Windsurf is launching its own family of purpose-built large language models. The company announced today that its new "SWE-1" models are designed specifically for software engineering tasks — not just coding — and claims its tailor-made approach gives it unique advantages over general-purpose models from OpenAI and Anthropic.
Key Points:
- The SWE-1 models are specifically designed for software engineering, not just coding
- The company claims performance near frontier models but with better integration with its tools
- Windsurf will still offer other AI models alongside its own
Windsurf, known for its slick agentic IDE, is now training and serving its own models—starting with a family of purpose-built systems called SWE-1. Unlike other AI coding models that autocomplete functions or spit out React components on command, SWE-1 is built to understand the entire flow of software engineering: navigating incomplete tasks, bouncing between terminal and browser, and reasoning over time.
That’s not marketing spin. According to Windsurf co-founder Anshul Ramachandran, the SWE-1 initiative was born from a simple realization: “Even as frontier models get better, we see that ceiling,” he told Maginative in an exclusive interview. “Writing code is just a fraction of what engineers do. A ‘coding-capable’ model won’t cut it.”
So they built their own. SWE-1 (alongside its smaller siblings SWE-1-lite and SWE-1-mini) is the product of a tightly focused in-house team and custom infrastructure. All three models are already live inside Windsurf’s dev surfaces—free for now. SWE-1-lite is replacing Cascade Base, and SWE-1-mini powers the predictive Windsurf Tab.
The strategy is clear: own every layer. Where most AI-native tools stitch together wrappers on top of foundation models, Windsurf is going full-stack—controlling everything from inference latency to interface nudges. “Now that we also own the models and we can deploy them ourselves,” Ramachandran said, “we can apply all of our infrastructure tricks… and pass those cost savings to users.”
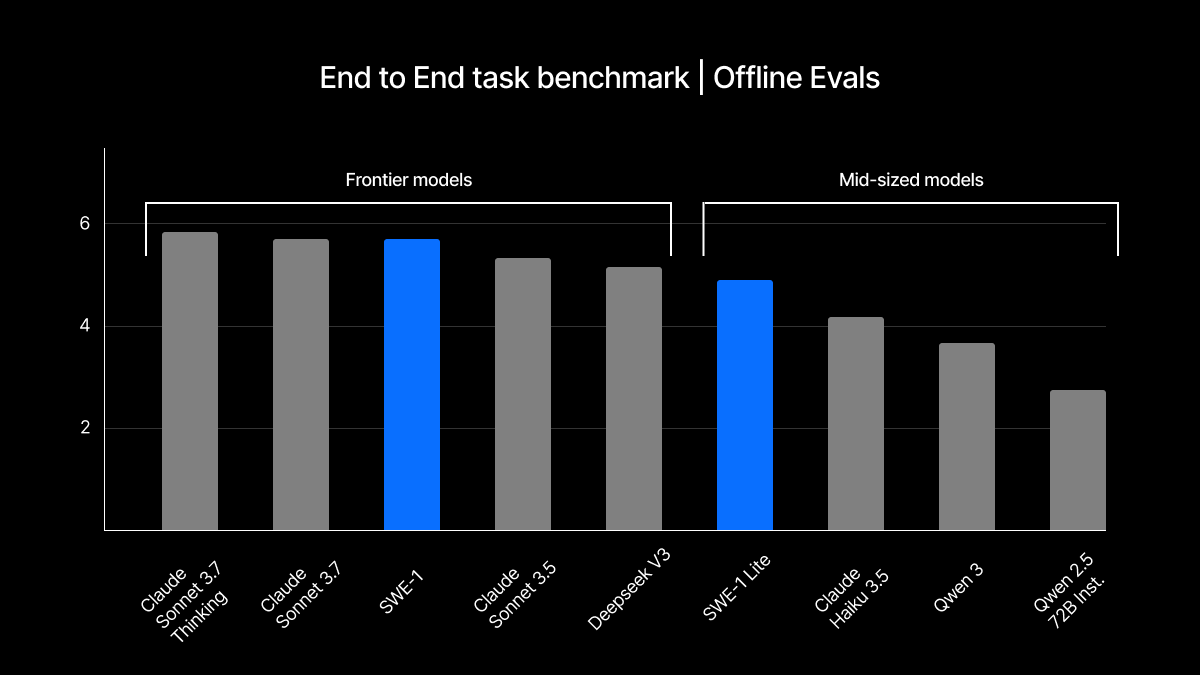
Performance-wise, SWE-1 holds its own. Internal benchmarks pit it close to Claude 3.5 Sonnet in key human-in-the-loop tasks, and ahead of most open-weight contenders. But where it really shines is in production use. Windsurf quietly ran blind A/B tests by swapping SWE-1 into real user sessions with their current Cascade Base at zero credits—tracking outcomes of lines written, user acceptance, and contribution rate. The result? Higher engagement, better retention, and more trusted outputs. Ramachandran admitted it’s “slightly overfit” to Windsurf’s environment—but that’s the point.
What appears to give Windsurf confidence in its approach is the feedback it's collected through its editor products. The company claims it has built a "shared timeline" that captures the interplay between human developers and AI assistance, giving it unique insights into how software engineering actually works in practice. This "flow awareness" — understanding how developers move between editing, terminal commands, and other contexts — has shaped both the company's products and its new models.
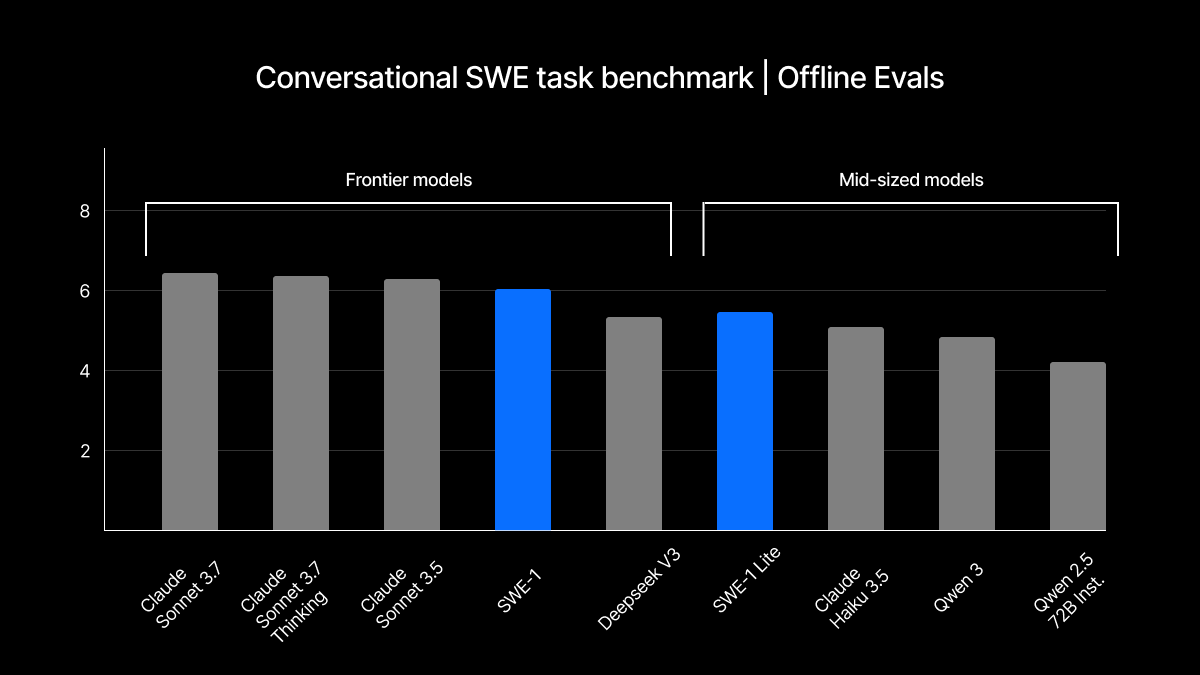
Benchmark results shared by Windsurf suggest that SWE-1 is competitive with frontier models from major AI labs like Anthropic, particularly in scenarios that match Windsurf's product use cases. The company tested both "conversational" tasks, where the model needs to assist in the middle of a partially-completed process, and end-to-end tasks where it builds complete solutions.
The company isn't claiming to have created the most powerful AI models on the market — SWE-1 apparently doesn't quite match Claude 3.5 Sonnet's performance in all metrics — but Windsurf believes its specialized focus gives it advantages for its specific use case. The models' performance particularly shines in real-world usage data, where Windsurf said blind tests showed users accepting and retaining more code contributions from SWE-1 than from other models.
Despite developing its own models, Windsurf isn't fully cutting ties with other providers. "Even with SWE-1, we're still, in many ways, a model-agnostic company," Ramachandran said. "If there are certain tasks where our models aren't the absolute frontier, we will still offer all the other models that everyone else has."
SWE-1 is just another tool in the kit—just one they can iterate on faster, tailor more precisely, and scale cheaper. For enterprise clients like JPMorgan and Dell, that means lower cost per token. For devs? It means the agent writing your code actually remembers what you did five minutes ago.
The question remains whether specialized, task-specific models from application companies can truly compete with the massive research budgets and computational resources of foundation model providers. Windsurf seems to believe its focused approach and unique data assets give it a fighting chance — at least in its own domain.