

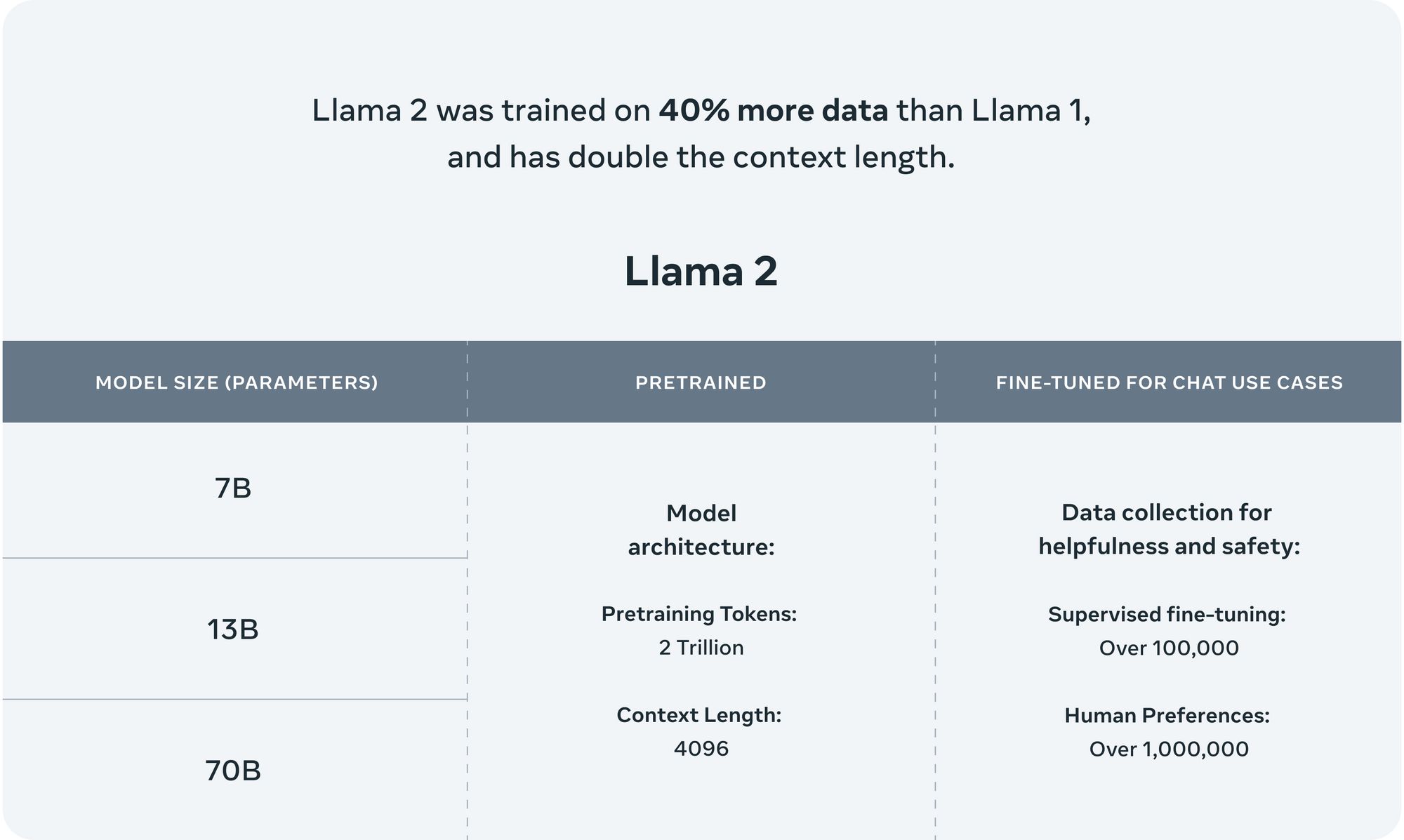
Meta has announced the release of LLaMA 2, a suite of cutting-edge, pre-trained and fine-tuned large language models (LLMs) that range in parameter size from 7 billion to a staggering 70 billion. LLaMA 2 is now freely available for both research and commercial applications, providing an unparalleled opportunity for developers worldwide.
At the heart of LLaMA 2 is LLaMA 2-Chat, a model fine-tuned and optimized for dialogue-centric applications. It brings to bear the formidable power of over 1 million human annotations, leveraging publicly available instructional datasets in the process. Llama-2-Chat outperform open-source chat models on most benchmarks tested, and in human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
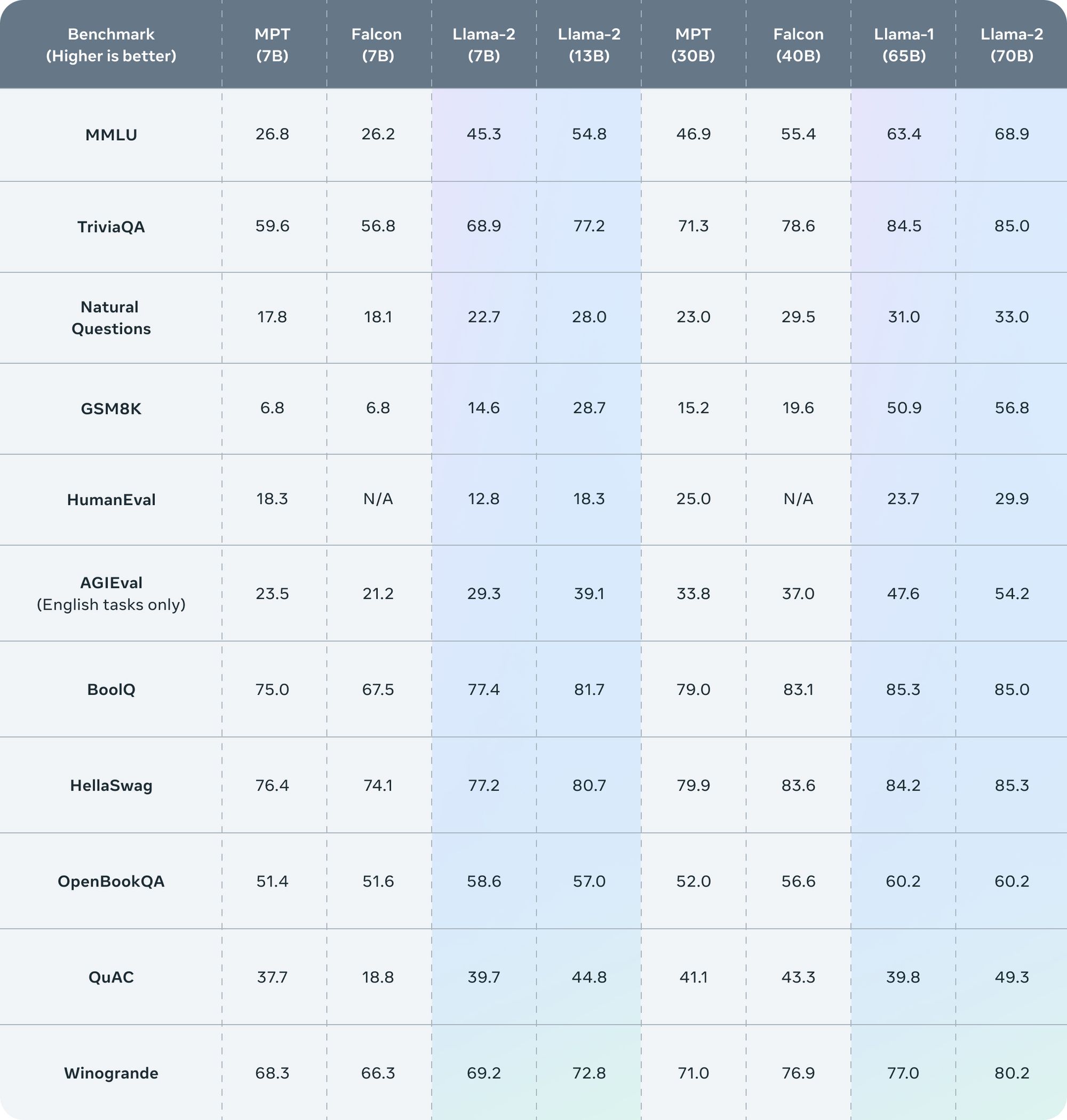
The training regimen for LLaMA 2 was rigorous and expansive, covering 2 trillion tokens and boasting twice the context length of its predecessor, LLaMA 1. This increased complexity and depth of training has paid off, with LLaMA 2 surpassing other open-source language models on several external benchmarks, including those focusing on reasoning, coding, proficiency, and knowledge.
Meta provides full documentation to support responsible development. With each model download they provide:
- Model code
- Model Weights
- README (User Guide)
- Responsible Use Guide
- License
- Acceptable Use Policy
- Model Card
Meta’s release of LLaMA 2 comes as part of a broader trend in the tech world of opening up AI resources to the public. With LLaMA 2 progressing the state of conversational AI, Meta strengthens its open source leadership. The models' thoughtful design and training reflect an emphasis on transparency and accountability. By sharing its work, Meta says it hopes to enable the community to advance AI for the common good.
 Meta AI
Meta AI