
Meta has announced the release of Llama 3.2, a significant upgrade to its family of open AI models that introduces lightweight versions for edge devices and new vision capabilities. This latest version is all about making powerful AI capabilities more accessible and versatile.
The Llama 3.2 lineup includes four new models. Two smaller models, 1B and 3B parameters, are designed for edge and mobile devices, while larger 11B and 90B parameter models bring vision capabilities to the Llama ecosystem.
The 1B and 3B models represent a major step forward for on-device AI. Supporting a context length of 12K tokens, these models excel at tasks like summarization, instruction following, and text rewriting – all while running locally on edge devices. Meta claims these models achieve state-of-the-art performance for their size class.
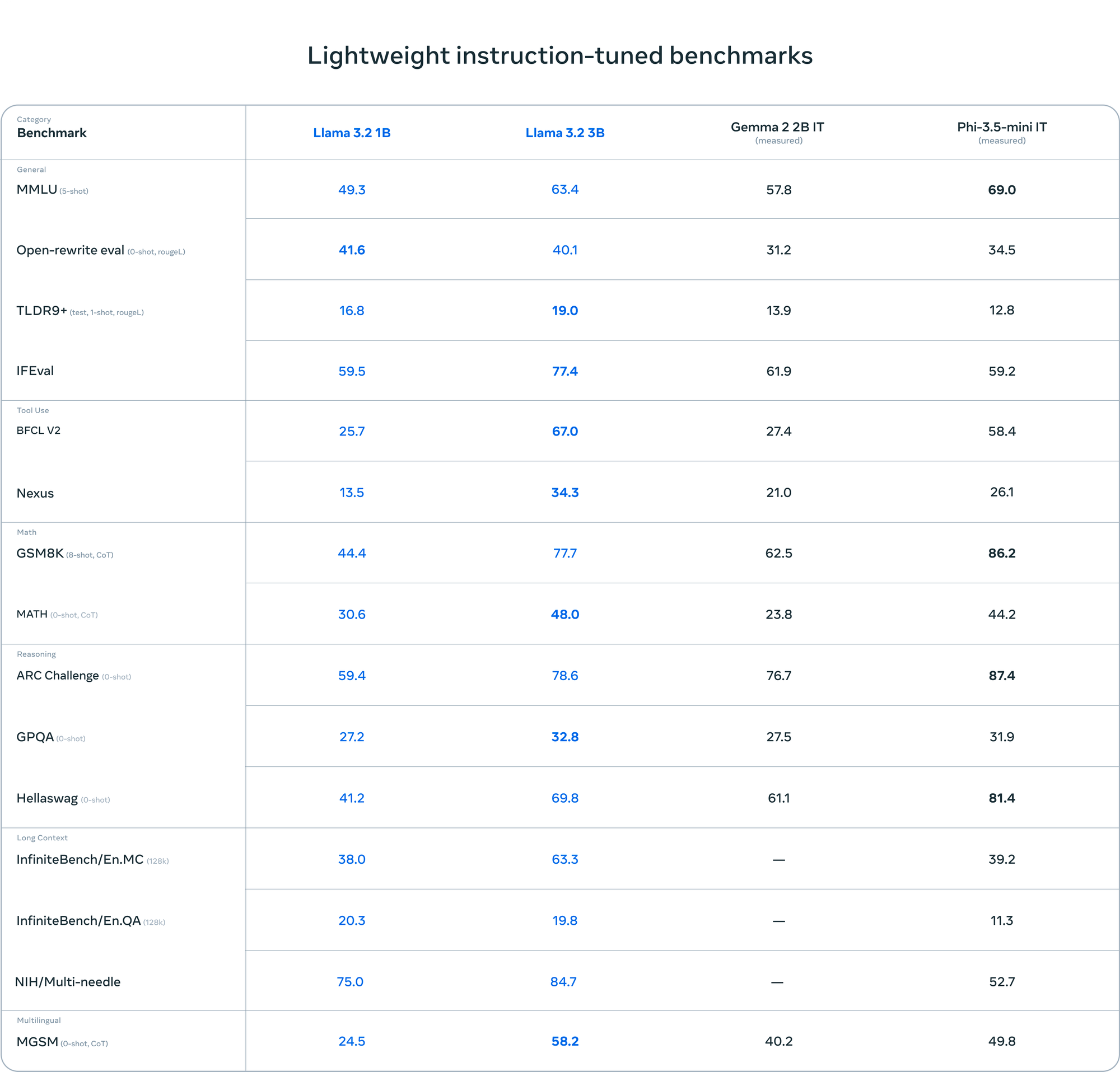
Importantly, these lightweight models launch with day-one support for hardware from Qualcomm and MediaTek, along with optimizations for Arm processors. This broad compatibility should accelerate adoption across a wide range of mobile and IoT devices.
The 11B and 90B vision models are Llama's first foray into multimodal AI. These models can understand and reason about images, enabling tasks like document analysis, image captioning, and visual question-answering. Meta reports that their performance is competitive with leading closed-source models in image recognition and visual understanding benchmarks.
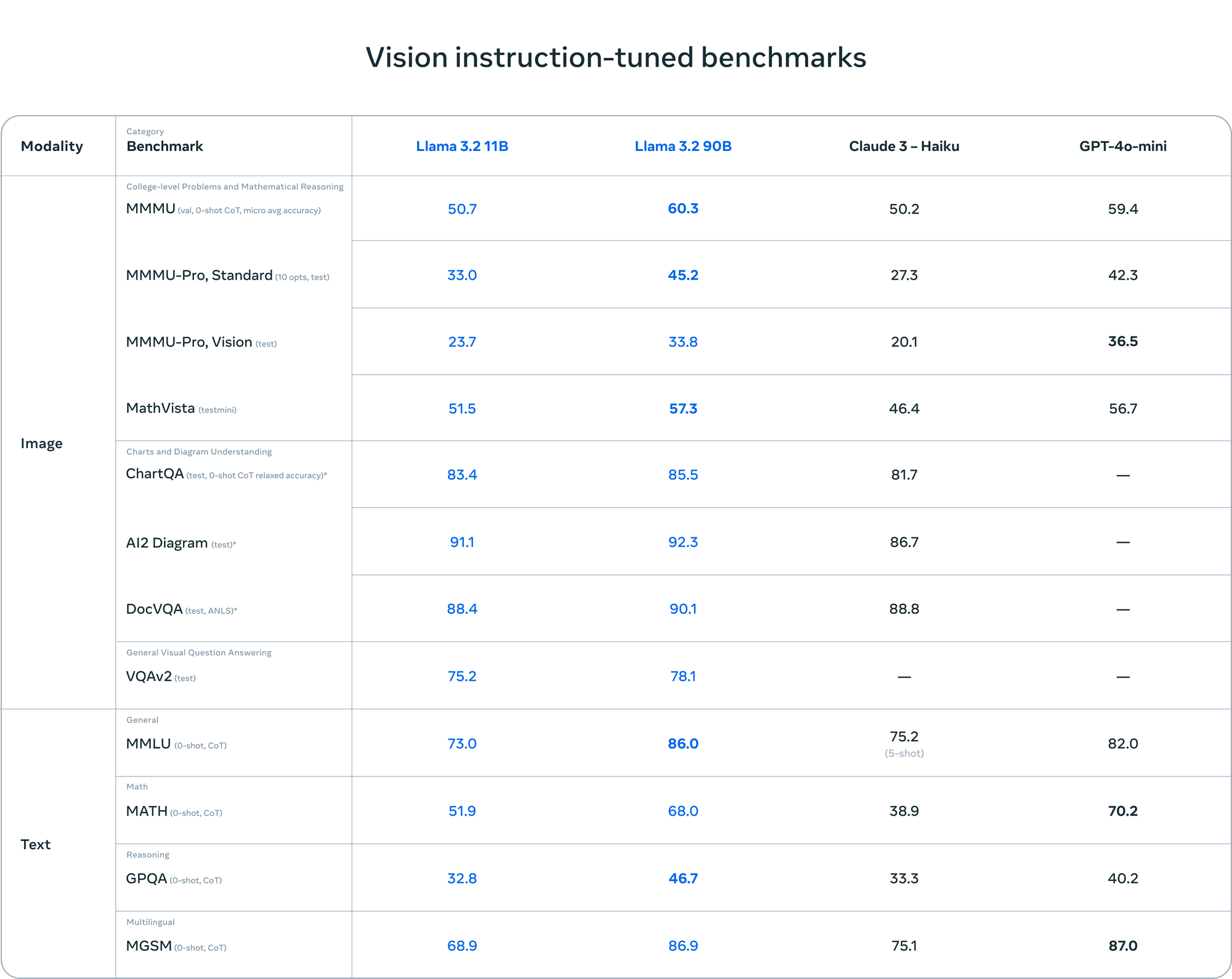
Note, the new vision models can be drop-in replacements for the existing text-only counterparts. This approach allows developers to easily add image understanding to existing Llama-based applications.
Alongside the new models, Meta is introducing Llama Stack Distribution to simplify and streamline how developers and enterprises can build applications around Llama.
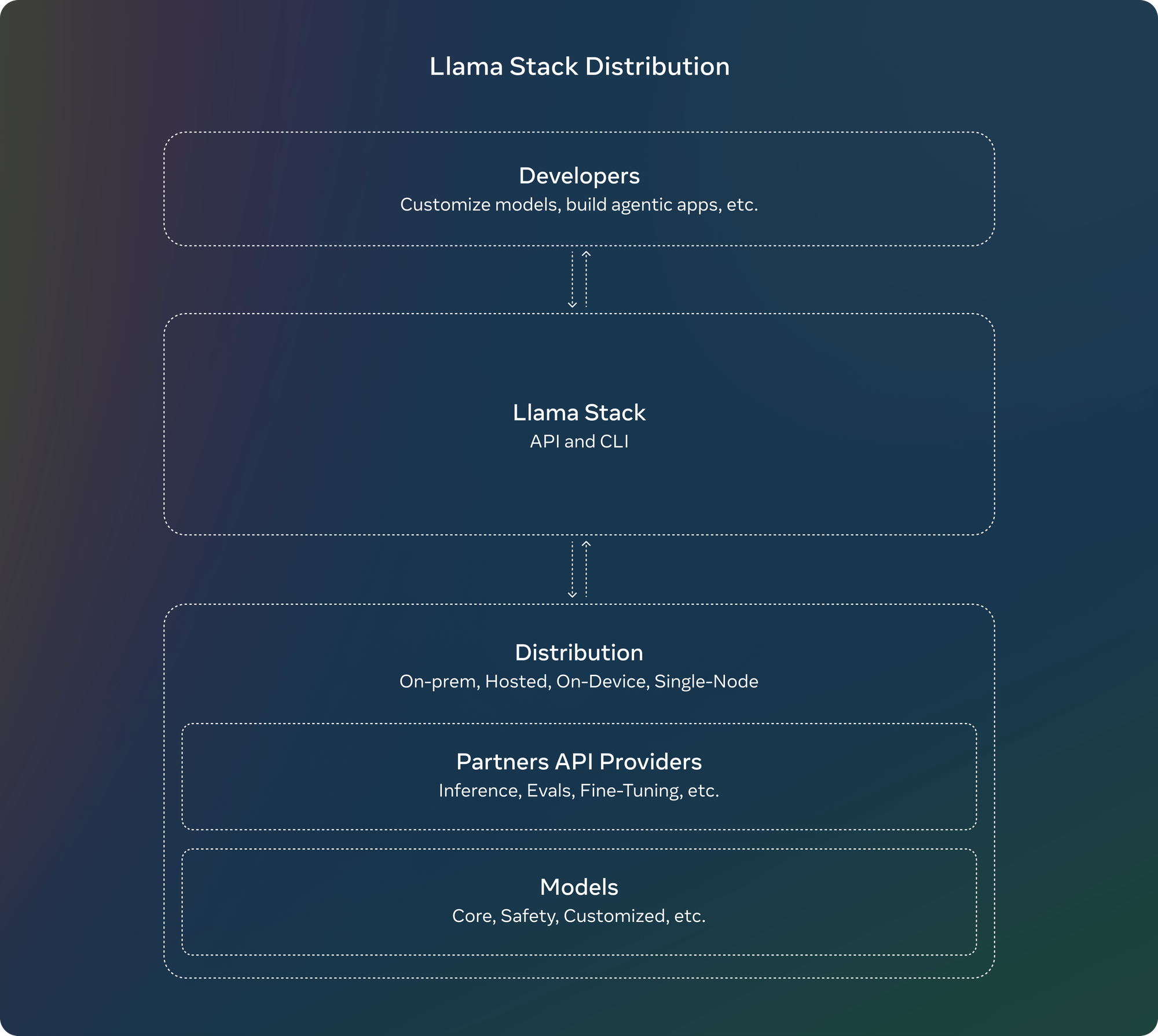
At the heart of this system is the Llama CLI, a command-line interface that simplifies building, configuring, and running Llama Stack distributions. This tool simplifies the deployment process, allowing developers to focus on application logic rather than setup complexities.
To ensure broad accessibility, Meta has provided client code in multiple programming languages, including Python, Node.js, Kotlin, and Swift, allowing integration into diverse applications and platforms.
Deployment flexibility is a key feature of Llama Stack. Pre-built Docker containers for the Distribution Server and Agents API Provider offer a consistent environment, reducing configuration errors. For different scales of operation, Meta has tailored solutions ranging from single-node distributions for individual machines to scalable cloud-based deployments through partnerships with AWS, Databricks, Fireworks, and Together AI.
On-device distributions are available on iOS through PyTorch ExecuTorch, facilitating the development of AI applications that run directly on mobile devices. This empowers developers to create apps with local AI capabilities, enhancing privacy and reducing latency.
Enterprises requiring in-house AI capabilities due to security, compliance, or performance considerations can leverage on-premises distributions supported by Dell Technologies.
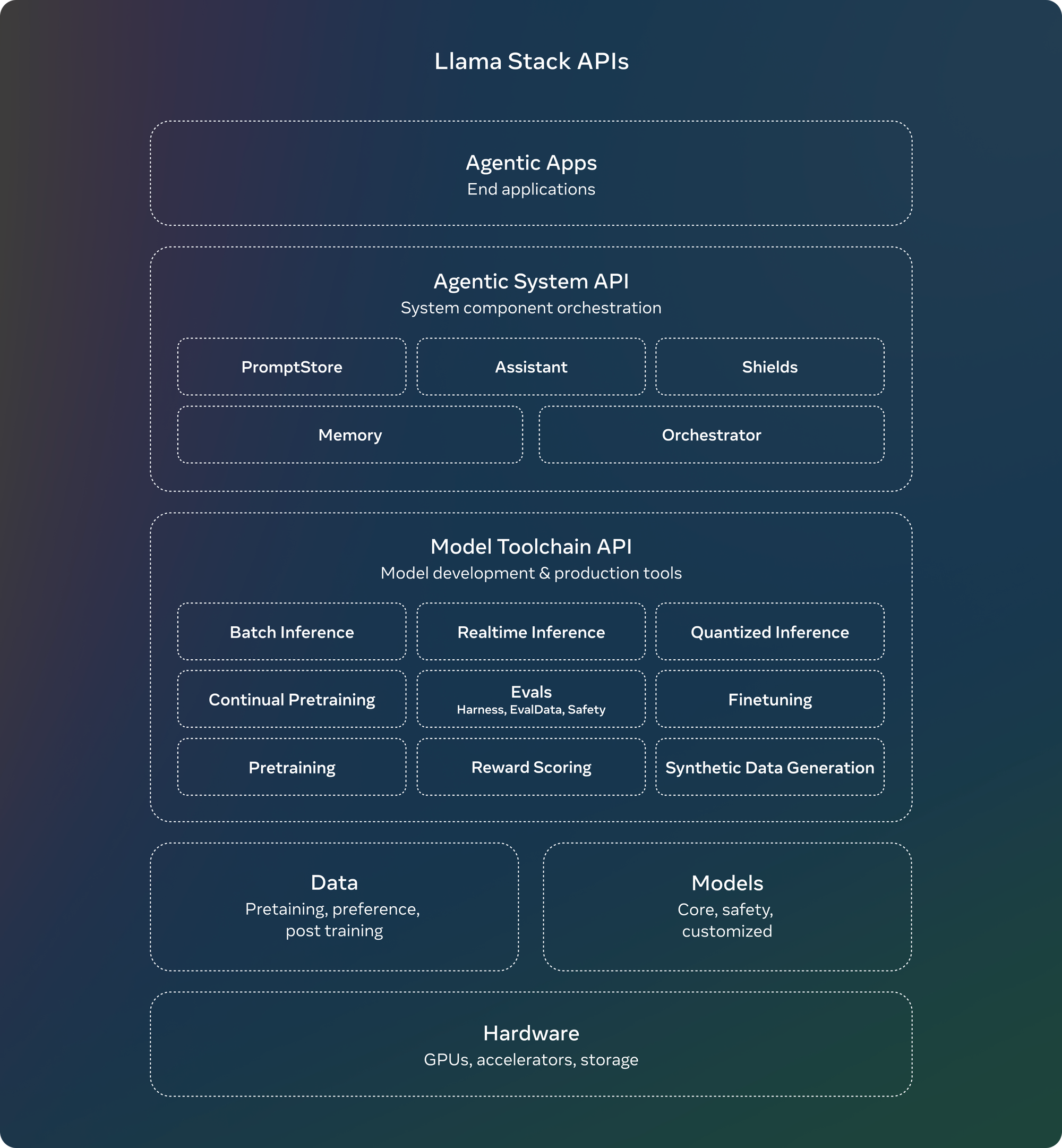
By packaging multiple API providers into a single endpoint and working closely with partners to adapt the Llama Stack APIs, Meta has created a consistent and simplified experience for developers across these diverse environments. This approach significantly reduces the complexity of building with Llama models, potentially accelerating AI innovation across a wide range of applications and use cases.
Meta also made some important updates on the safety front. The release includes Llama Guard 3 11B Vision for content moderation of image-text inputs and outputs. A smaller Llama Guard 3 1B model, optimized for edge devices, is also available.
Overall, Llama 3.2 represents a significant expansion of Meta's open AI efforts. Llama 3.2 models are available for download on the official Llama website and Hugging Face. You can also access the models through Meta’s ecosystem of partner platforms. The release includes models in BFloat16 format, with plans to explore quantized variants for even faster performance.