
Amazon Web Services (AWS) recently announced a major upgrade to its voice transcription service Amazon Transcribe, powered by a next-generation speech foundation model. The update significantly expands Transcribe's speech recognition capabilities to over 100 languages while delivering substantial improvements in accuracy and incorporating a range of AI-driven capabilities.
At the core of the update is a multi-billion parameter generative AI model trained on millions of hours of speech data across languages. The algorithms powering this model allow it to learn universal speech patterns and better recognize diverse accents and noisy environments.
As a result, Transcribe now promises 20-50% increases in accuracy for most languages and even bigger jumps of 30-70% for telephony speech, a notoriously challenging and data-scarce domain. The boost in languages supported and speech recognition quality unlocks new use cases across sectors.
Emergency call platform Carbyne plans to utilize Transcribe's expansive multilingual capabilities to expand access to 911 and emergency response. Carbyne CTO Alex Dizengof explained how it will enable their translation feature to serve non-English speakers better, supporting their mission where "every person counts."
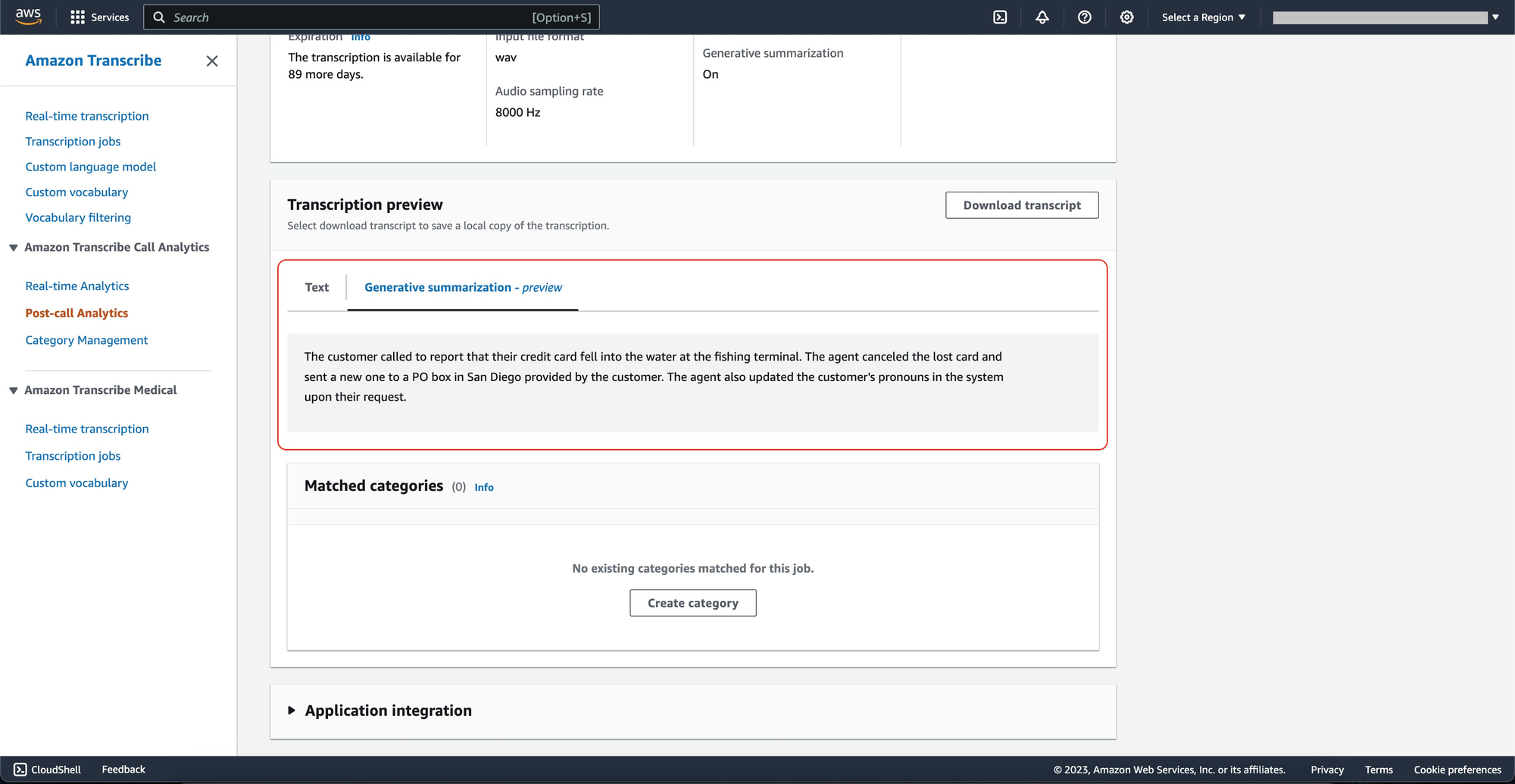
One of the standout features is the generative call summarization in Amazon Transcribe Call Analytics. This feature condenses entire interactions into concise summaries, thereby significantly reducing the after-call workload for agents and allowing managers to quickly grasp the context of interactions.
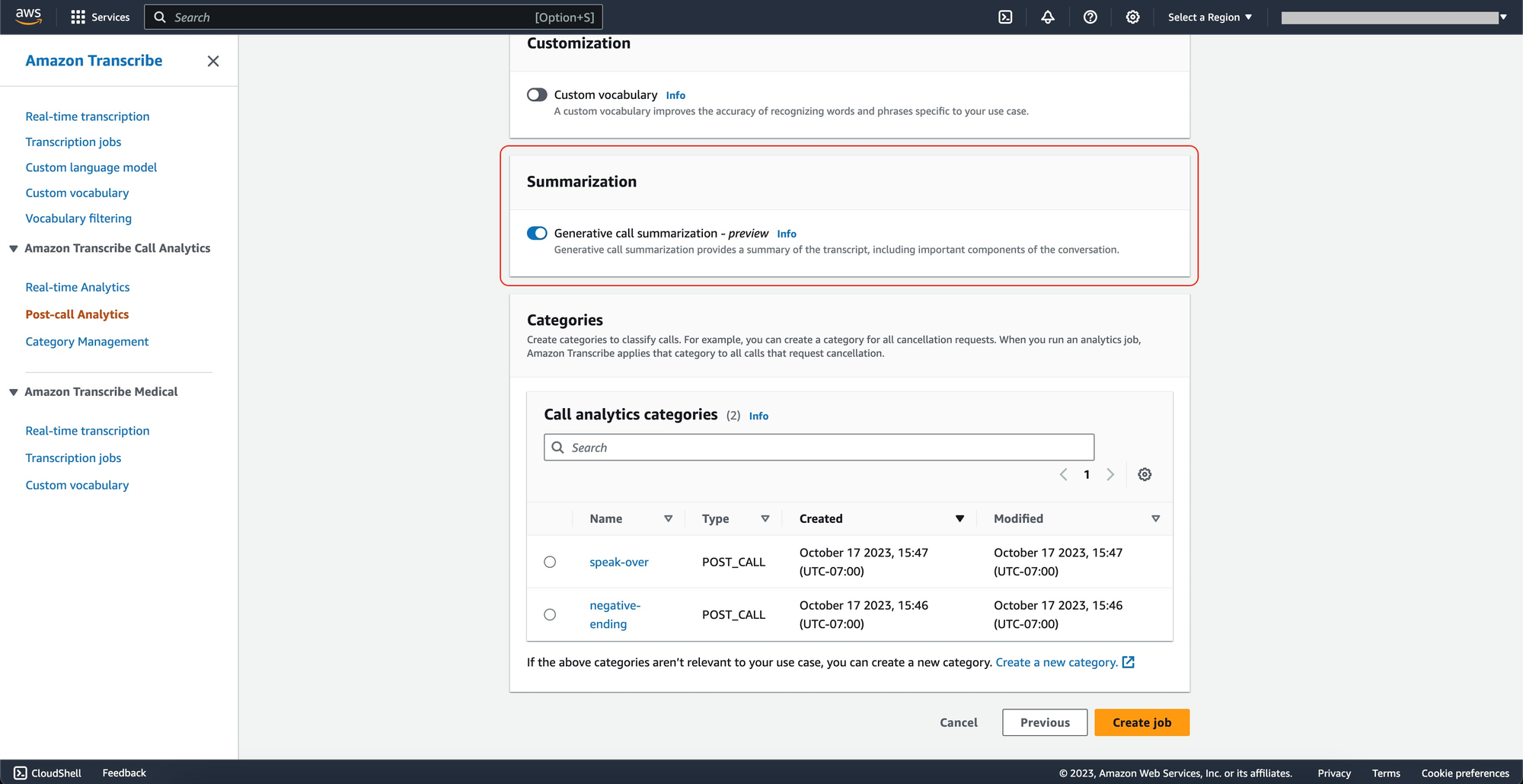
The new automatic speech recognition is designed with ease of use, customization, user safety, and privacy in mind. It includes features like automatic punctuation, custom vocabulary, automatic language identification, speaker diarization, word-level confidence scores, and custom vocabulary filters.
Other applications include automated subtitling by media and content companies, mining insights from customer call transcripts in contact centers, and more. Essentially any organization handling lots of spoken audio can benefit.
Importantly, the upgrades automatically apply to any Amazon Transcribe customers without needing migration. The API endpoint, input parameters and backend processes remain the same.
Additional new capabilities provide customizable features that address user safety, privacy and accessibility needs - like automatic language identification, custom vocabulary filters and speaker labeling.