
Stability AI, creator of text-to-image generator Stable Diffusion, has unveiled its newest product, Stable Audio. Stable Audio allows users to generate original music and sound effects using AI technology through a simple web interface.
The new product represents Stability AI's expansion into audio generation and music creation. According to a statement from Stability AI CEO Emad Mostaque, Stable Audio aims to "empower music enthusiasts and creative professionals" by providing an AI tool to assist with generating new content.
In our testing, Stable Audio stands out as one of the most impressive generative audio solutions available. It can produce high quality, commercially viable original compositions tailored to prompts. This represents a potential game-changer in AI-generated audio content.
Importantly, Stability AI has stated that they will be releasing an open source model trained on different data separately, aligning with their commitment to open and accessible AI development.
Early audio samples demonstrate Stable Audio's potential for creating diverse musical compositions tailored to user prompts. For instance, a request for "Mellow reggae music relaxing on the beach" produced an atmospheric, emotionally evocative piece (see below).
The product can generate full musical audio encompassing a range of instruments, individual stems featuring a single instrument or group of instruments, as well as sound effects. Stability AI has provided a user guide with example prompts and additional recommendations to get the most out of Stable Audio.
The AI architecture behind Stable Audio is a latent diffusion model trained on a dataset of music and metadata provided by AudioSparx, a production music library. It consists of a variational autoencoder, text encoder, and conditioned diffusion model. It compresses audio into a compressed latent representation to allow faster generation.
The model is conditioned on text prompts encoded by a CLAP- model, as well as timing embeddings indicating the start time and total length. This allows control over the length and content of generated audio. The diffusion model itself is a 907M parameter U-Net that denoises the latent audio over time steps. Stability AI notes this architecture allows them to render 95 seconds of stereo audio at a 44.1 kHz sample rate in less than one second when run on an NVIDIA A100 GPU.
Stable Audio offers both free and paid subscription options. The company says the free version allows users to generate twenty 45-second audio samples monthly by providing text prompts describing musical genres, instruments, mood, tempo and other parameters. The "Pro" subscription enables 90-second downloads of higher quality audio that can be used commercially.
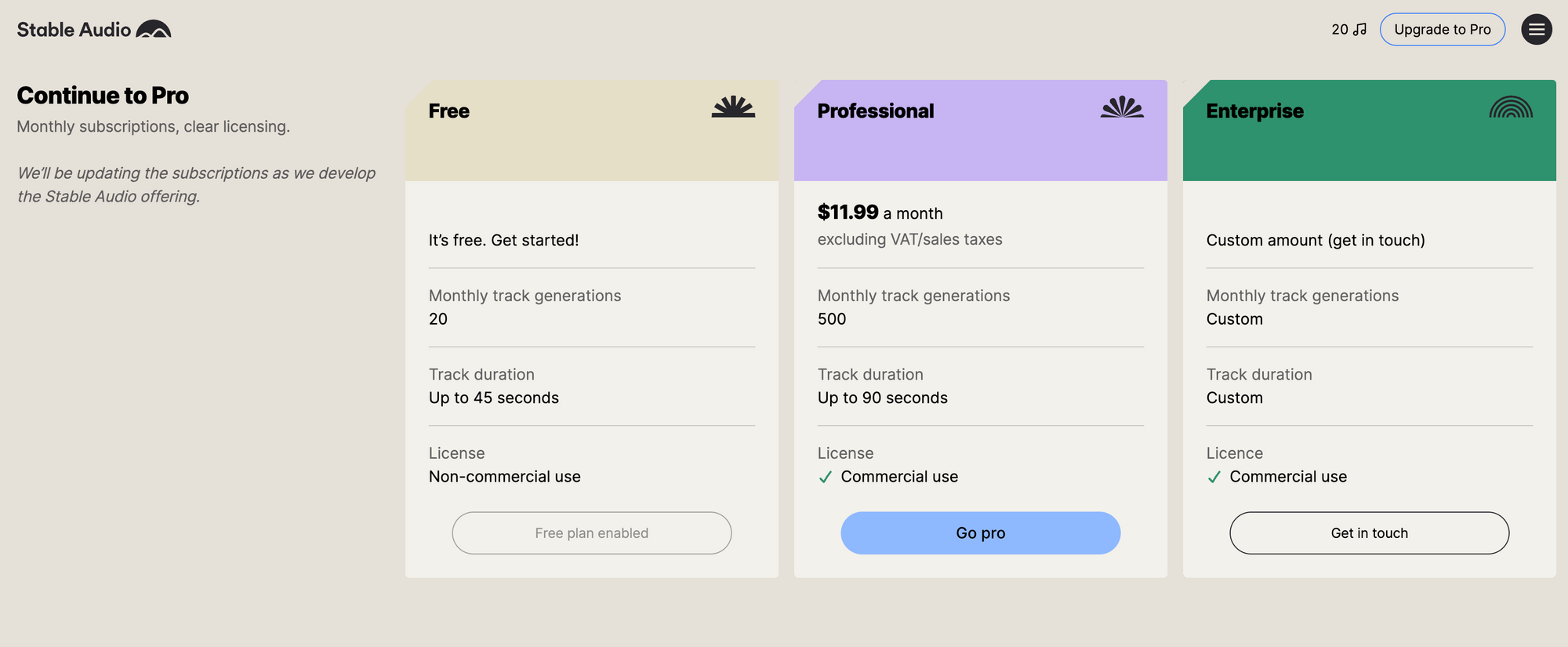
However, questions remain around ownership and usage rights for the AI-generated content. While Stable Audio's paid license permits commercial use, there are still usage limitations. In the company's terms of service, they note:
If at any point the usage of a commercial product incorporating Content produced by the Services is greater than 100,000 monthly active users in the preceding calendar month, you must request an Enterprise Tier license from us, which we may grant to you in our sole discretion, and you are not authorized to continue to make use of the Services, previously generated Content, or new Content unless or until we expressly grant you such rights.

Entering the audio generation market is a strategic move for Stability AI, offering a new set of tools that could recalibrate industry standards. The anticipated open-sourced model could be another disruptive element, broadening access and fostering innovation across the creative audio spectrum. Stable Audio is now available at www.stableaudio.com. Stability AI encourages users to provide feedback to aid further development.