
NVIDIA just announced a GPU that's betting the future of AI needs way more memory than anyone thought possible. The Rubin CPX, unveiled Tuesday at the AI Infrastructure Summit, isn't just another faster chip—it's purpose-built to handle the massive million-token context windows that AI companies say they need to build truly useful coding assistants and video generators.
Key Points
- GPU tailored for tasks needing million-token context.
- Packed into the Vera Rubin NVL144 CPX platform: 8 exaFLOPS, 100 TB memory.
- Delivers 30 petaFLOPS (NVFP4), 128 GB GDDR7, 3× faster attention.
- Expected availability: late 2026. Monetization potential: $5 billion per $100 million.
Context windows are basically an AI model's working memory. Most current models max out around 128,000 to 200,000 tokens—enough for a decent-sized document, but nowhere near what you'd need to understand an entire software project or generate coherent long-form video. Google's Gemini 2.5 pushes that to 1 million tokens, while Magic's LTM-2-mini handles 100 million tokens—roughly 10 million lines of code or 750 novels. But here's the catch: feeding all that context to current hardware is expensive and painfully slow.
That's where NVIDIA's new chip comes in. The Rubin CPX is laser-focused on what NVIDIA calls the "context phase" of inference—the compute-heavy part where the model ingests and processes all that input data before generating its first token. It's a fundamentally different approach from throwing more general-purpose GPUs at the problem.

The specs are genuinely wild. The Vera Rubin NVL144 CPX platform, which packs 144 Rubin CPX GPUs alongside 144 regular Rubin GPUs and 36 Vera CPUs, delivers 8 exaflops of compute power—7.5 times more AI performance than NVIDIA's current GB300 NVL72 systems. You also get 100 terabytes of fast memory with 1.7 petabytes per second of memory bandwidth, all crammed into a single rack.
"Just as RTX revolutionized graphics and physical AI, Rubin CPX is the first CUDA GPU purpose-built for massive-context AI," Jensen Huang said in the announcement. It's classic Huang—bold claims backed by genuinely impressive silicon.
Companies like Cursor (boosting code generation), Runway (generative video), and Magic (100-million-token context models) are lining up to harness Rubin CPX’s power.
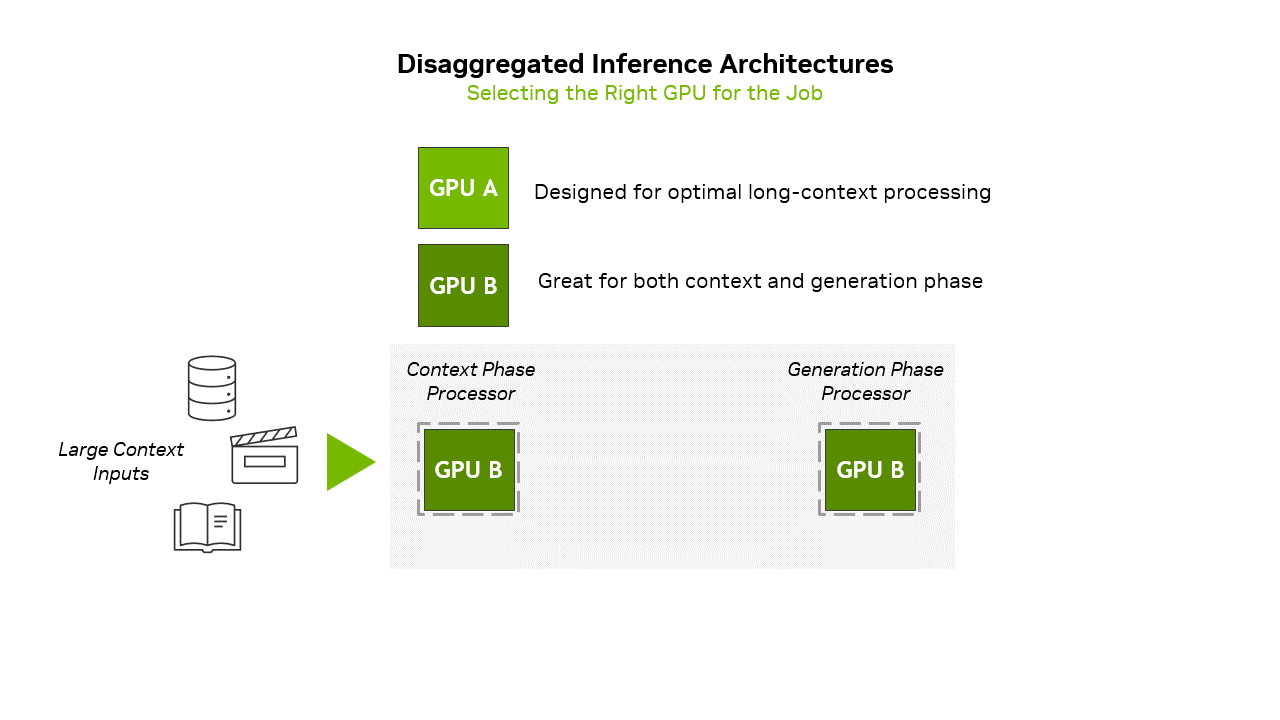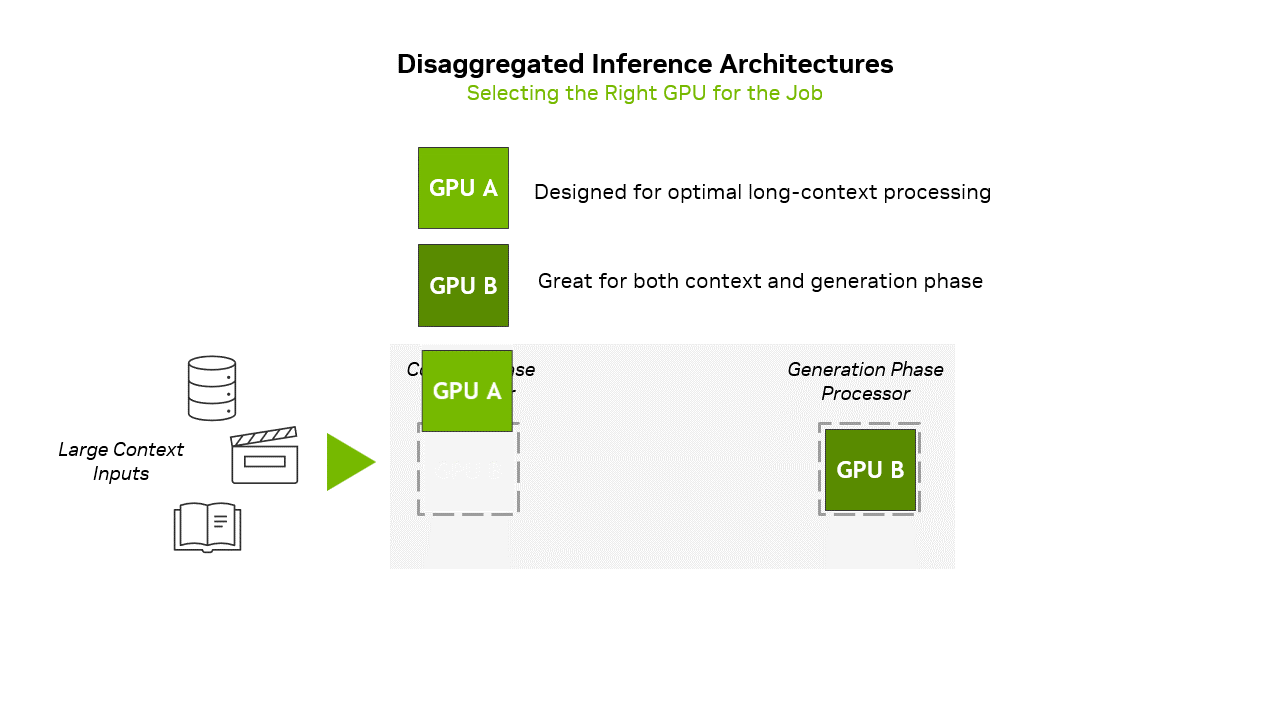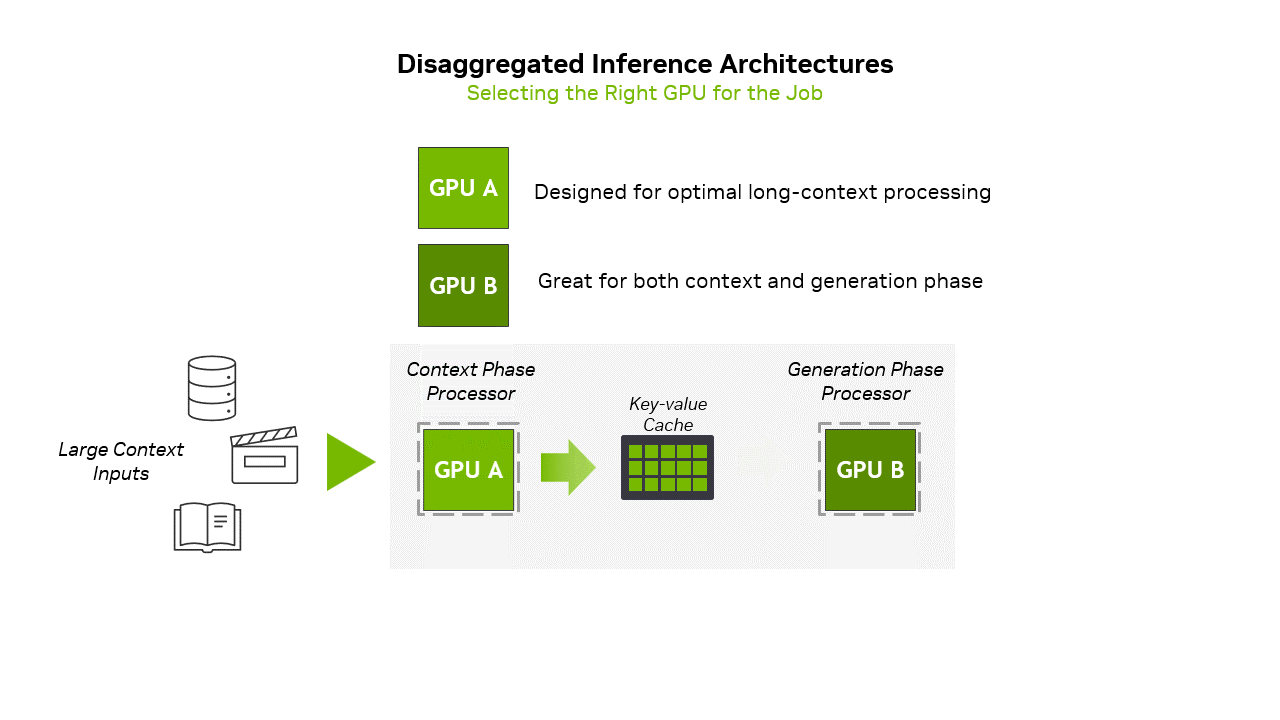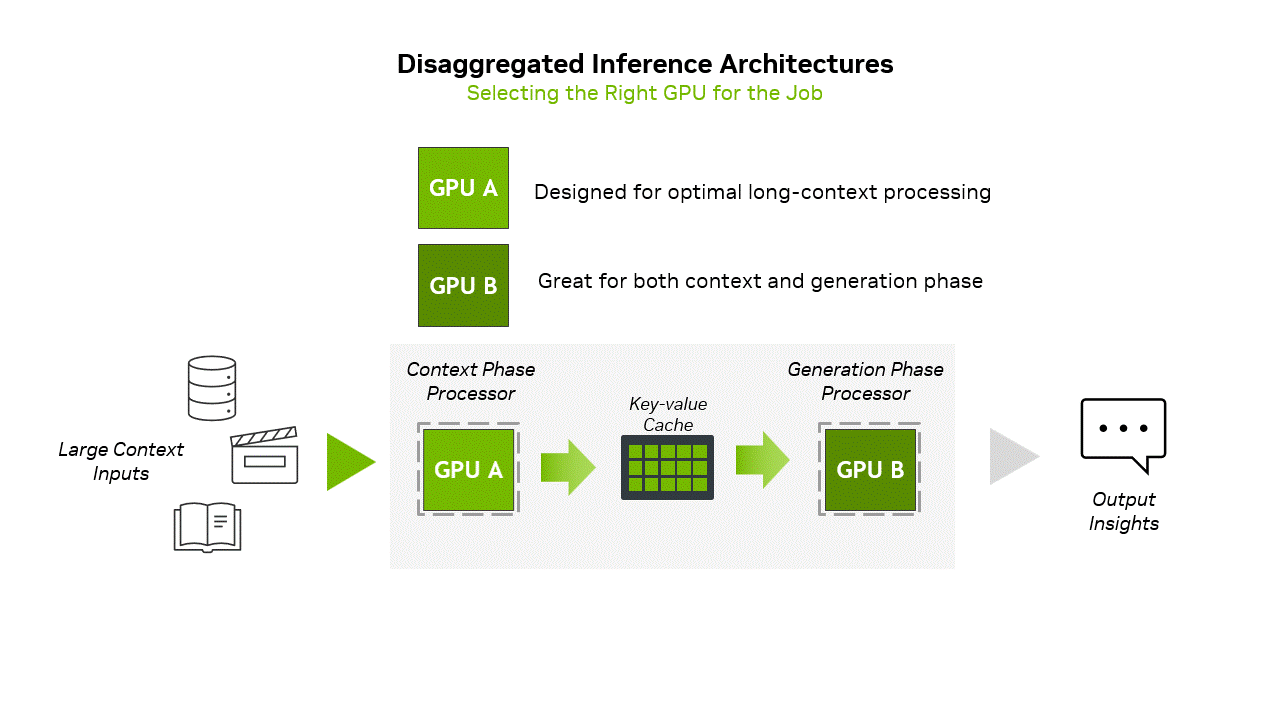
There's a deeper architectural shift happening here. NVIDIA's pushing what they call "disaggregated inference"—splitting the context phase and generation phase of AI inference across different specialized hardware. The Rubin CPX handles the heavy compute of ingesting context, while other chips handle the memory-bandwidth-intensive task of generating tokens one by one. It's more complex to orchestrate, but potentially much more efficient than using the same hardware for everything.
The Rubin CPX represents an interesting evolution in AI hardware: chips designed not just to be faster or more efficient, but architected around how AI models actually work. As models get more sophisticated and context windows keep growing, expect to see more of this kind of specialization.