
Meta released new versions of its Llama 3.2 AI models today that run up to four times faster and achieve a 56% reduction in model size compared to their original counterparts. These breakthroughs make it possible to run powerful AI features directly on your phone without sacrificing performance.
The smaller 1-billion and 3-billion parameter models can now work on many popular mobile devices, achieving what was previously a difficult balance: maintaining high accuracy while dramatically reducing the technical requirements.
"We want to make it easier for developers to build with Llama without needing significant compute resources and expertise," Meta stated in its announcement. Testing on Android devices showed the new models are two to four times faster, while using 56% less storage space and 41% less memory.
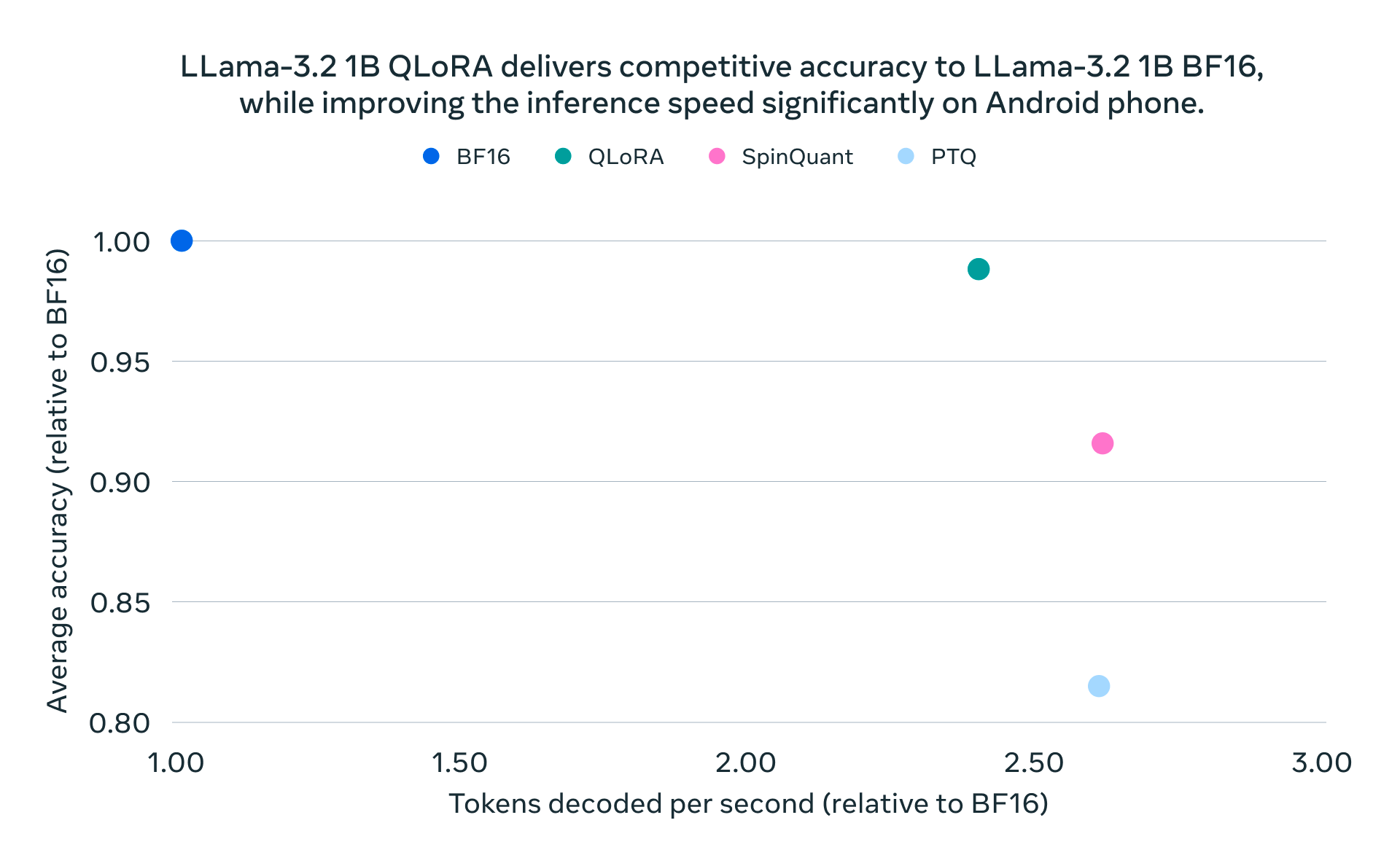
Meta's first-ever quantized Llama models have been designed for popular mobile platforms, a space where the demand for efficient on-device AI has grown sharply. The models utilize Quantization-Aware Training (QAT) with LoRA adaptors to minimize the negative effects of quantization on model accuracy. This method allows the model to retain high performance in low-precision environments—a crucial feature for running on less capable hardware.
The release also includes SpinQuant, a post-training quantization technique that is particularly useful when computational resources or training datasets are limited. While SpinQuant offers slightly lower accuracy compared to QAT, its portability makes it attractive for developers needing a flexible solution across different hardware targets. Both methods offer reduced memory and faster on-device inference while maintaining quality and safety standards, making it easier for developers to build AI solutions that keep data private by staying on-device.
The company worked closely with chip makers Qualcomm, MediaTek, and ARM to optimize these models for mobile processors. Besides CPUs, Meta is also working with partners to support Neural Processing Units, which could further enhance model performance on supported devices.
These developments matter because they allow AI features to run directly on your device instead of requiring a connection to remote servers. This approach can both improve privacy and reduce delays in AI responses.
The new quantized models are available now through Meta and Hugging Face. Developers can choose the version that best suits their needs – either optimizing for accuracy or for working across different types of devices.