OpenAI's "strawberry" AI model is finally here. The company says it is such a significant advancement to the state-of-the-art in AI reasoning, that it is resetting its version counter, and starting a brand new family of models separate from the GPT series. Today, the company unveiled OpenAI o1-preview and o1-mini, from their new o1 series of reasoning models for solving hard problems.
These models are trained to "to spend more time thinking through problems" before they respond—just like a human. They use a technique called chain-of-thought, which enables the AI to break down problems, consider multiple approaches, and even correct its own mistakes. OpenAI says they can reason through complex tasks and solve harder problems than previous models in science, coding, and math.
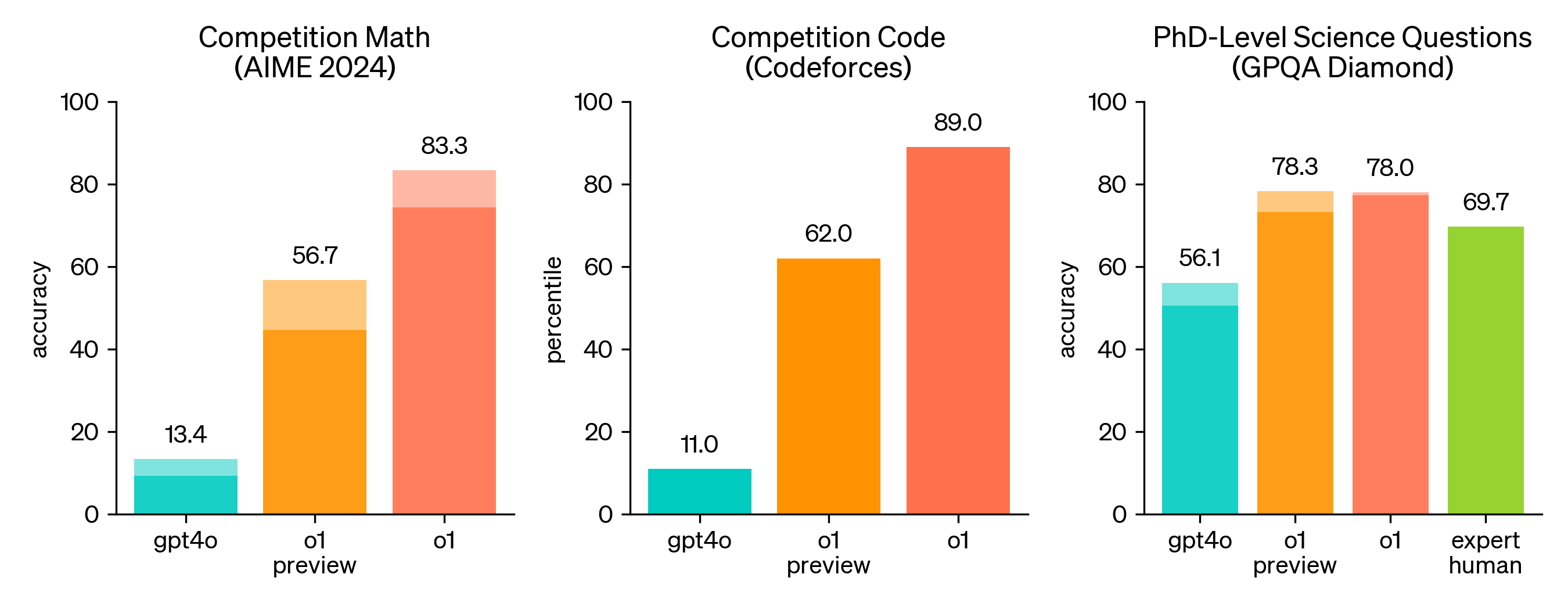
Just look at the benchmarks—the performance of o1 has been nothing short of remarkable. In mathematics, o1 demonstrated exceptional prowess, scoring high enough on the American Invitational Mathematics Examination (AIME) to place among the top 500 students in the United States. Perhaps most impressively, o1 is the first model to exceeded human PhD-level accuracy on the GPQA benchmark, which tests knowledge in physics, biology, and chemistry.
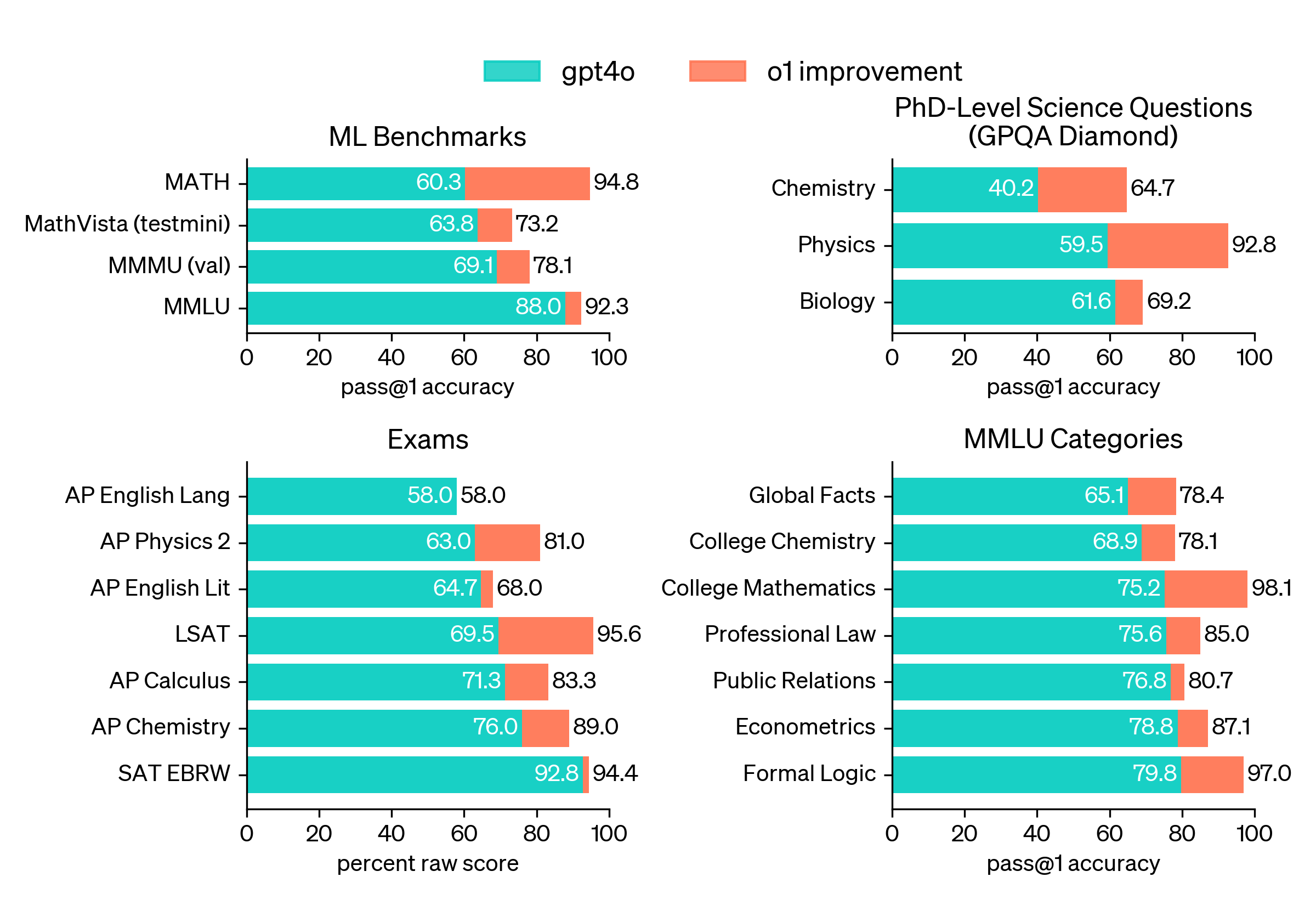
It also outperforms previous models in 54 out of 57 MMLU subcategories, indicating a broad and deep understanding of various fields of knowledge. And, it ranked in the 89th percentile on competitive programming questions on Codeforces, placing it among the top echelons of coders worldwide.
But OpenAI didn't stop there, it used a specialized version of the model, fine-tuned for programming, to compete in the 2024 International Olympiad in Informatics (IOI) under the same conditions as human contestants. It scored 213 points, ranking in the 49th percentile globally. The model's performance improved dramatically when submission constraints were relaxed, achieving a score of 362.14 points—above the gold medal threshold.
Additionally, in a simulated Codeforces contests, it achieved an impressive Elo rating of 1807, outperforming 93% of human competitors and far surpassing GPT-4o's rating of 808. As I said, remarkable.
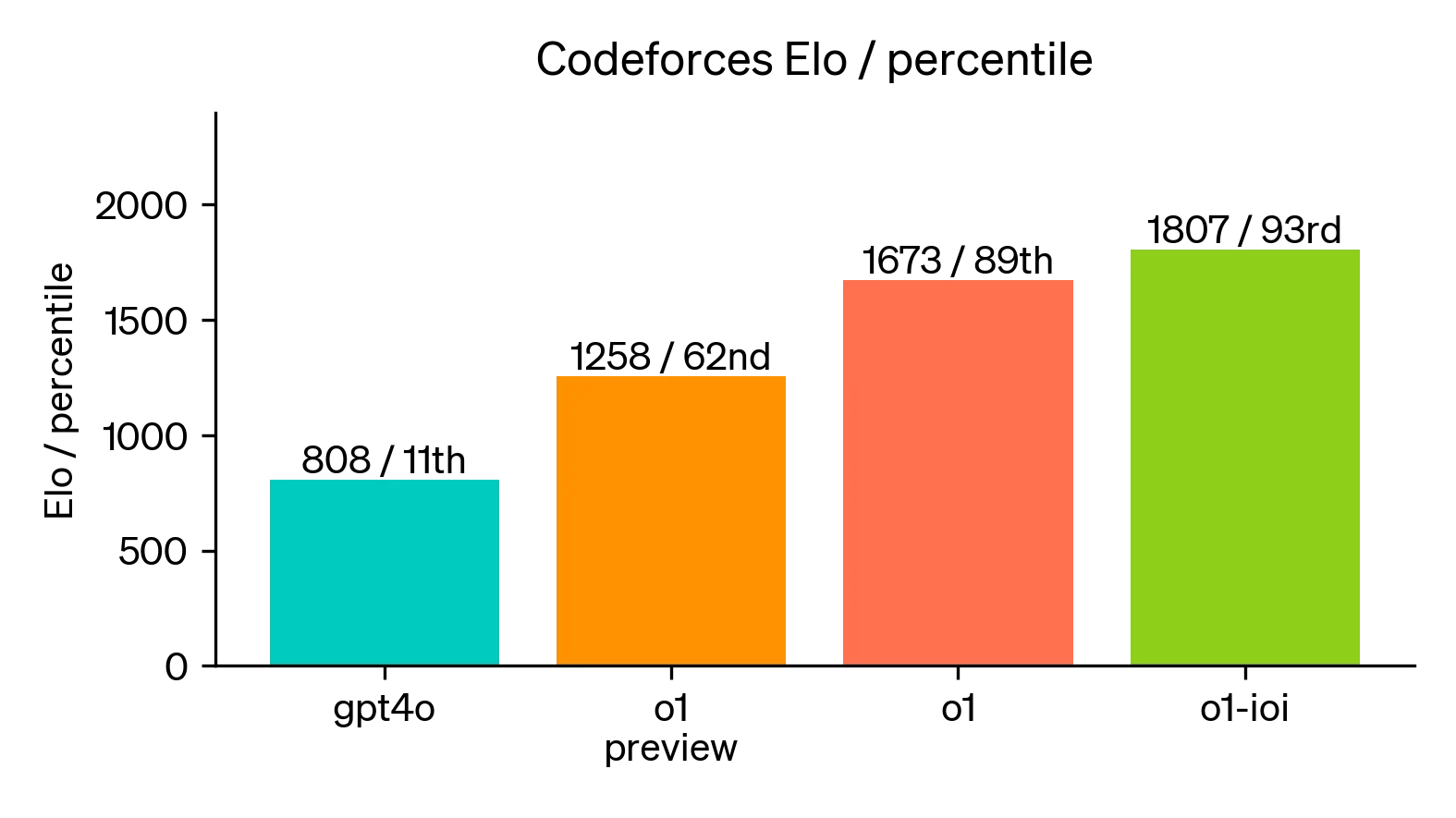
One of the most exciting aspects of o1 is its scalability. OpenAI researchers have found that the model’s capabilities improve consistently with increased reinforcement learning (train-time compute) and more time spent processing (test-time compute). This suggests significant potential for future enhancements as computational resources expand.
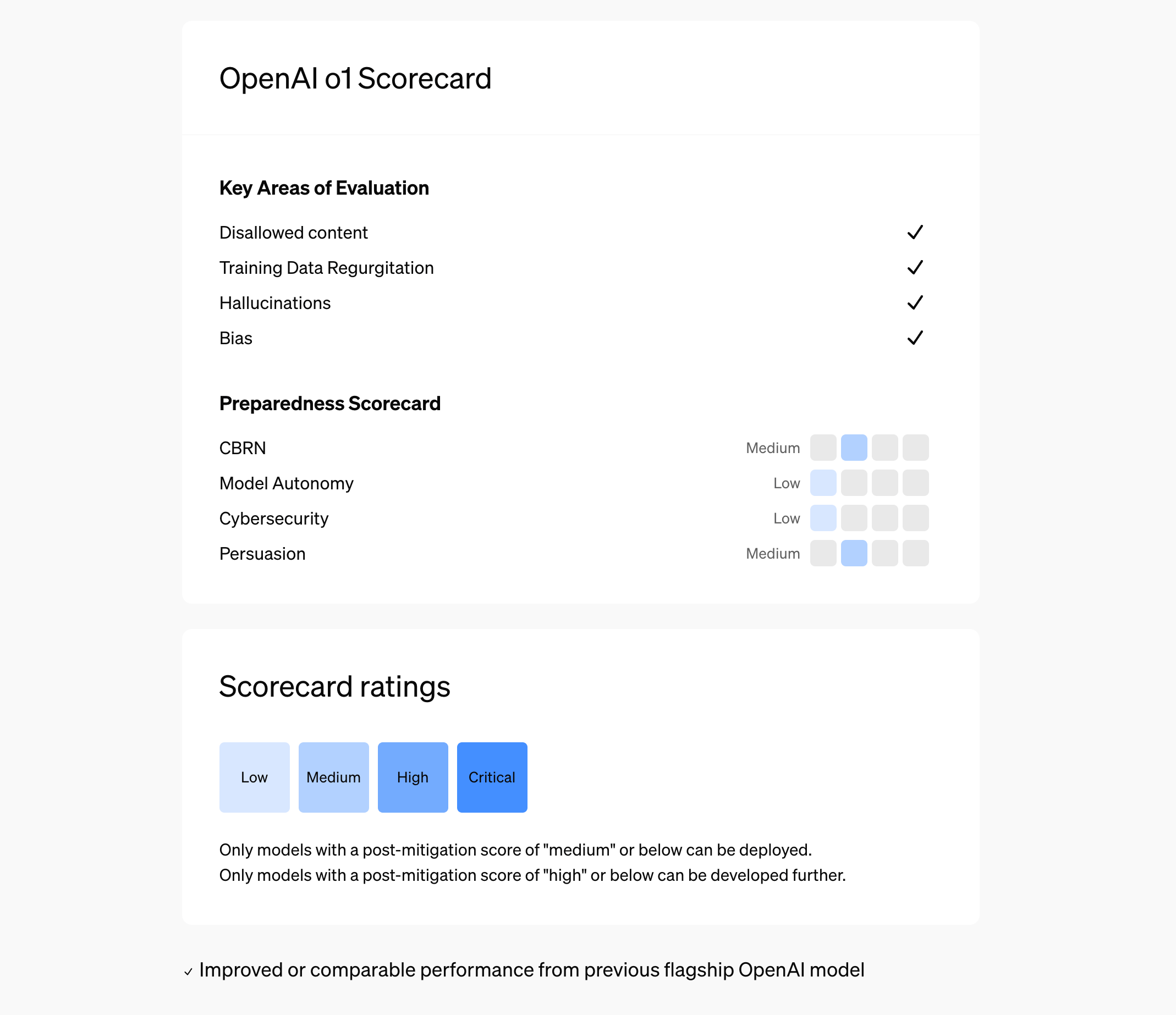
We must also highlight that the company says it has made significant strides in aligning the o1 model with human safety and ethical guidelines. The company shared a detailed Sytem Card and a Preparedness Framework scorecard outlining rigorous safety assessments, and extensive red-teaming that was conducted to address frontier risks. Despite these advancements, OpenAI acknowledges the potential risks associated with more intelligent AI models and remains committed to monitoring and refining o1’s capabilities.
The enhanced reasoning capabilities also contribute to improved safety. By reasoning about safety policies within its chain of thought, o1 more effectively applies guidelines to avoid generating harmful or inappropriate content. This approach has led to o1 achieving state-of-the-art performance on internal safety benchmarks and showing increased resistance to jailbreak attempts and adversarial prompts.
Currently, both o1-preview and o1-mini are available to ChatGPT Plus and Team users, as well as to developers who qualify for API usage tier 5. OpenAI says it ultimately plans to expand access to o1-mini to all ChatGPT Free users.