
Stability AI has announced the release of its first Japanese vision-language model, Japanese InstructBLIP Alpha. This new model is designed to generate Japanese text descriptions for input images, as well as provide textual answers to questions about images.
The model builds upon the foundation laid by the recently released Japanese StableLM Instruct Alpha 7B, a large language model optimized for the Japanese language. Merging this with the high-performance InstructBLIP architecture, the company has created a potent combination aimed at generating text conditionally based on images.
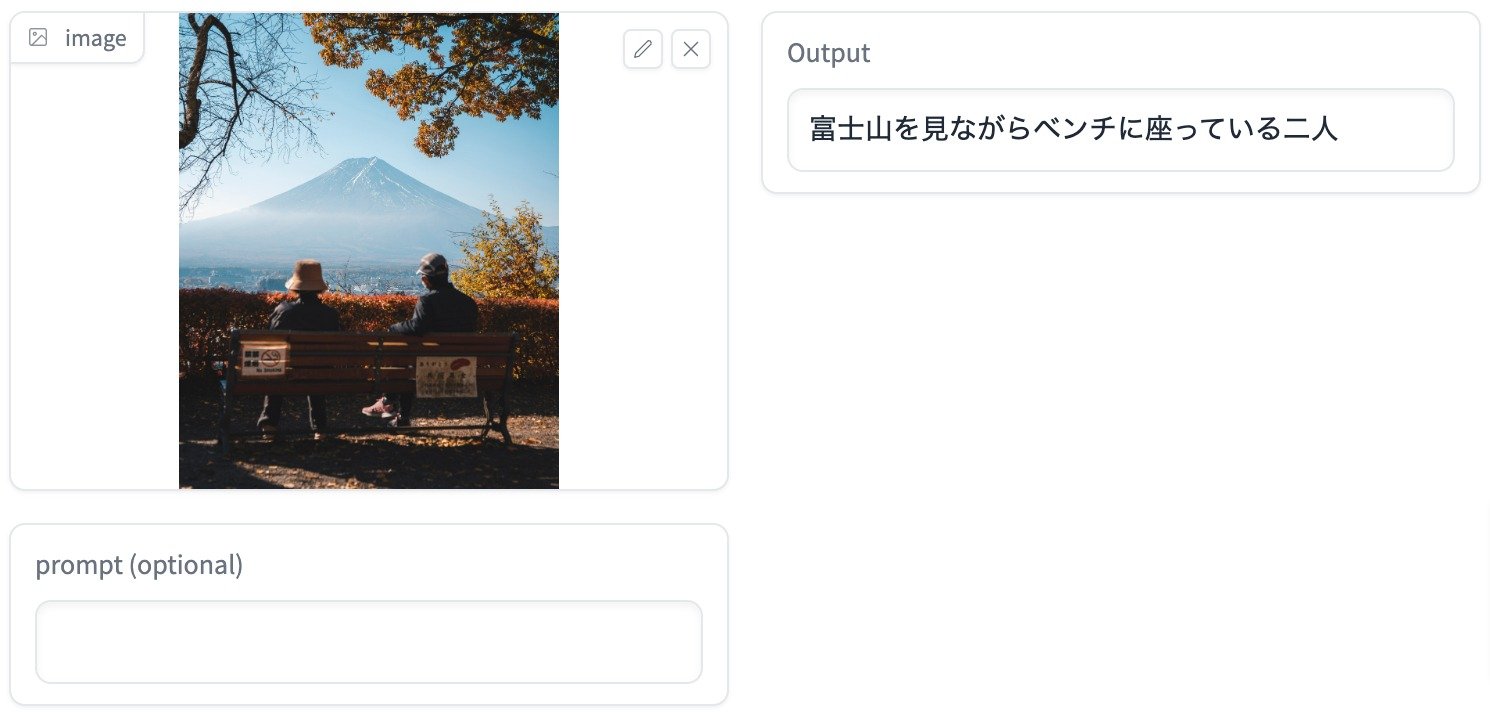
In terms of performance, the model is engineered to recognize specific Japanese landmarks, like the Tokyo Skytree or Kinkaku-ji. This nuanced capability adds a layer of localized understanding that is indispensable for applications ranging from tourism to robotics. Moreover, the model can process both images and text, thus enabling more complex queries based on visual inputs. For example, users can ask questions about depicted scenes, and the model will generate accurate answers.
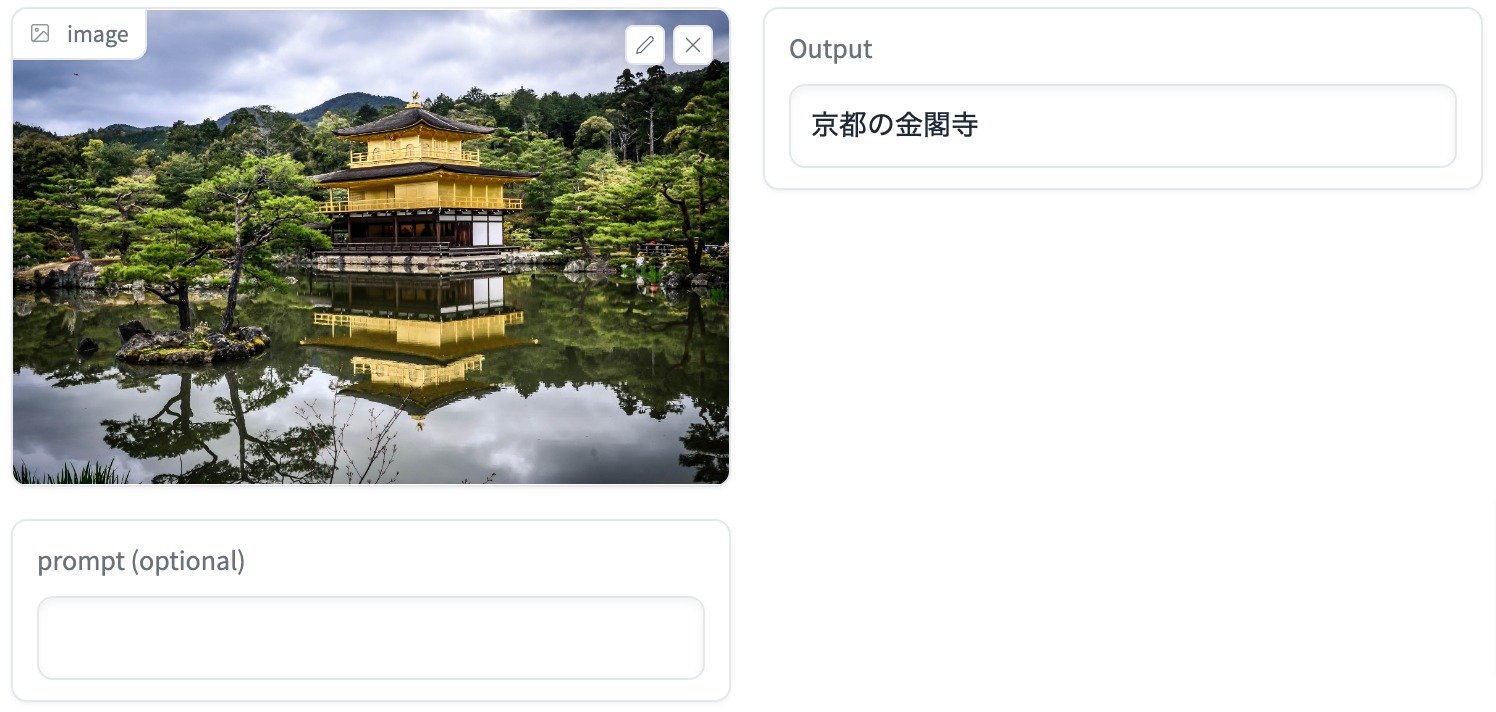
Stability AI highlights potential applications including Japanese image search, automated alt-text generation, visual question answering, and scene description for blind users. The model is available on Hugging Face Hub under a research license, enabling further testing and development by the AI community.
While the release marks an important milestone for AI research and applications in Japanese, Stability AI cautions users to be mindful of potential biases and limitations at this stage. As with any AI system, human judgment is required to evaluate responses for accuracy and appropriateness. Continued research and development will be key to improving the model's capabilities in Japanese vision-language tasks.