
Stability AI, the company behind the popular AI art generator Stable Diffusion, has just unveiled a new open-weight model, Stable Audio Open. It is designed to generate short audio samples, sound effects, and production elements based on text prompts.
Stable Audio Open can create up to 47 seconds of audio from a simple text description. For example, if you input "Rock beat played in a treated studio," it will generate a unique rock-themed drum beat. It's a fun tool for musicians, sound designers, and audio enthusiasts to experiment with.
Now you may be thinking, "Wait...don't they already have Stable Audio?". And you would be correct. So, how's it different?
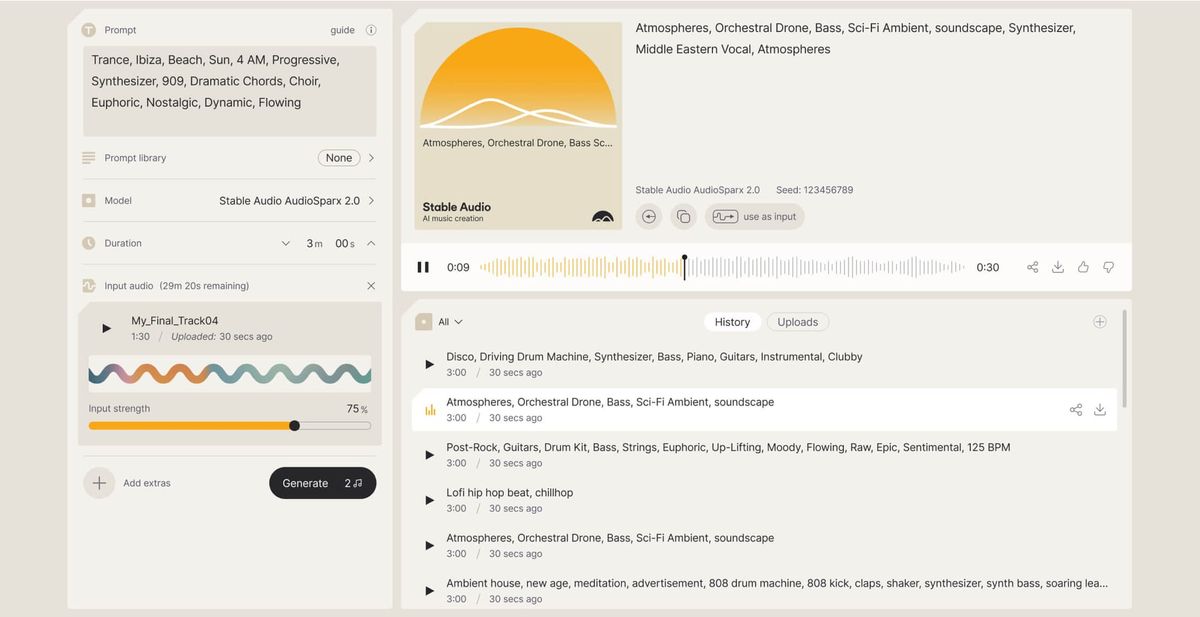
Well, firstly, Stable Audio is a commercial product while Stable Audio Open is free. Stable Audio is also more advanced and focused on creating full, coherent tracks with a musical structure of up to three minutes. It also offers features like audio-to-audio generation and multi-part musical compositions.
Stable Audio Open, on the other hand, is more of an introduction to generative AI for sound design. It's great for creating short clips, sound effects, and playing with audio variations, but it's not designed for full songs or vocals.
Stability AI says the model is trained on a large dataset of royalty-free audio recordings from FreeSound and the Free Music Archive, ensuring respect for creator rights. It utilizes an autoencoder to manage waveform lengths, text embedding for text conditioning, and a transformer-based diffusion model.
There are a few limitations to consider. Firstly, it can't produce realistic vocals. It also performs better with English descriptions and doesn't cater equally to all music styles and cultures, which the company attributes to the training data. Also, you should know that even though it is an open-weight model, it comes with a license agreement that prohibits commercial use.
Stable Audio Open's release comes amidst growing concerns about copyright in the AI music generation space. Major labels like Sony Music have recently warned AI companies against unauthorized use of their content for training audio generators, and the state of Tennessee has passed legislation aimed at curbing AI abuses in music.
So, if you're an audio enthusiast, why not give it a try? You can download the model from Hugging Face and start exploring the world of AI-generated sound!