
Scale AI has introduced SEAL (Scale Expert AI Leaderboards), a set of private benchmarks that they plan to use to provide unbiased expert evaluations of leading frontier AI models. These benchmarks are designed to be unexploitable, with evaluations performed by domain experts using continuously updated datasets.
The SEAL initiative addresses a critical gap in the AI ecosystem - the lack of trusted third-party evaluations. While community efforts like those from LMSYS are valuable, Scale believes there is still significant room for improvement in how models are assessed by external parties.
Many current AI benchmarks suffer from significant limitations, as highlighted in a paper published earlier this month by Scale AI researchers. The problem with a lot of these benchmarks is that they are publicly available and as such, can be gamed—either intentionally by companies trying to achieve higher scores, or unintentionally through the inclusion of benchmark data in the models' training sets. This leads to inflated performance metrics that don't reflect real-world capabilities.
In their paper, Scale AI researchers investigated the issue of model overfitting on the popular GSM8k benchmark for mathematical reasoning. They introduced a new benchmark, GSM1k, designed to mirror the style and complexity of GSM8k while ensuring no overlap with the original dataset.
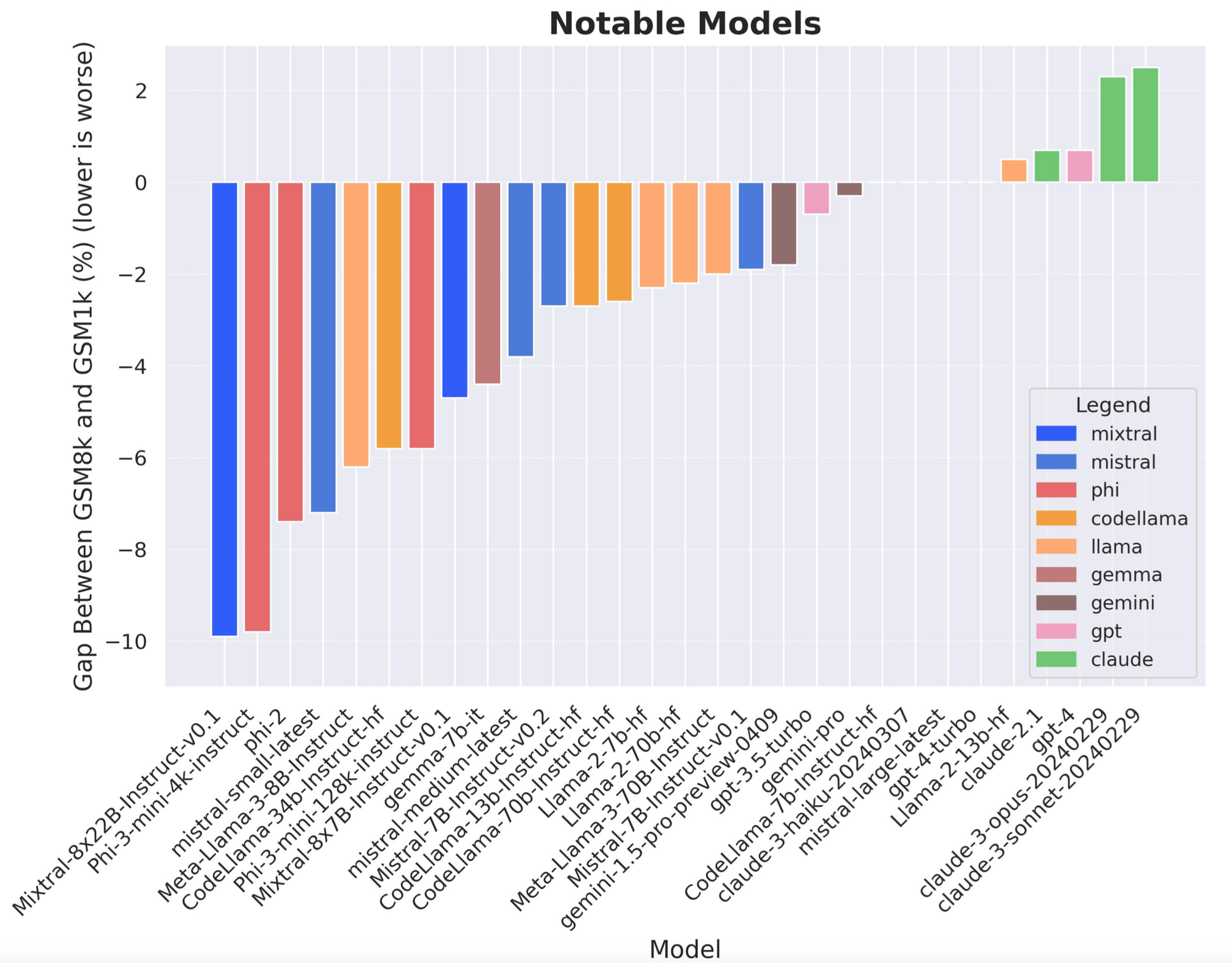
When tested, several leading models, including Mistral and Phi, showed significant drops in accuracy—up to 13%—on GSM1k compared to GSM8k, indicating overfitting. In contrast, models like GPT, Claude, Gemini, and Llama did not exhibit the same level of overfitting, suggesting they have better generalization capabilities. Further analysis revealed a positive relationship between a model's likelihood of generating GSM8k examples and its performance gap between GSM8k and GSM1k, indicating that some models may have partially memorized the GSM8k test set.
Drawing from their research findings, a key design principle of SEAL is producing evaluations that are impossible to overfit to. The initial SEAL leaderboards evaluated several prominent models, including GPT-4o, GPT-4 Turbo, Claude 3 Opus, Gemini 1.5 Pro, Gemini 1.5 Flash, Llama3, and Mistral Large. The models were tested on their performance in coding, math, instruction following, and multilingual abilities (specifically Spanish).
The evaluations themselves are performed using domain-specific methodologies by thoroughly vetted experts, ensuring the highest levels of quality and credibility in the results.
To keep the leaderboards dynamic and prevent models from saturating the evaluation sets, Scale plans to periodically update them with fresh data and the inclusion of new models as they become available.
Leaderboard
Based on their evaluations, OpenAI's GPT-4 Turbo and GPT-4o are the most capable models. See the full leaderboard here.
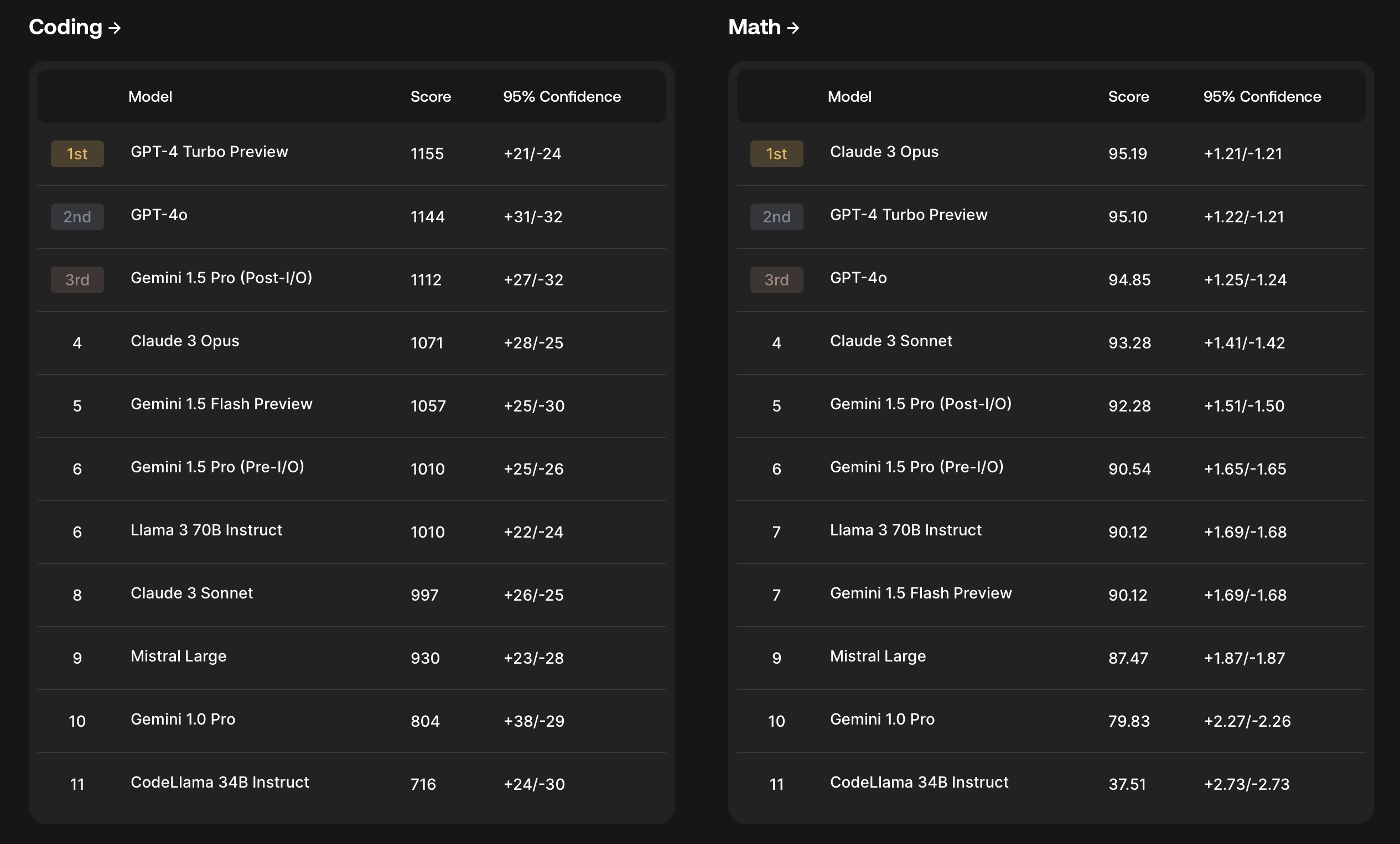
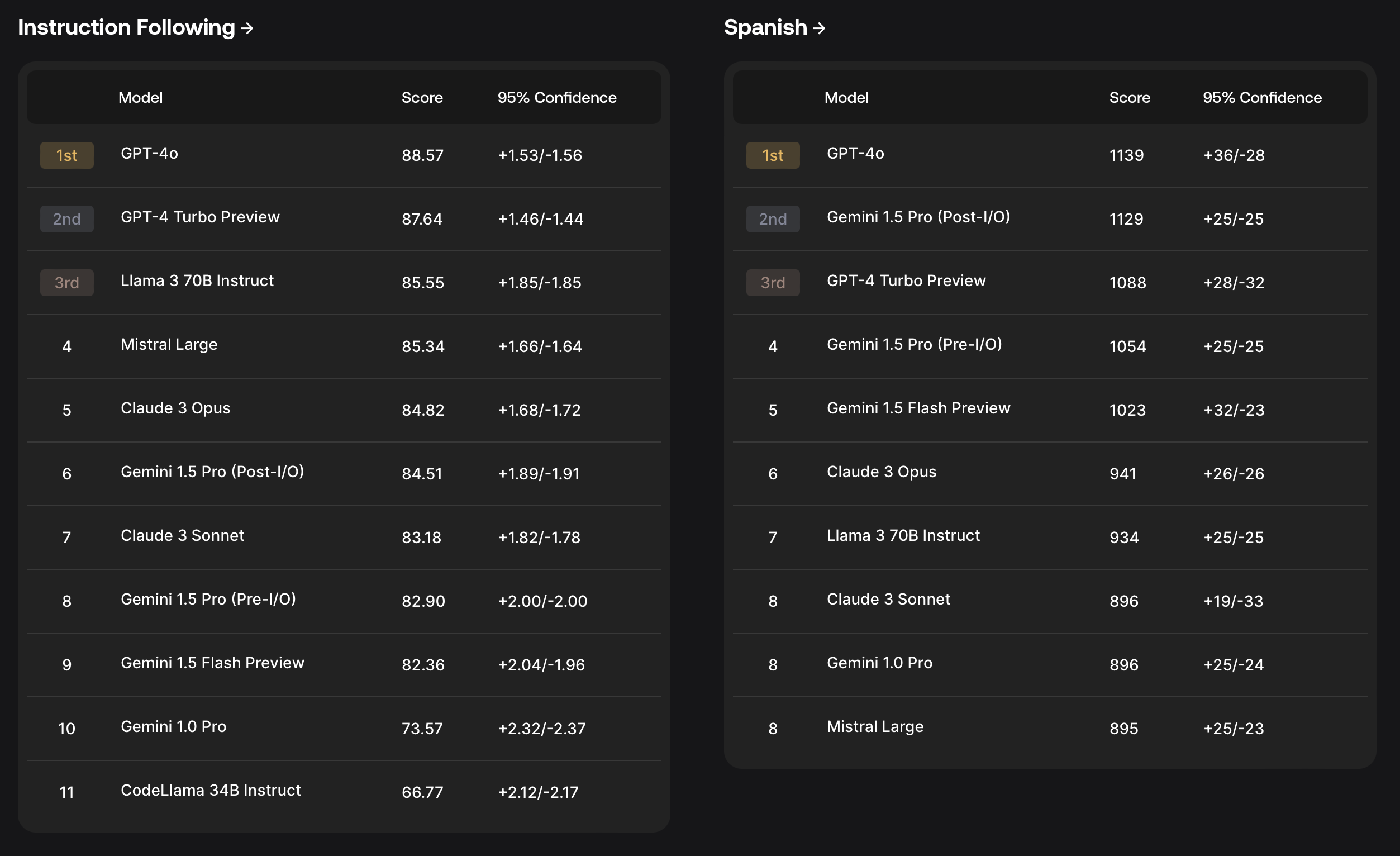
By launching SEAL, Scale hopes to provide the AI community with a valuable benchmark for objectively comparing frontier models and identifying areas for further advancement, ultimately contributing to the responsible development of increasingly capable AI systems.