
Meta has just unveiled Llama 3, the next generation of their state-of-the-art open-source large language model. Today, the company is releasing pretrained and instruction-fine-tuned models with 8B and 70B parameters. Llama 3 remains an open-weights AI model, meaning anyone can access and use it (within certain limits 1, 2).
Llama 3 boasts state-of-the-art performance across a wide range of industry benchmarks. The models were trained on a massive dataset of 15 trillion tokens, 7x more than for Llama 2, and include 4x more code. This has resulted in notable improvements in language nuances, contextual understanding, and complex tasks like translation and dialogue generation. Meta has also refined its post-training processes, leading to lower false refusal rates, better-aligned responses, and enhanced diversity in model answers. Additionally, Llama 3 excels in reasoning, code generation, and instruction following.
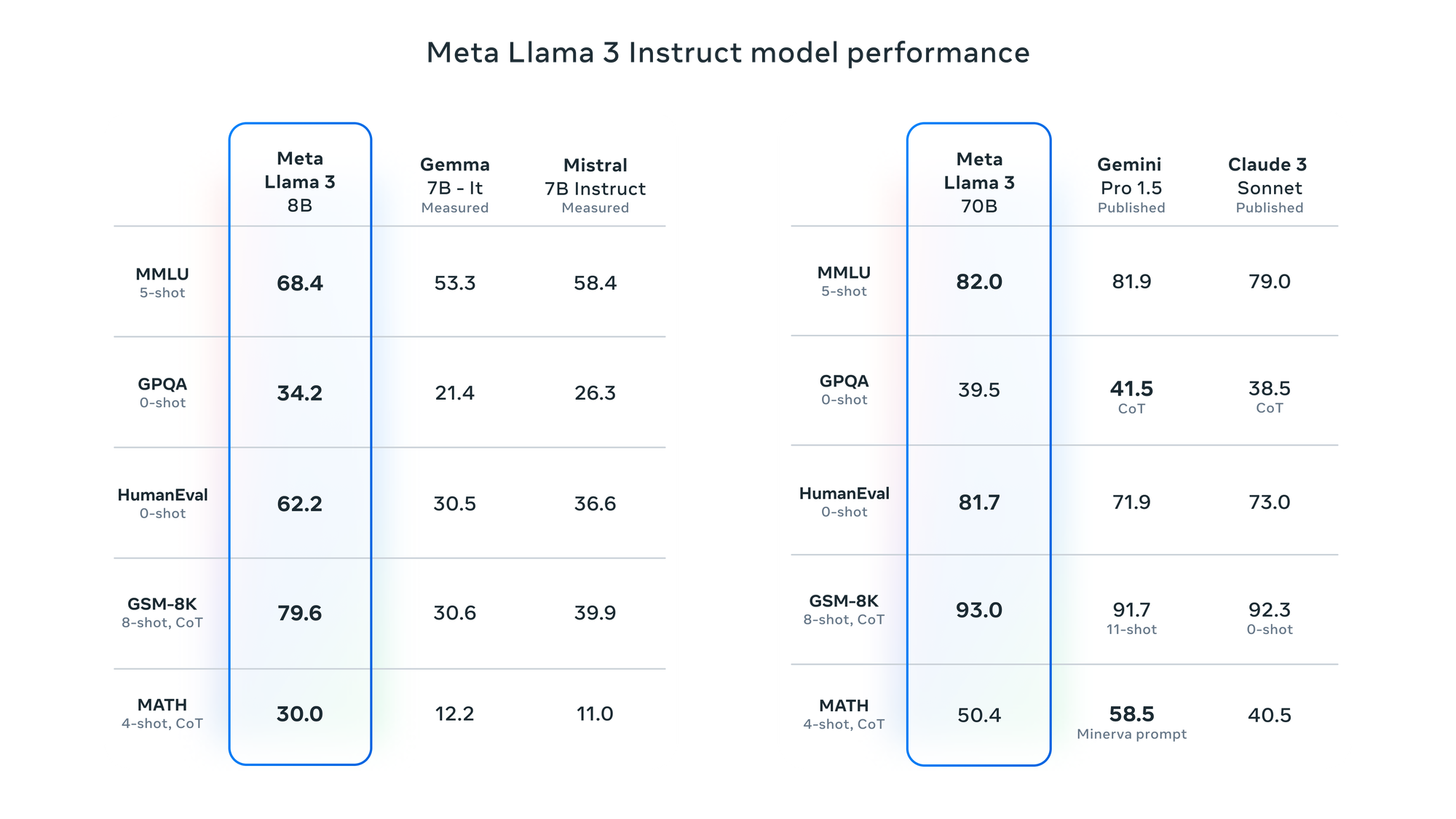
Llama 3 8B outperforms other open-source models with similar parameter counts, such as Mistral's Mistral 7B and Google's Gemma 7B, on nine benchmarks, including MMLU, ARC, DROP, and HumanEval. Llama 3 70B surpasses Claude 3 Sonnet and competes with Google's Gemini 1.5 Pro.
Meta says it is also currently training a 405B parameter dense model that will be released later this year. They also plan to release additional models with new capabilities including multimodality, more multilinguality, a much longer context window, and stronger overall capabilities.
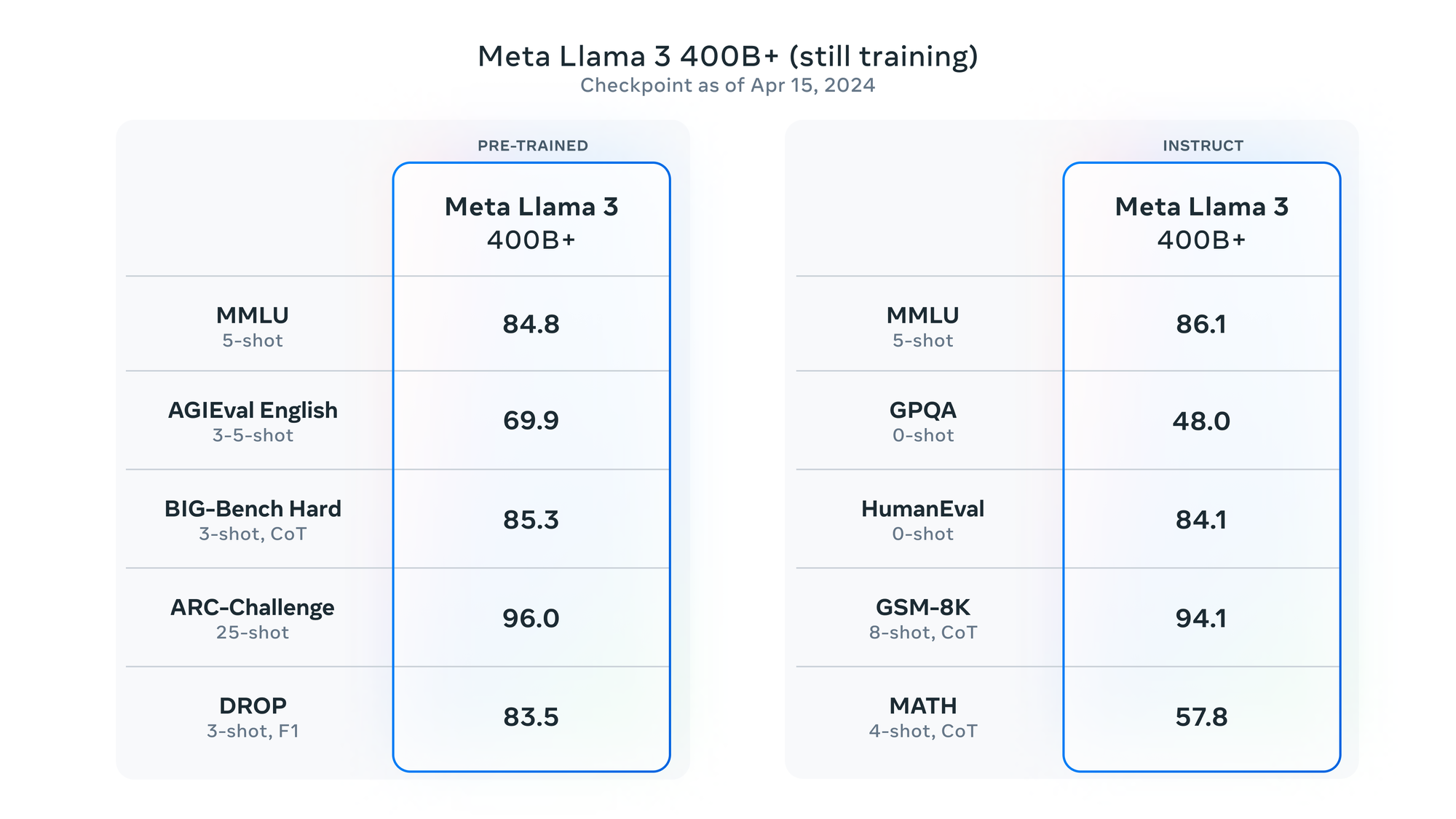
Underpinning these achievements are significant upgrades in model architecture and training processes. Meta has implemented a new tokenizer that increases token encoding efficiency, which, along with the adoption of grouped query attention (GQA), substantially enhances the models' processing speeds and inference efficiency.
Alongside the release of Llama 3, Meta has also introduced updated trust and safety tools for developers. Llama Guard 2, an improved version of their safeguard model, has been optimized to support the newly announced MLCommons AI Safety benchmark, expanding its coverage to a more comprehensive set of safety categories. The model demonstrates better classification performance than its predecessor and improved zero-shot and few-shot adaptability to custom policies.
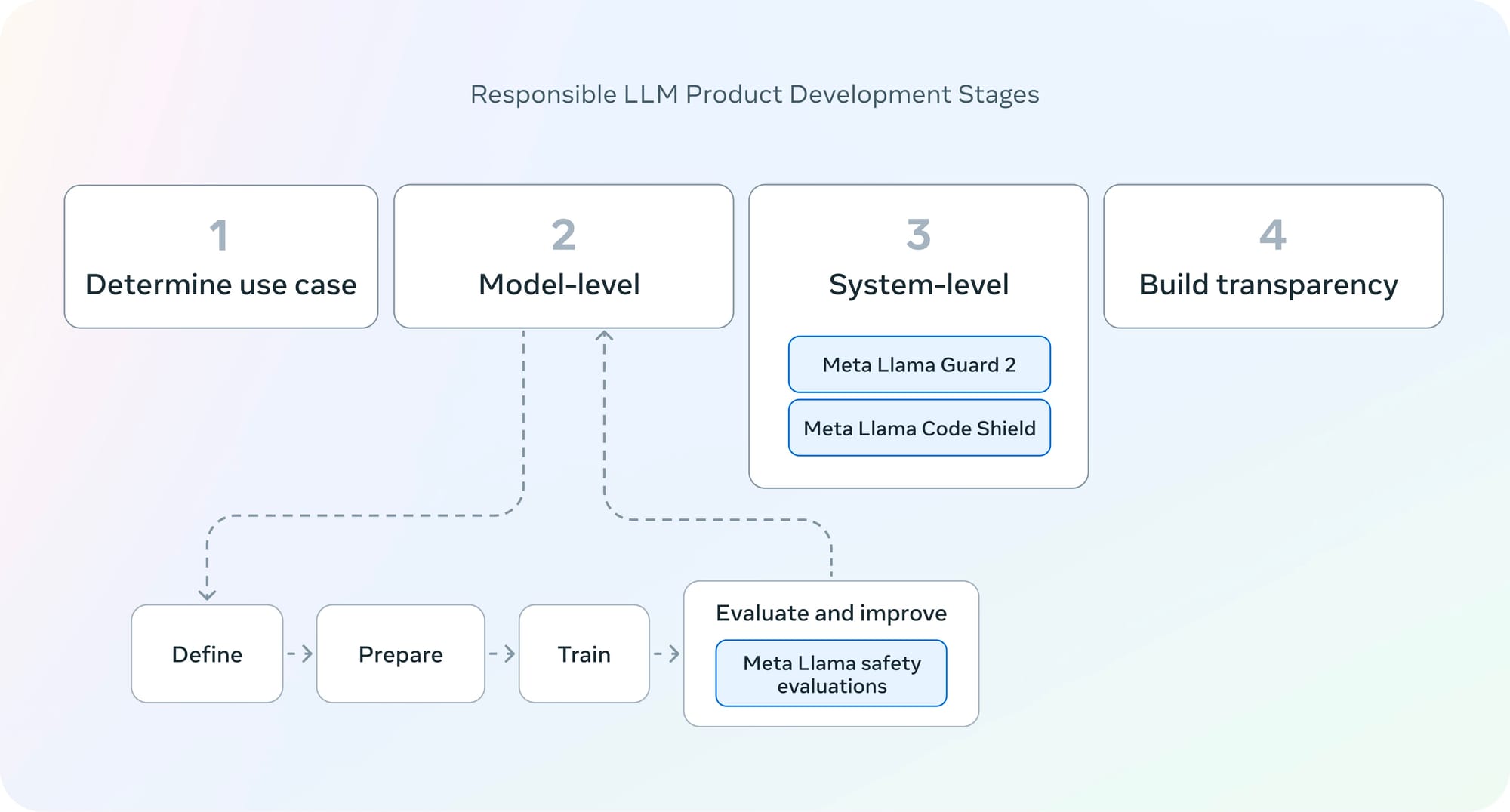
Cybersec Eval 2 is an updated benchmark to quantify LLM security risks and capabilities. It expands on its predecessor by measuring an LLM’s susceptibility to prompt injection, automated offensive cybersecurity capabilities, and propensity to abuse a code interpreter, in addition to the existing evaluations for insecure Coding Practices and Cyber Attack Helpfulness.
Finally, Code Shield is a new addition to the trust and safety toolkit, that adds support for inference-time filtering of insecure code produced by LLMs. This tool offers mitigation of risks associated with insecure code suggestions, code interpreter abuse prevention, and secure command execution. The company has also updated their Responsible Use Guide with best practices for developing with large language models.
With Llama 3, Meta not only continues to push the boundaries of what open-source AI models can achieve but also sets a new standard for responsible AI development and deployment in the industry. These models are already being rolled out on AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake.