
Meta has unveiled Seamless Communications, a new family of AI-powered language translation models aiming to enable more natural, real-time communication across different languages. The suite consists of four models focused on improving expression, real-time translation, and overall translation quality.
- SeamlessExpressive: A model that aims to preserve expression and intricacies of speech across languages.
- SeamlessStreaming: A model that can deliver speech and text translations with around two seconds of latency.
- SeamlessM4T v2: A foundational multilingual and multitask model that allows people to communicate effortlessly through speech and text.
- Seamless: A model that merges capabilities from SeamlessExpressive, SeamlessStreaming and SeamlessM4T v2 into one.
SeamlessExpressive
A key innovation is SeamlessExpressive, a model created specifically to preserve the nuances of speech, such as tone, pacing, emphasis, and emotion, when translating between languages. Going beyond just word choice, these prosodic elements of speech carry important signals about a speaker's intent and state of mind. SeamlessExpressive is the first translation system open to the public that explicitly accounts for these intricate details. This model notably enhances speech-to-speech translation between six major languages, including English, Spanish, and Chinese.
You can try the SeamlessExpressive demo to create translations that follow your speech style.
SeamlessStreaming
The second component, SeamlessStreaming, focuses on minimizing lag time in translations to enable close to real-time conversations. Using a technique that starts translating before a speaker finishes talking, SeamlessStreaming can deliver speech and text translations with around just two seconds of latency while maintaining accuracy. This model supports an extensive range of languages, with automatic speech recognition in nearly 100 languages and speech-to-speech translation covering 36 languages.
SeamlessM4T v2
These new expressive and streaming models build on Meta's SeamlessM4T v2, an upgraded multilingual, multitask model that was first released in August. This foundational model handles speech-to-text, text-to-speech, speech-to-speech translation, and other modalities for nearly 100 languages with state-of-the-art quality. The V2 architecture enhancements, including a non-autoregressive decoder, helps improve consistency across different inputs and outputs.
Emphasizing Meta's commitment to open science, all four models are being released publicly, enabling further research and development in this dynamic field.
Accompanying these models are metadata, data, and data alignment tools, including an expansive corpus of speech and text alignments covering 76 languages. This corpus stands as the most voluminous public resource of its kind. Additionally, Meta introduces fairseq2, an advanced sequence modeling toolkit, and UnitY2, a novel architecture featuring a non-autoregressive text-to-unit decoder, further enhancing the models' capabilities.
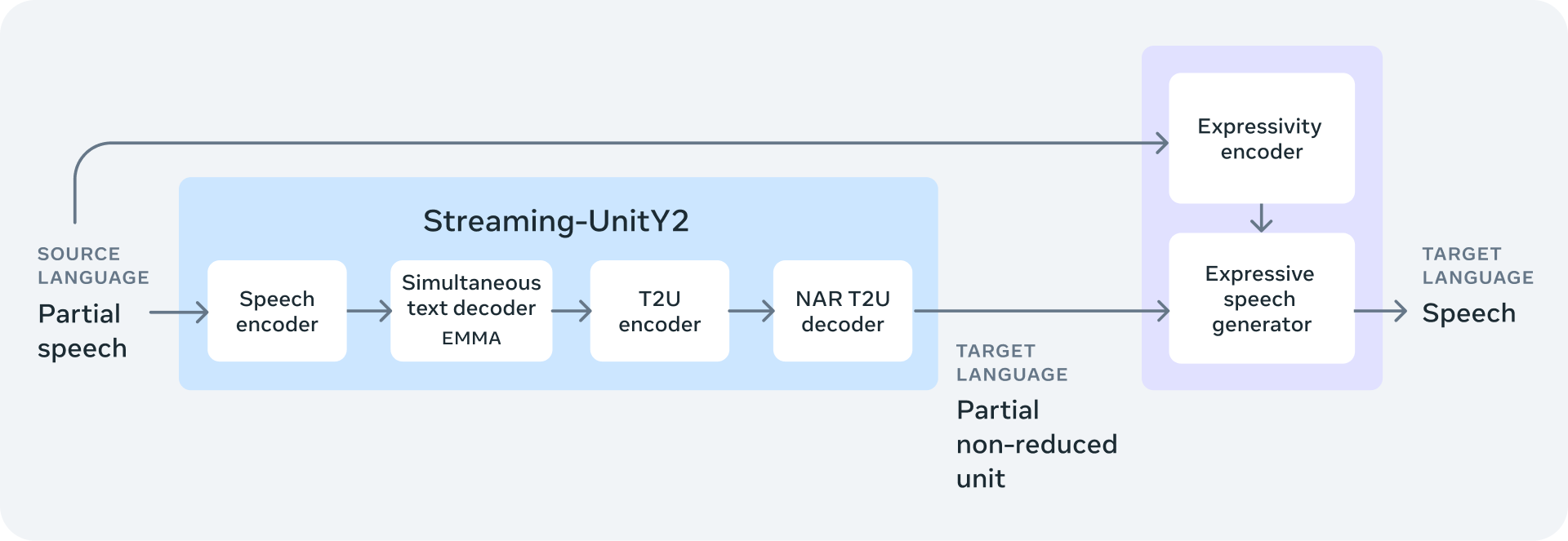
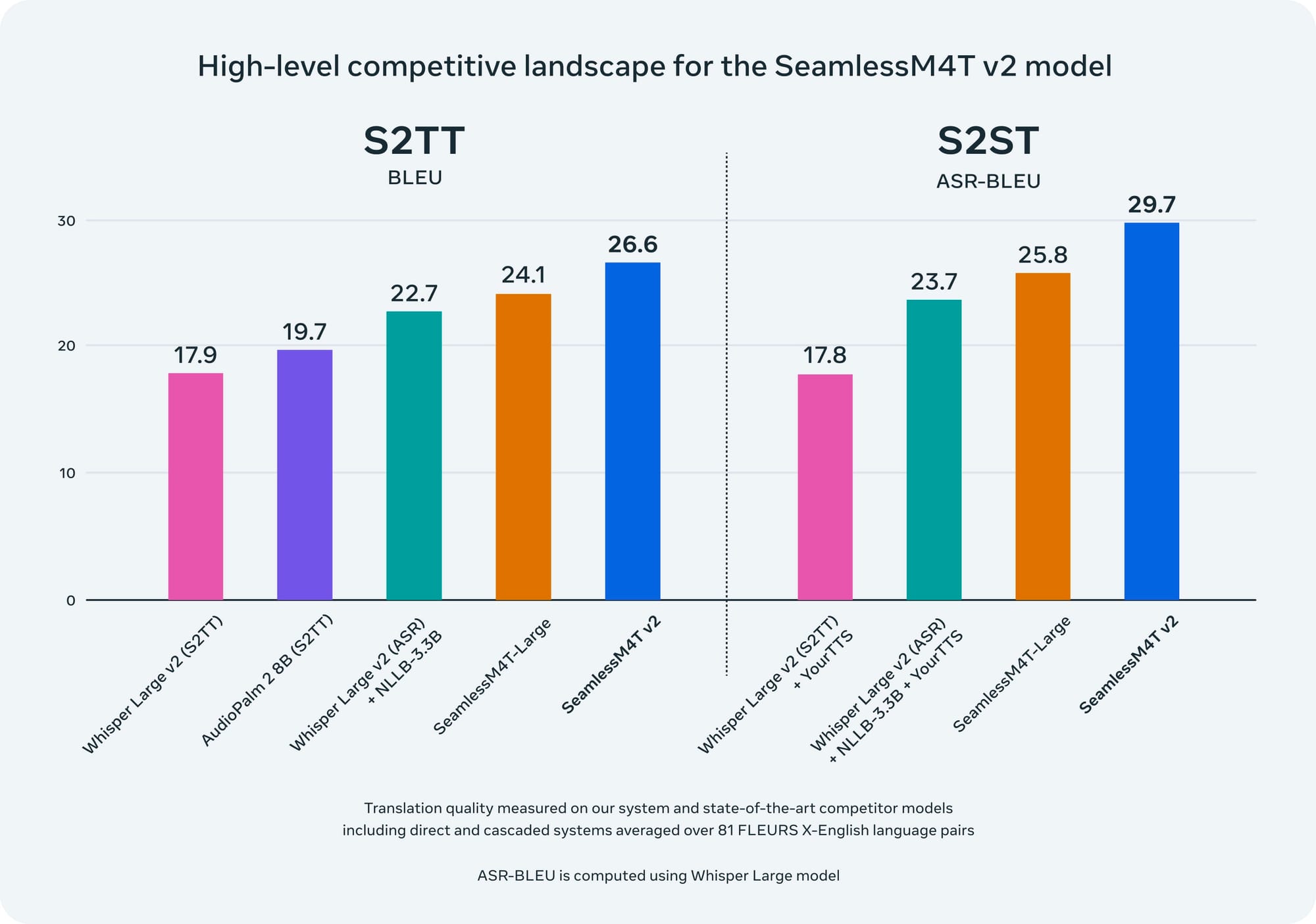
The enhancements in UnitY2 architecture have led to remarkable improvements in translation quality across various tasks. For instance, SeamlessM4T v2 now matches or exceeds the performance of leading models in automatic speech recognition and text-to-speech translation tasks.
Importantly,in developing these models, Meta also took steps to make them safer and more responsible. The company mitigated hallucinated toxicity in translations through data filtering and inference-time adjustments. They also introduced audio watermarking to establish verifiable audio provenance and encourage responsible use.
Meta’s suite of models marks a significant stride towards realizing a future where language differences cease to be barriers. As the company continues refining these models, the dream of a "universal translator" that allows seamless cross-cultural dialogue comes closer to reality.