
On Friday, Mistral released Mixtral 8x7B, a high-quality sparse mixture of experts (SMoE) model with open weights by simply sharing a magnet link for the torrent. Mixtral 8x7B demonstrates strong performance across areas like language generation, code generation, and instruction following while keeping costs low.
magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%https://t.co/uV4WVdtpwZ%3A6969%2Fannounce&tr=http%3A%2F%https://t.co/g0m9cEUz0T%3A80%2Fannounce
— Mistral AI (@MistralAI) December 8, 2023
RELEASE a6bbd9affe0c2725c1b7410d66833e24
A mixture of experts architecture utilizes multiple specialized submodels, or "experts," to handle different aspects of a task. An input token is processed by a "router" network that selects only a few relevant experts, rather than utilizing all the weights.
The result is a model that combines the depth and breadth of a large-scale neural network with the speed and cost-effectiveness of a much smaller model, making it an exemplary instance of efficiency in AI modeling. So although Mixtral 8x7B has 56 billion total parameters, it only uses 12 billion per token thanks to its mixture of experts design. This allows efficient and fast inference comparable to a standard 12B model.
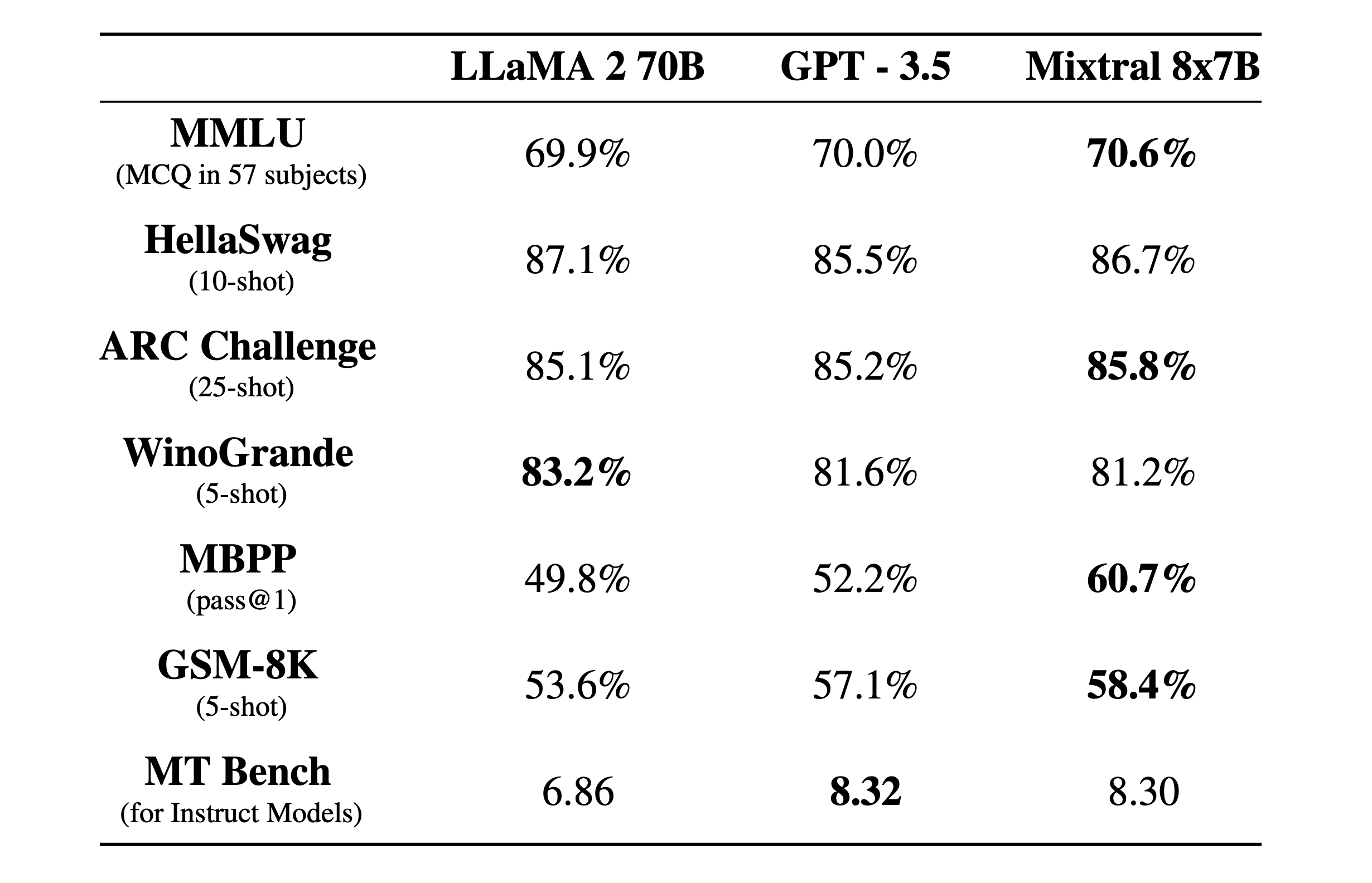
Mixtral 8x7B achieves state-of-the-art results among open models, matching or exceeding the performance of models like Llama 2 70B and GPT-3.5 Base in evaluations. Specific strengths include:
- Language generation over long contexts (32k tokens)
- Code generation
- Achieving top instruction following scores among open models (8.3 on MT-Bench)
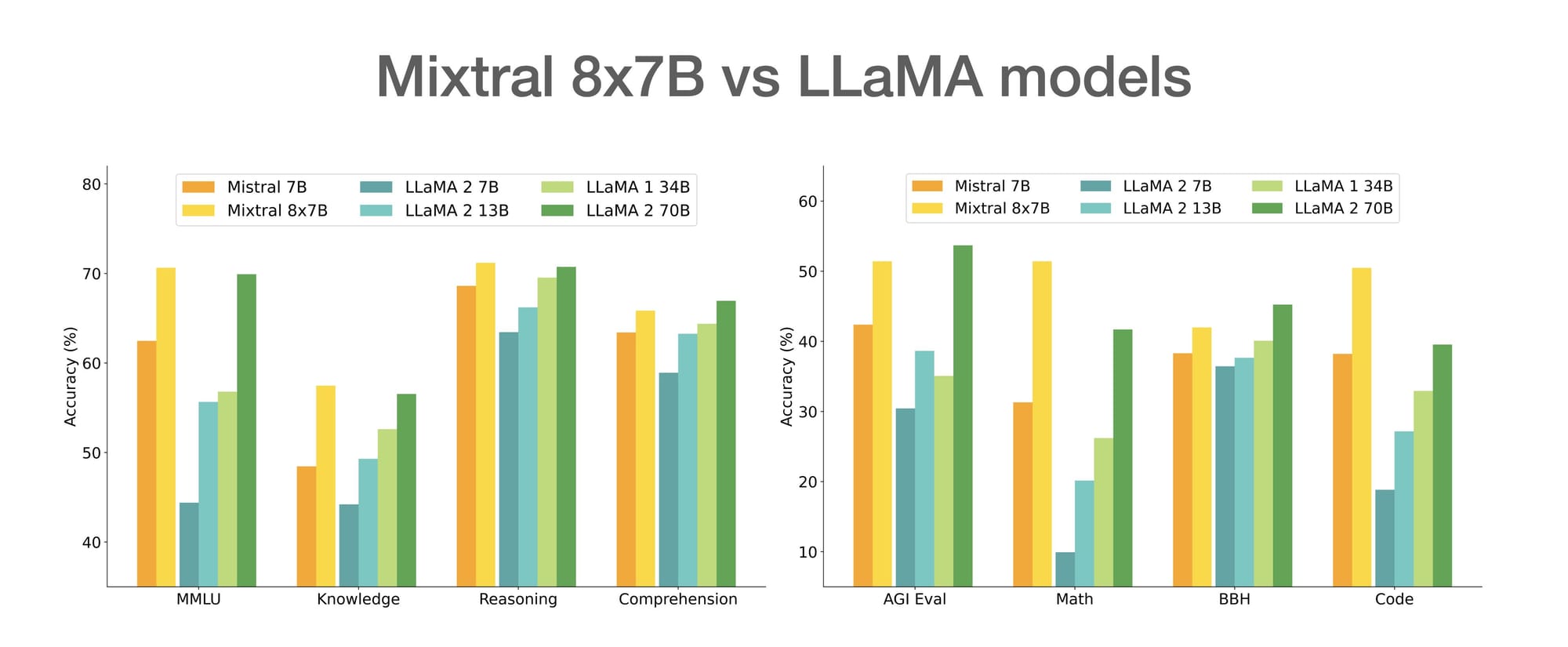
The Mistral team reports Mixtral displays higher truthfulness (74% on TruthfulQA) and less bias on benchmarks compared to other models like Llama 2. This gives it a strong foundation, although fine-tuning can further improve safety.
Complementing the Mixtral 8x7B is the Mixtral 8x7B Instruct, optimized through supervised fine-tuning and Direct Preference Optimization (DPO) for precise instruction following. This variant reaches an impressive score of 8.30 on MT-Bench, rivaling the GPT3.5 and affirming its position as the leading open-weights model in its class.
The model was trained on open web data and handles English plus French, Italian, German and Spanish. It is licensed under the permissive Apache 2.0 license.

By efficiently scaling up parameters while controlling costs, SMoEs represent a promising path to move beyond standard training paradigms. Mixtral highlights the potential for open models to match leading proprietary systems while promoting transparency. The release of Mixtral 8x7B furthers Mistral’s goal of empowering the community with open models that can drive new innovations in AI.