Anthropic has published a case study analyzing techniques to improve Claude's ability to recall information from long documents. The study focused on Claude's 100,000 token context window, evaluating two prompt optimization methods:
- Extracting reference quotes relevant to the question before answering
- Supplementing the prompt with examples of correctly answered questions about other sections of the document
Researchers used daily public government transcripts, split into sections, to generate multiple choice questions with one correct answer. They tested Claude's recall on stitched-together "collage" documents at 75K and 90K token length using four different prompting strategies:
- Base Strategy - a direct query to Claude.
- Nongov examples - introducing two unrelated general knowledge questions.
- Two examples - presenting two random questions from the document.
- Five examples - similar to the third, but with five questions.
The study found that while using a scratchpad and question examples improved Claude's recall for information at the beginning and middle of long documents, it slightly decreased performance for content at the very end. This drop could be because of the examples lengthening the prompt, creating more distance between the question and relevant info at the end. However, only a small portion of data is located at the end, so this minor decline shouldn't outweigh the overall benefits of examples. But it does emphasize the need to position instructions last in prompts, ensuring models retain optimal memory of them.
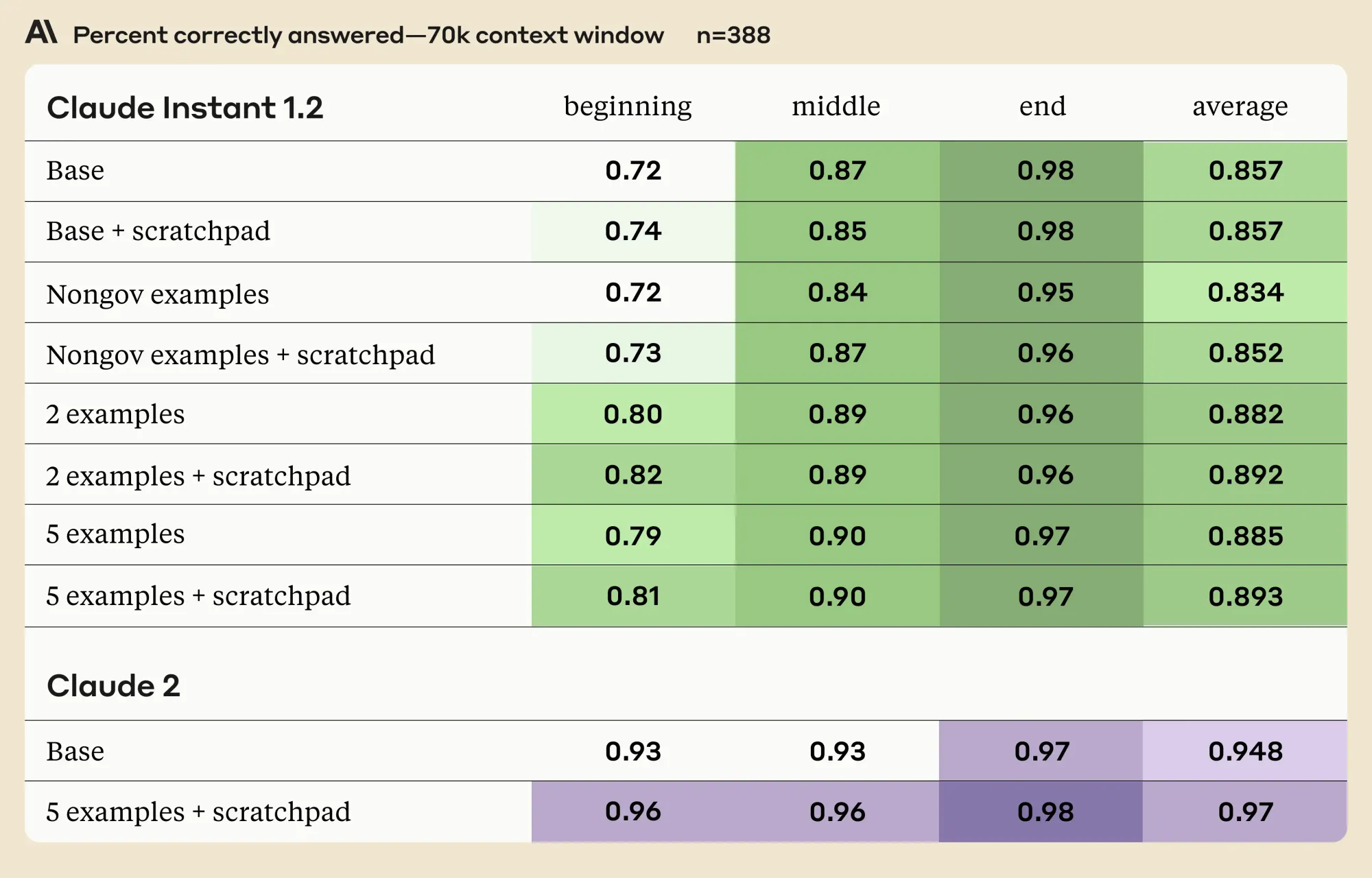
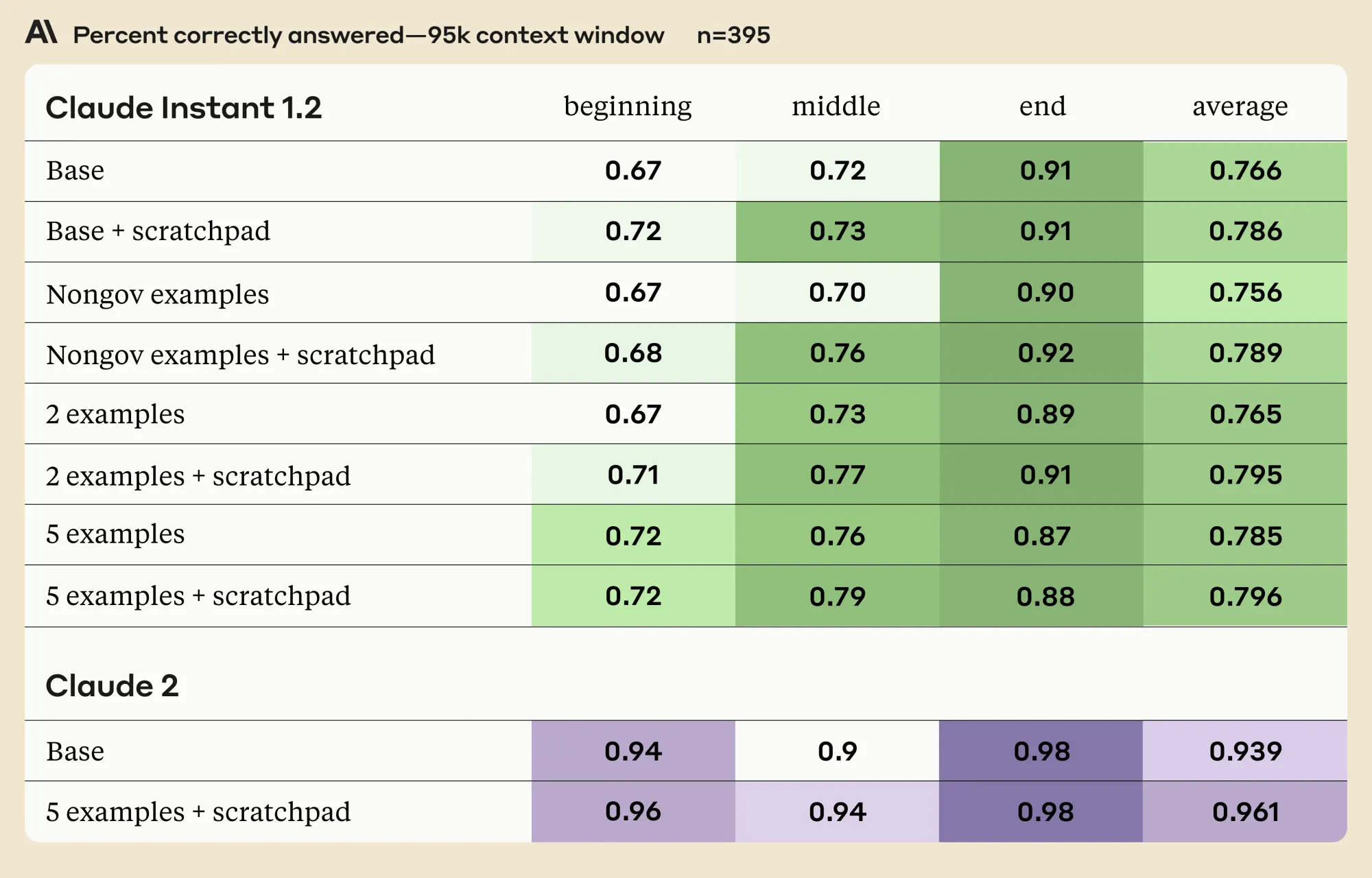
Additionally, while the absolute increase for Claude 2 from prompting seems small, it equates to a sizable 36% reduction in errors, demonstrating the technique's usefulness.
Anthropic also provided some helpful takeaways that can be used for writing long-context Q&A prompts:
- Use many examples and the scratchpad for best performance on both context lengths.
- Pulling relevant quotes into the scratchpad is helpful in all head-to-head comparisons. It comes at a small cost to latency, but improves accuracy. In Claude Instant’s case, the latency is already so low that this shouldn’t be a concern.
- Contextual examples help on both 70K and 95K, and more examples is better.
- Generic examples on general/external knowledge do not seem to help performance.
Claude's 100K token context window holds immense potential. Overall, the study demonstrates how through diligent prompt engineering, its recall capability over lengthy contexts can be significantly enhanced. With continued exploration and studies like this one from Anthropic, we may unlock even greater depths of precision and comprehension from large language models.