
Anthropic has unveiled Claude 3.7 Sonnet, its most advanced AI model to date and what it calls "the first hybrid reasoning model on the market." The new model can either respond immediately like traditional AI systems or engage in a visible, step-by-step thinking process before delivering answers—mimicking how humans toggle between quick reactions and deeper reflection.
Key Points
- Claude 3.7 Sonnet offers both instant responses and extended thinking modes within a single model, unlike competitors that separate these capabilities.
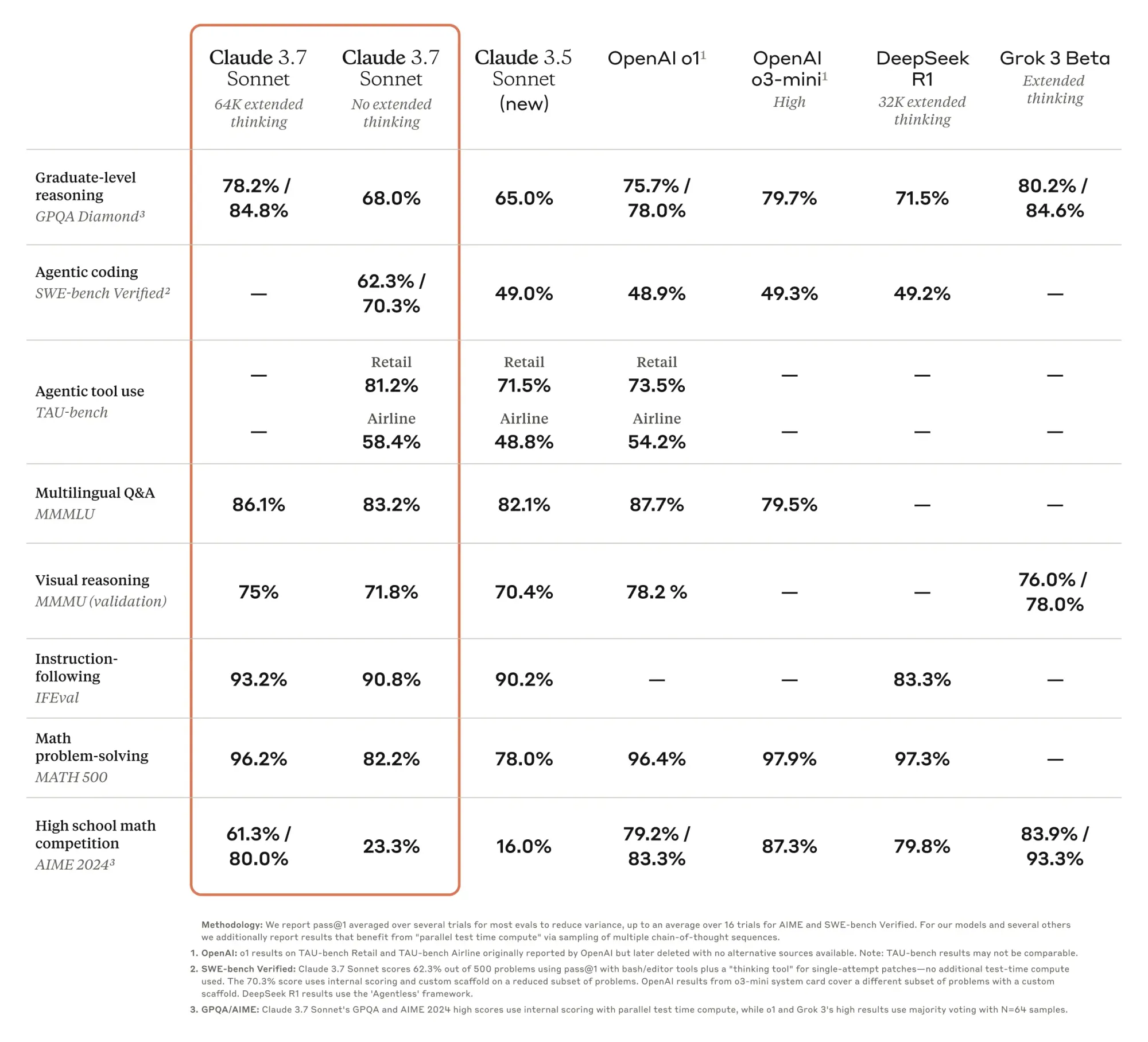
- The model excels at coding tasks, achieving state-of-the-art results on real-world software benchmarks like SWE-bench Verified.
- Alongside the model, Anthropic launched Claude Code, an agentic terminal tool that can read codebases, edit files, and even push to GitHub repositories.
- Pricing remains unchanged at $3 per million input tokens and $15 per million output tokens, with thinking tokens included in the output cost.
Claude 3.7 Sonnet represents a shift in how AI models tackle complex problems. Unlike competitors that separate quick-response and deep-reasoning capabilities into different models, Anthropic has integrated both functions into a single system.
"Just as humans use a single brain for both quick responses and deep reflection, we believe reasoning should be an integrated capability of frontier models rather than a separate model entirely," Anthropic stated in its announcement.
For developers using the API, Anthropic is providing granular control. You can specify exactly how many tokens—up to the 128K output limit—the model can use for reflection before responding. This creates a customizable quality-versus-speed tradeoff that helps organizations balance performance needs with cost considerations.
Anthropic has also pivoted away from optimizing for academic benchmarks like math competitions toward capabilities that "better reflect how businesses actually use LLMs."
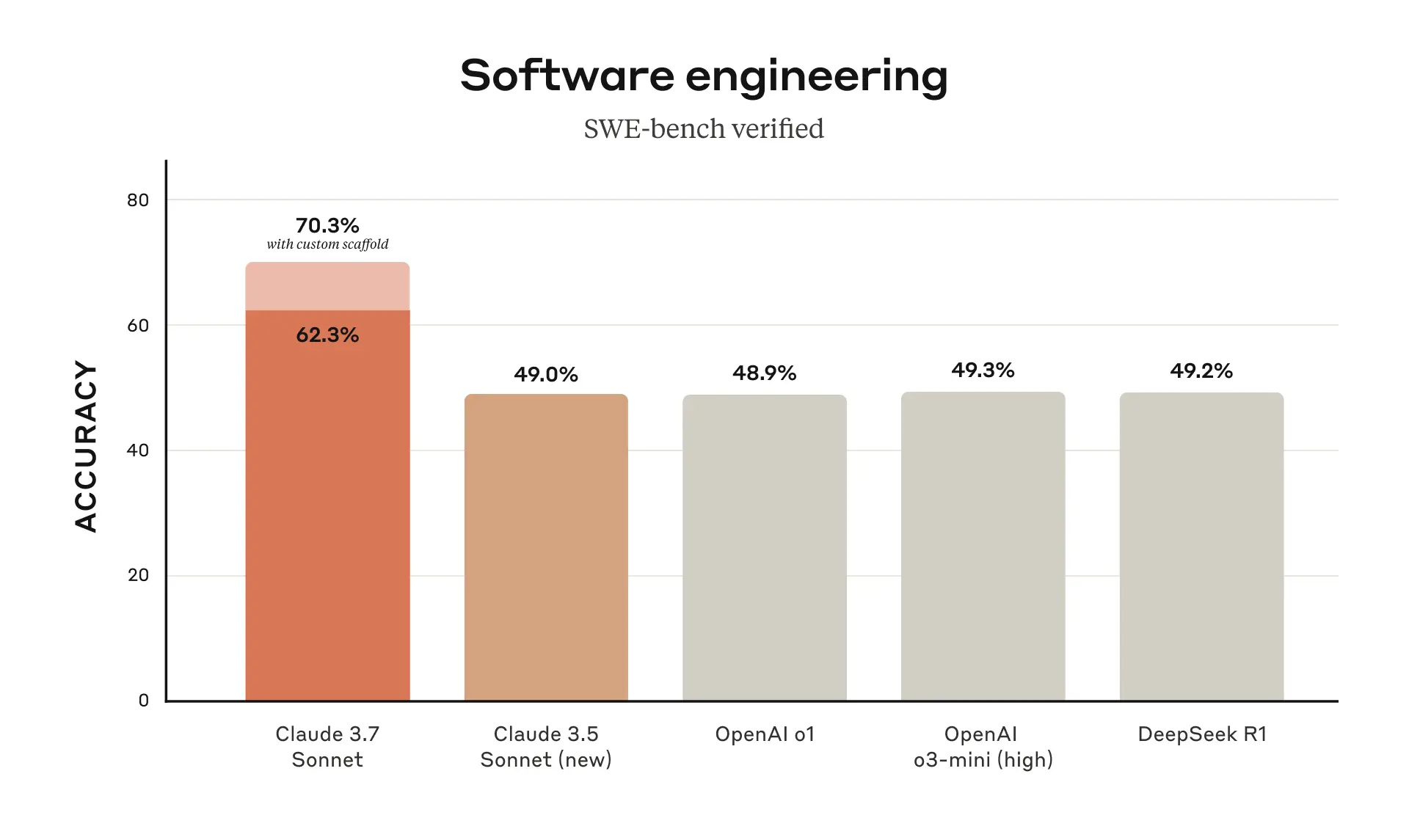
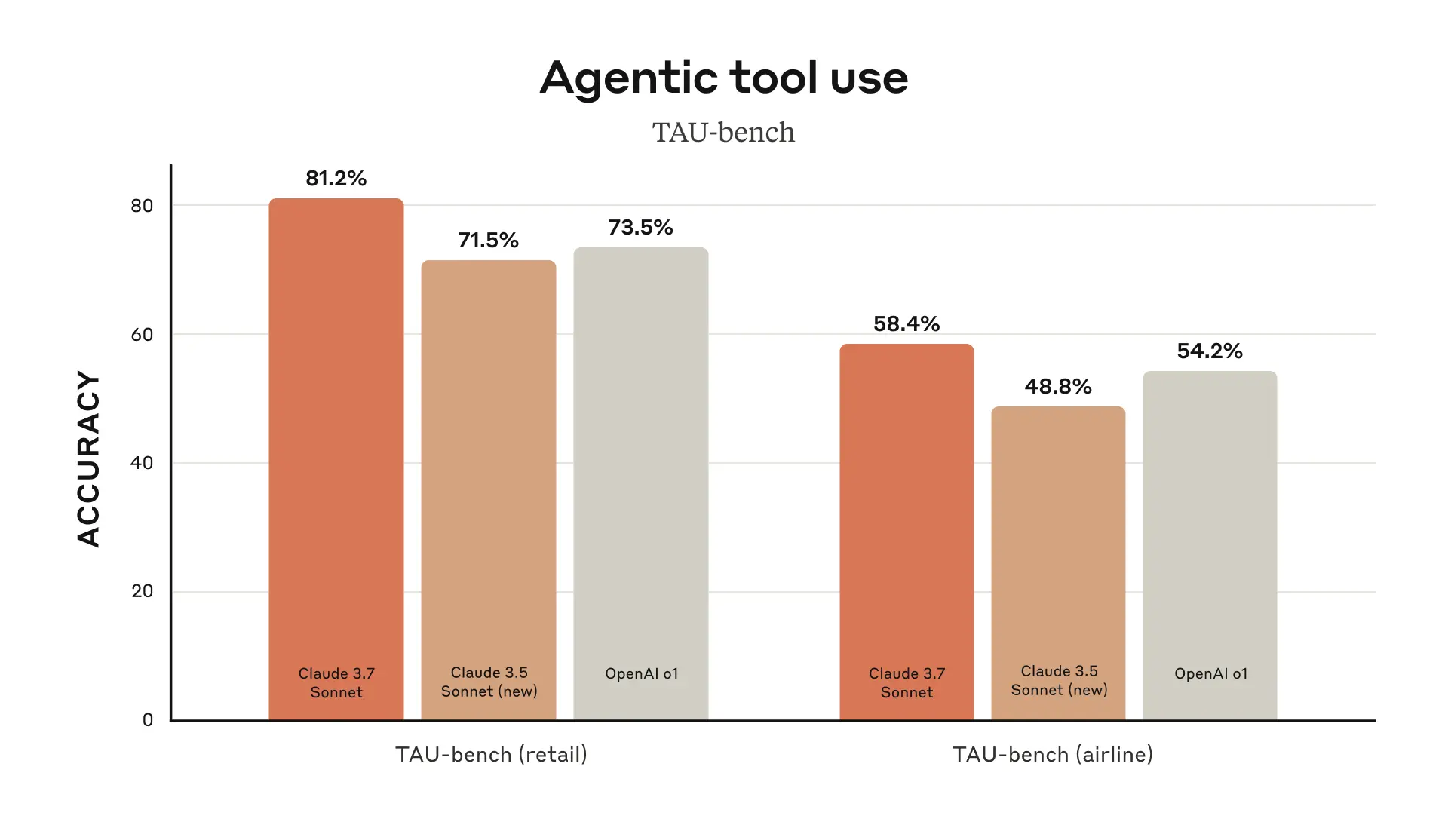
The model shows particular strength in coding tasks. According to Anthropic's testing, Claude 3.7 Sonnet achieves state-of-the-art performance on SWE-bench Verified, which evaluates AI models' ability to solve real-world software issues, and on TAU-bench, a framework testing AI agents on complex tasks with user and tool interactions.
This is saying a lot, because Claude 3.5 Sonnet was already the best coding AI model—even according to OpenAI's newest SWE-Lancer benchmark. These improvements have been corroborated by several key companies. Cursor noted that Claude is "best-in-class for real-world coding tasks," while Cognition found it "far better than any other model at planning code changes and handling full-stack updates."
To complement the model release, Anthropic has introduced Claude Code, an agentic coding assistant available as a limited research preview. This terminal-based tool can search and read codebases, edit files, write and run tests, and even commit changes to GitHub repositories.
"Claude Code completed tasks in a single pass that would normally take 45+ minutes of manual work," Anthropic claimed, though they acknowledged it remains "an early product." The company has also extended its GitHub integration to all Claude plans, allowing developers to connect their code repositories directly to the AI assistant.
Claude 3.7 Sonnet costs the same as its predecessors: $3 per million input tokens and $15 per million output tokens—including the "thinking tokens" used in extended reasoning mode.
The extended thinking capability is available across all paid Claude plans, including Pro, Team, and Enterprise, as well as through the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI. Only free tier users won't access the extended thinking features.
In its system card, Anthropic highlighted safety improvements, noting that Claude 3.7 Sonnet "makes more nuanced distinctions between harmful and benign requests, reducing unnecessary refusals by 45% compared to its predecessor."