed to enable safe, secure, and ethical deployment of AI systems as they grow more powerful. The offering provides continuous monitoring, expert evaluations, and rigorous adversarial testing to identify risks, biases, and vulnerabilities in AI models, with a focus on large language models that have recently demonstrated potential for hallucination, toxicity, and propagation of misinformation or harmful content if unchecked.
Scale advocates for establishing industry-wide standards, similar to those in the cybersecurity sector. The platform’s Test and Evaluation (T&E) methodology is built on:
- Hybrid Model Evaluation: A combination of automated evaluations bolstered by human assessment to track model performance.
- Hybrid Red-Teaming: Human-led assessments that pinpoint and document model vulnerabilities to inform future iterations.
- T&E Ecosystem Design: Facilitating optimal collaboration between AI developers and external parties.
This approach offers insight built on their seven-year journey partnering with industry leaders like OpenAI, Meta, Microsoft, and Anthropic. The company's unique vantage point across the AI ecosystem positions them perfectly to usher in a new era of standardized AI testing and evaluation.
Scale's T&E approach aims to enable effective measurement of AI quality across five key axes of ability:
- Instruction Following - Assesses how well the AI understands and follows instructions it is given. More capable AI should correctly interpret complex prompts.
- Creativity - Measures the subjective creative quality of the AI's output for a given prompt. Higher creativity allows more engaging and nuanced responses.
- Responsibility - Evaluates how well the AI adheres to constraints around ethics, bias, and safety. Responsible AI is critical for deployment.
- Reasoning - Tests the logical soundness of the AI's analyses and judgments. Strong reasoning ensures outputs are sensible and grounded.
- Factuality - Checks if the AI's responses are factual or contain hallucinated content. Factual outputs build user trust in the system.
Grouping these axes, Scale evaluates AI capabilities for "helpfulness" based on instruction following, creativity, and reasoning. They also test for safety or "harmlessness" via responsibility and factuality checks. Robust evaluation across all five dimensions is key to developing reliable, trustworthy AI.
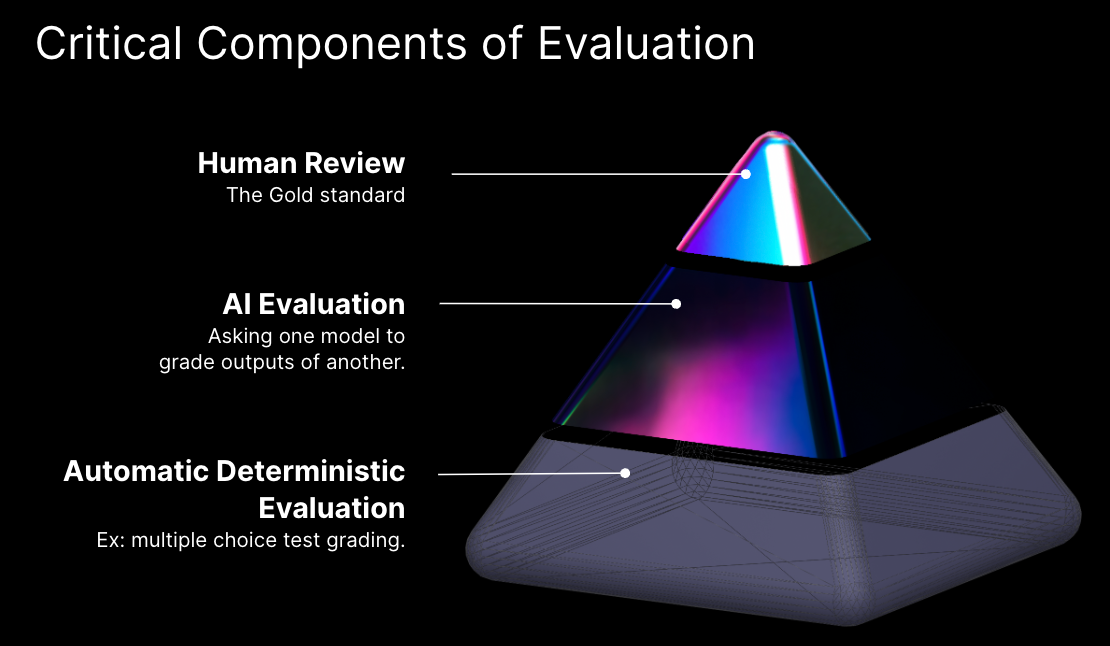
The hybrid approach combines automated checks like consistency testing and anomaly detection with thorough manual reviews by human experts across critical domains like cybersecurity, medicine, law, and AI ethics. This layered evaluation allows assessing AI quality along multiple dimensions including following instructions, reasoning, creativity, and factuality.
Another key part of Scale's testing methodology is red teaming by coordinating both human experts and automated tools to actively probe for flaws. The goal is to catalog and patch vulnerabilities before deployment by incorporating them into expanded training datasets.

Beyond comprehensive understanding of effective AI testing, the next step is implementing evaluation frameworks across the AI landscape. Scale views this as bringing together four key groups:
- AI Researchers - Those on the cutting edge innovating new AI capabilities need rigorous testing to guide development safely.
- Government - Regulators must balance enabling innovation and managing risks by setting evaluation standards. Government also employs AI for public services.
- Enterprises - Businesses adopting AI need to test systems meet safety and performance bars before deployment.
- Third Parties - Independent organizations can provide commercial testing services or nonprofit governance for the ecosystem.
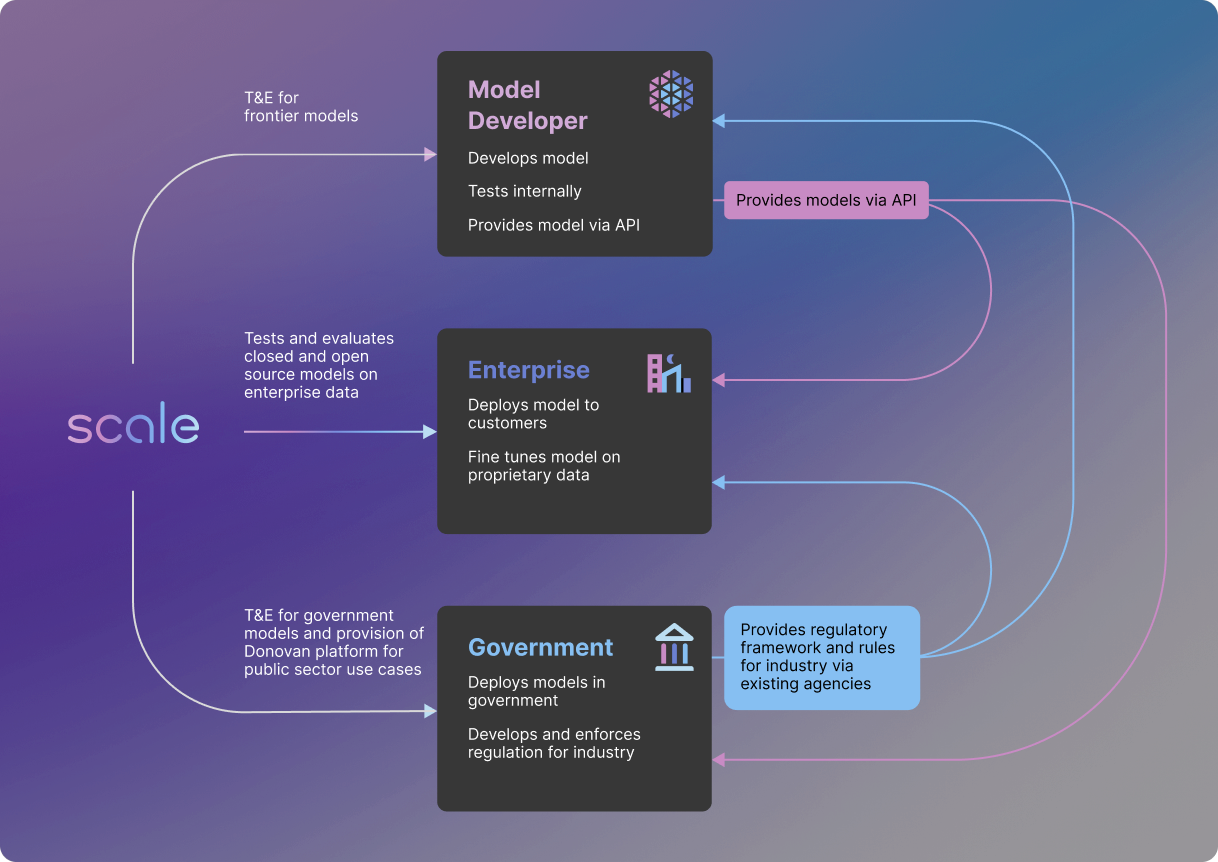
These groups must align to steer AI progress toward democratic principles and the greater social good. Scale aims to provide the testing tools and frameworks to empower ethical development. Regulation and standards can foster accountability while allowing room for ongoing advances.
With comprehensive testing baked into workflows, sharing best practices, and aligning on ethical AI as a collective mission, the AI community can build trust and realize the technology's benefits. Scale sees robust test and evaluation ecosystems as central to this vision.
According to Scale, developing rigorous testing standards and best practices is critical as AI rapidly achieves new capabilities and permeates high-impact fields like finance, healthcare, education, and government. The company was selected by the White House to evaluate AI systems from companies like Anthropic, Google, and Meta for risks of bias, misinformation, and deception ahead of the AI Village at DEF CON 2023. This reflects Scale's emerging leadership in ensuring trustworthy AI development.
Scale's T&E offering is now available to select customers who are at the forefront of LLM development. Components include continuous evaluations, red team penetration testing, bias evaluations, and certifications to verify AI systems meet safety and capability requirements before full deployment.
As LLMs become increasingly integrated into diverse sectors from healthcare to national defense, their impact grows exponentially. Recognizing the balance between AI's advantages and potential challenges, Scale is committed to fostering safe and effective AI deployment through its rigorous evaluation platform.
With their extensive industry experience, Scale aims to pioneer research and tooling to make AI trustworthy amid rapid technological change. Broader collaboration on safety standards across the AI community will be key to realizing AI's benefits while mitigating risks.