OpenAI has just released their first open weight models in over five years: gpt-oss-120b and gpt-oss-20b. The models are available under the flexible Apache 2.0 license, these models outperform similarly sized open models on reasoning tasks, demonstrate strong tool use capabilities, and are optimized for efficient deployment on consumer hardware. This guide will walk you through various ways to run the gpt-oss-20b locally on your personal computer. We recommend at least 16GB of memory.
Option 1: The Easiest Path—Use Ollama
If you’re just looking to try gpt-oss with zero config headaches, Ollama is probably the smoothest route.
Ollama is a free tool that lets you run open-weight LLMs on your local machine using a simple terminal interface and a powerful backend that handles GPU/CPU optimization under the hood. It supports macOS (Apple Silicon and Intel), Windows, and Linux.
To run gpt-oss via Ollama:
- Install Ollama from the official site.
- Open Terminal and type:
ollama run gpt-oss:20bThat’s it. You’re in.
Ollama downloads the model and spins up a chat interface. You can also use it with apps like Chatbot UI or Open WebUI.
Option 2: LM Studio—A GUI for Everyone
LM Studio is a slick, cross-platform app that gives you a full-featured desktop GUI for working with local models like gpt-oss.
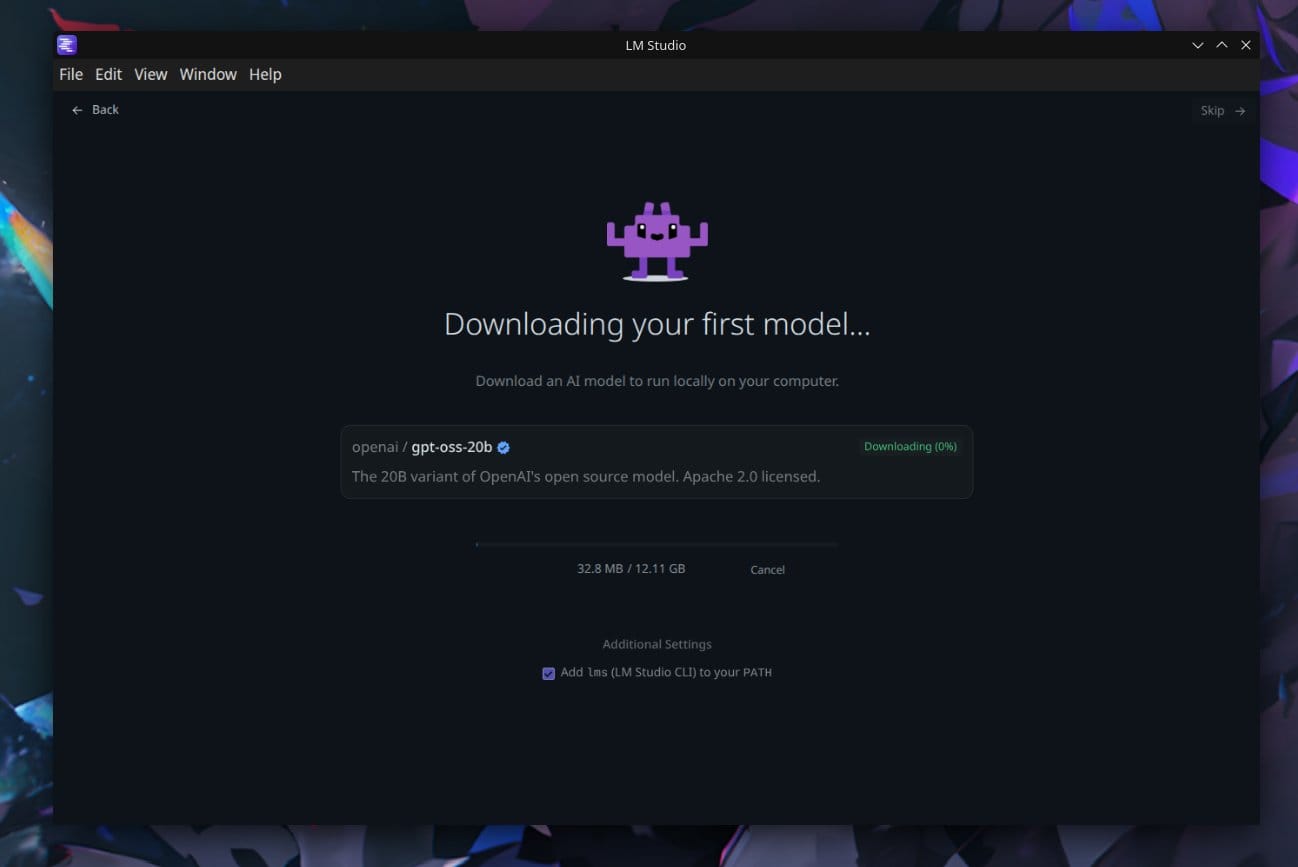
LM Studio supports downloading gpt-oss directly from Hugging Face and running it with just a few clicks. You can:
- Set reasoning effort
- Chat via the built-in UI
- Serve the model locally via an OpenAI-compatible API
When you use OpenAI's gpt-oss in LM Studio, you can choose the model's reasoning effort! pic.twitter.com/H2Inj5HBv4
— LM Studio (@lmstudio) August 5, 2025
This makes LM Studio ideal for devs who want to test gpt-oss in their apps using familiar OpenAI API calls, but without OpenAI’s servers—or pricing.
Option 3: Roll Your Own—Running gpt-oss Locally via Transformers
If you’re a developer or researcher who wants full control, you can download gpt-oss from Hugging Face and run it manually using libraries like transformers, vLLM, or llama.cpp.
Here’s a simplified approach using Hugging Face Transformers. First install the dependencies and set up your environment:
pip install -U transformers kernels torch
You can then run the model with the following snippet:
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
Alternatively, you can run the model via Transformers Serve to spin up a OpenAI-compatible webserver:
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-20b
For GPU acceleration and larger batch inferencing, you can also explore:
- vLLM for optimized serving with paging and multi-query support
- llama.cpp for lightweight, quantized CPU/GPU inference
Running OpenAI’s gpt-oss models locally isn’t just a fun weekend project—it’s a genuinely useful way to experiment with cutting-edge AI without the usual trade-offs. No cloud costs. No rate limits. No internet connection required. Whether you’re building tools, testing prompts, or just chatting with your laptop in airplane mode, local LLMs put you in the driver’s seat.
And thanks to tools like Ollama, LM Studio, and the open ecosystem around Hugging Face, getting started is easier than ever. With just a few clicks or commands, you can bring a slice of OpenAI’s frontier research right to your desktop—no API key needed.