
Mistral AI has released Mistral Large 2, the latest version of its flagship language model, boasting significant improvements in code generation, mathematics, and multilingual capabilities. The new 123 billion-parameter model features a 128,000-token context window and aims to challenge industry leaders in performance and efficiency.
Mistral Large 2 demonstrates impressive performance across various benchmarks. On code generation tasks like HumanEval and MultiPL-E, it outperforms Llama 3.1 405B (which Meta released yesterday) and scores just below GPT-4. In mathematics, particularly on the MATH benchmark (zero-shot, without chain-of-thought reasoning), Mistral Large 2 ranks second only to GPT-4o.
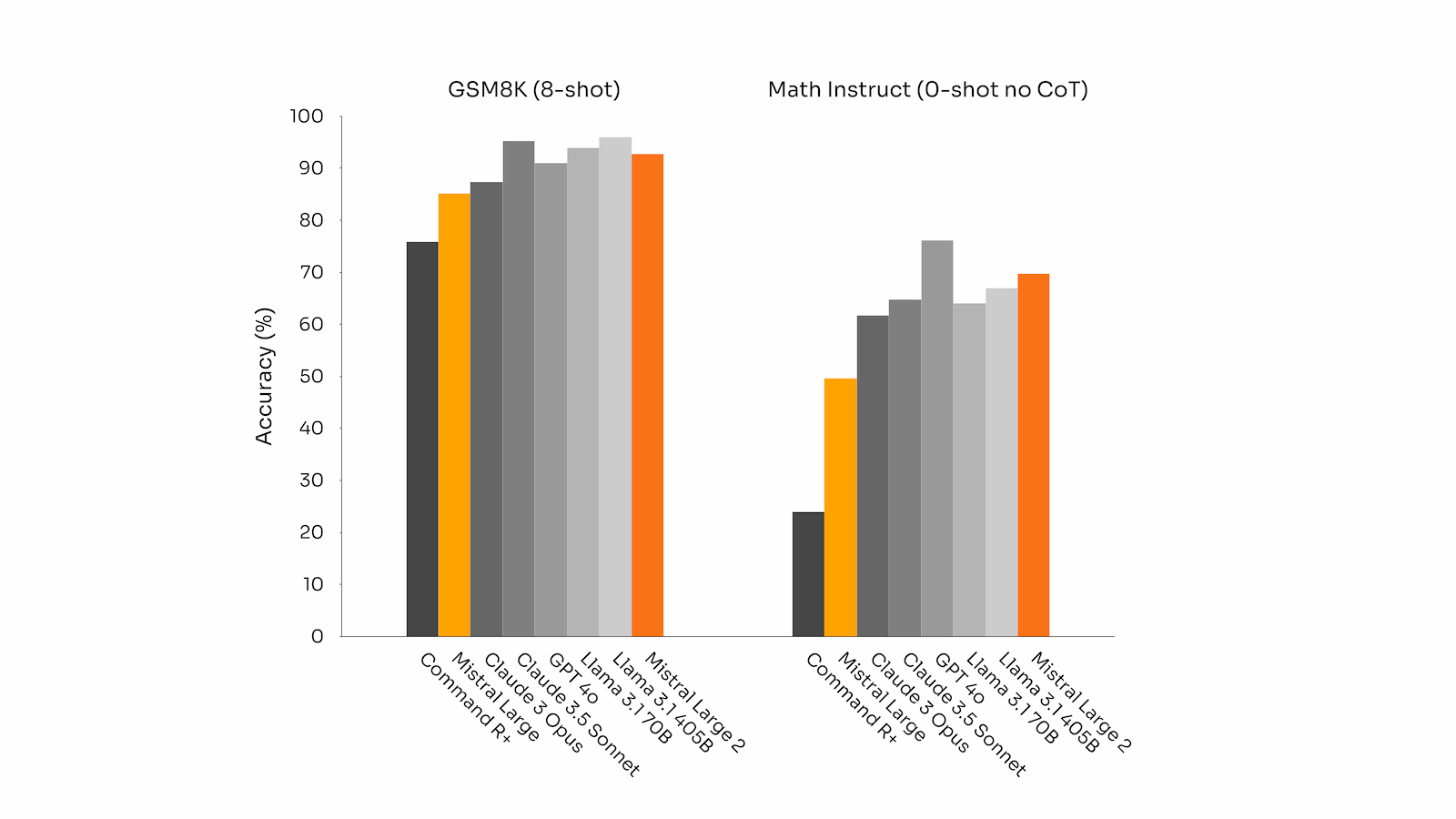
The model's multilingual capabilities have also seen a substantial boost. On the Multilingual MMLU benchmark, Mistral Large 2 surpasses Llama 3.1 70B base by an average of 6.3% across nine languages and performs on par with Llama 3 405B.
Despite its large size, Mistral AI designed the model for single-node inference, emphasizing throughput for long-context applications. The company is making Mistral Large 2 available on its platform, la Plateforme, and has released the weights for the instruct model on HuggingFace for research purposes.
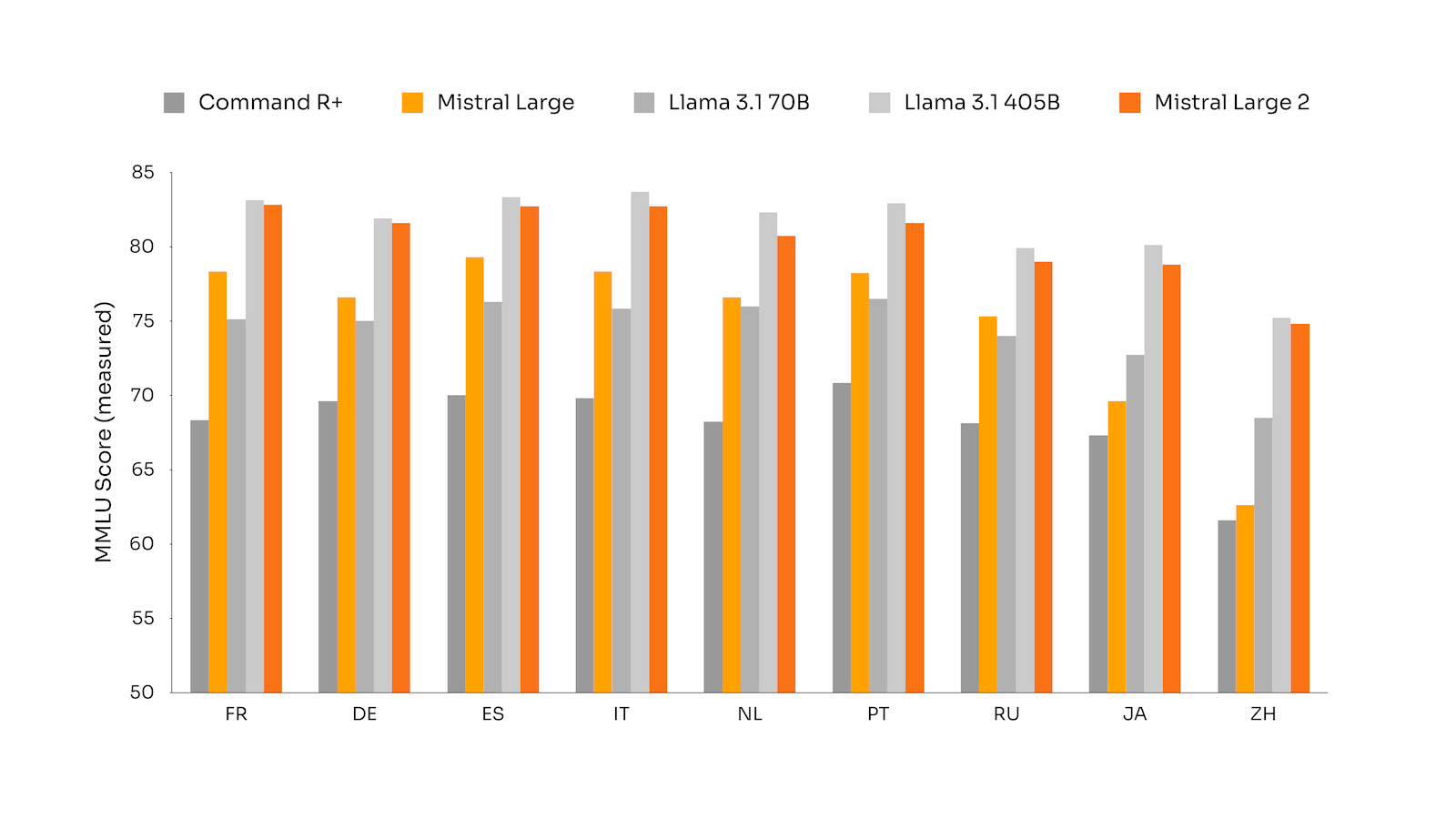
Arthur Mensch, CEO of Mistral AI, stated, "Mistral Large 2 sets a new frontier in terms of performance-to-cost ratio on evaluation metrics." He highlighted that the pretrained version achieves an 84.0% accuracy on MMLU, establishing a new point on the performance/cost Pareto front for open models.
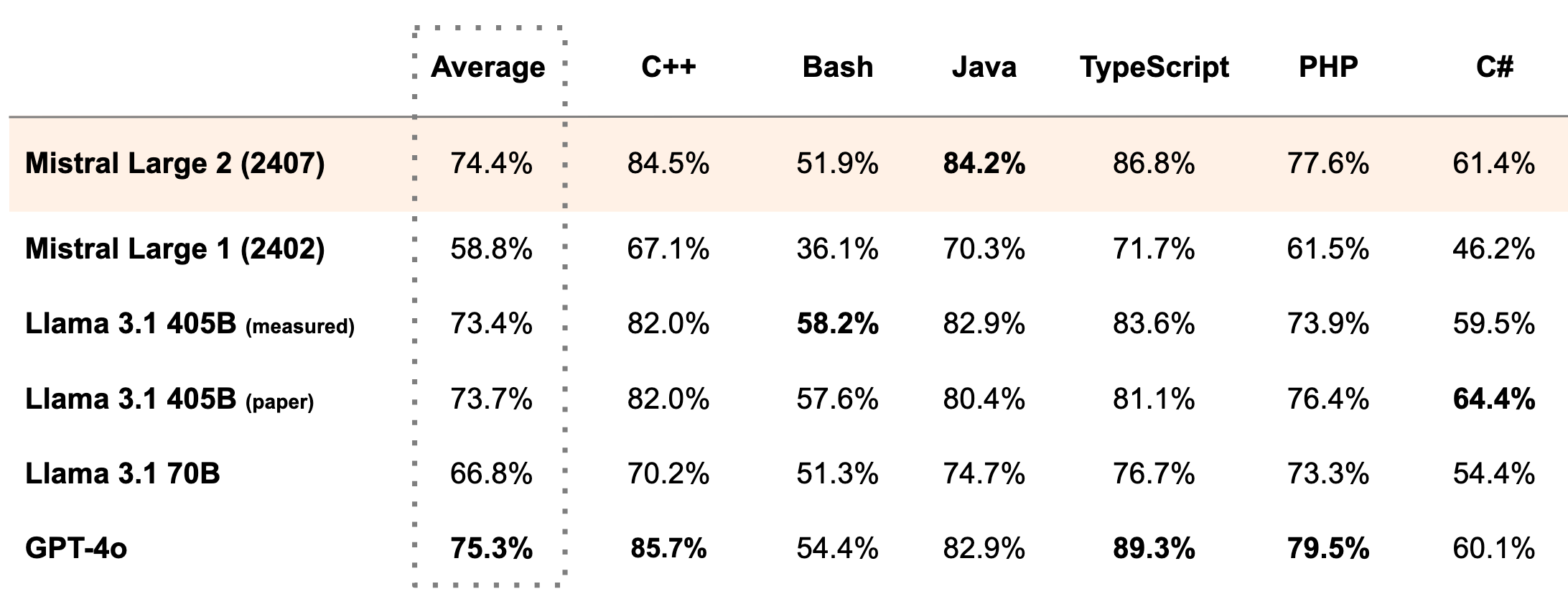
The model underwent extensive training on source code, building upon Mistral AI's experience with previous code-focused models. This emphasis has resulted in performance comparable to leading models like GPT-4, Claude 3 Opus, and Llama 3 405B in coding tasks.
Mistral AI also focused on enhancing the model's reasoning capabilities and reducing hallucinations. The company reports improved performance on mathematical benchmarks, reflecting these efforts.
Additionally, Mistral Large 2 has been trained to excel in instruction-following and conversational tasks, with particular improvements in handling precise instructions and long, multi-turn conversations.
The release of Mistral Large 2 on the heels of Llama 3.1 signals intensifying competition in the AI language model space. Its performance in specialized areas like code generation and mathematics, combined with strong multilingual support, positions it as a formidable option for both research and potential commercial applications.
As AI models continue to grow in size and capability, Mistral AI's focus on efficiency and single-node inference highlights an important trend in balancing performance with practical deployment considerations.